 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Constraints for Consistent Self-supervised Monocular Depth and Ego-motion
Apr 18, 2023


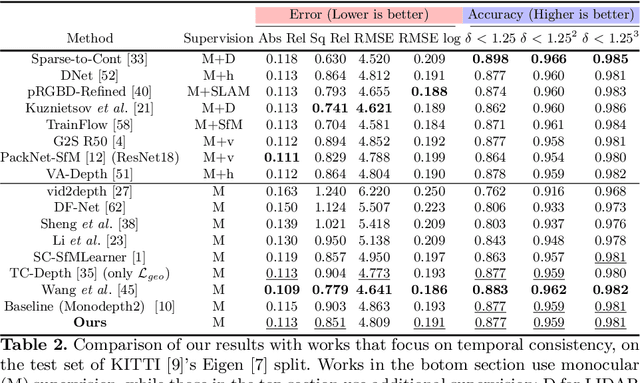
Self-supervised monocular depth estimation approaches suffer not only from scale ambiguity but also infer temporally inconsistent depth maps w.r.t. scale. While disambiguating scale during training is not possible without some kind of ground truth supervision, having scale consistent depth predictions would make it possible to calculate scale once during inference as a post-processing step and use it over-time. With this as a goal, a set of temporal consistency losses that minimize pose inconsistencies over time are introduced. Evaluations show that introducing these constraints not only reduces depth inconsistencies but also improves the baseline performance of depth and ego-motion prediction.
The Monocular Depth Estimation Challenge
Nov 22, 2022



This paper summarizes the results of the first Monocular Depth Estimation Challenge (MDEC) organized at WACV2023. This challenge evaluated the progress of self-supervised monocular depth estimation on the challenging SYNS-Patches dataset. The challenge was organized on CodaLab and received submissions from 4 valid teams. Participants were provided a devkit containing updated reference implementations for 16 State-of-the-Art algorithms and 4 novel techniques. The threshold for acceptance for novel techniques was to outperform every one of the 16 SotA baselines. All participants outperformed the baseline in traditional metrics such as MAE or AbsRel. However, pointcloud reconstruction metrics were challenging to improve upon. We found predictions were characterized by interpolation artefacts at object boundaries and errors in relative object positioning. We hope this challenge is a valuable contribution to the community and encourage authors to participate in future editions.
CamLessMonoDepth: Monocular Depth Estimation with Unknown Camera Parameters
Oct 27, 2021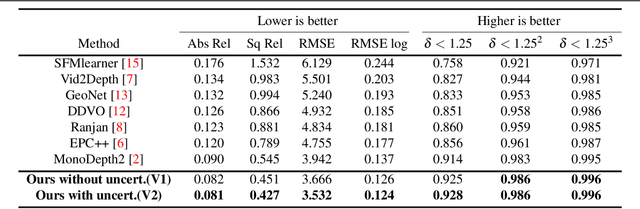

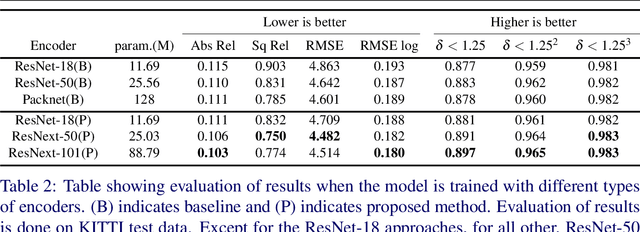
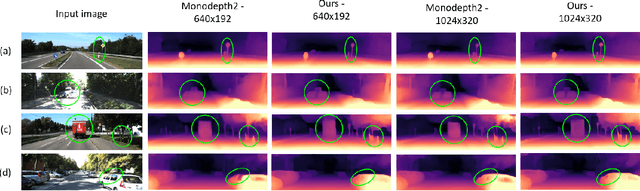
Perceiving 3D information is of paramount importance in many applications of computer vision. Recent advances in monocular depth estimation have shown that gaining such knowledge from a single camera input is possible by training deep neural networks to predict inverse depth and pose, without the necessity of ground truth data. The majority of such approaches, however, require camera parameters to be fed explicitly during training. As a result, image sequences from wild cannot be used during training. While there exist methods which also predict camera intrinsics, their performance is not on par with novel methods taking camera parameters as input. In this work, we propose a method for implicit estimation of pinhole camera intrinsics along with depth and pose, by learning from monocular image sequences alone. In addition, by utilizing efficient sub-pixel convolutions, we show that high fidelity depth estimates can be obtained. We also embed pixel-wise uncertainty estimation into the framework, to emphasize the possible applicability of this work in practical domain. Finally, we demonstrate the possibility of accurate prediction of depth information without prior knowledge of camera intrinsics, while outperforming the existing state-of-the-art approaches on KITTI benchmark.
MINA: Convex Mixed-Integer Programming for Non-Rigid Shape Alignment
Feb 28, 2020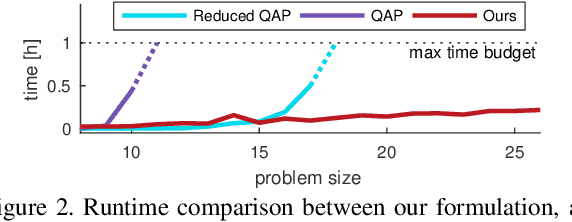



We present a convex mixed-integer programming formulation for non-rigid shape matching. To this end, we propose a novel shape deformation model based on an efficient low-dimensional discrete model, so that finding a globally optimal solution is tractable in (most) practical cases. Our approach combines several favourable properties: it is independent of the initialisation, it is much more efficient to solve to global optimality compared to analogous quadratic assignment problem formulations, and it is highly flexible in terms of the variants of matching problems it can handle. Experimentally we demonstrate that our approach outperforms existing methods for sparse shape matching, that it can be used for initialising dense shape matching methods, and we showcase its flexibility on several examples.