Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Constraints for Consistent Self-supervised Monocular Depth and Ego-motion
Paper and Code
Apr 18, 2023


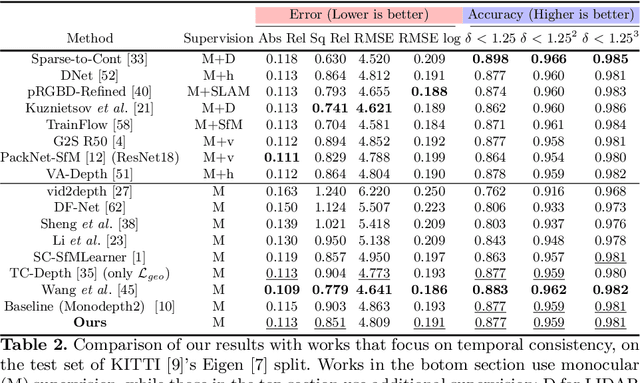
Self-supervised monocular depth estimation approaches suffer not only from scale ambiguity but also infer temporally inconsistent depth maps w.r.t. scale. While disambiguating scale during training is not possible without some kind of ground truth supervision, having scale consistent depth predictions would make it possible to calculate scale once during inference as a post-processing step and use it over-time. With this as a goal, a set of temporal consistency losses that minimize pose inconsistencies over time are introduced. Evaluations show that introducing these constraints not only reduces depth inconsistencies but also improves the baseline performance of depth and ego-motion prediction.
* Scandinavian Conference on Image Analysis (SCIA) 2023
View paper on