 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntime Safety Monitoring of Deep Neural Networks for Perception: A Survey
Nov 08, 2025Deep neural networks (DNNs) are widely used in perception systems for safety-critical applications, such as autonomous driving and robotics. However, DNNs remain vulnerable to various safety concerns, including generalization errors, out-of-distribution (OOD) inputs, and adversarial attacks, which can lead to hazardous failures. This survey provides a comprehensive overview of runtime safety monitoring approaches, which operate in parallel to DNNs during inference to detect these safety concerns without modifying the DNN itself. We categorize existing methods into three main groups: Monitoring inputs, internal representations, and outputs. We analyze the state-of-the-art for each category, identify strengths and limitations, and map methods to the safety concerns they address. In addition, we highlight open challenges and future research directions.
DEAP DIVE: Dataset Investigation with Vision transformers for EEG evaluation
Oct 01, 2025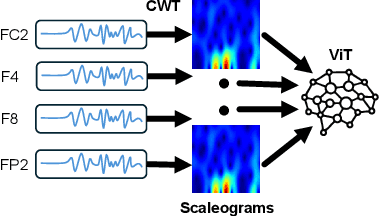
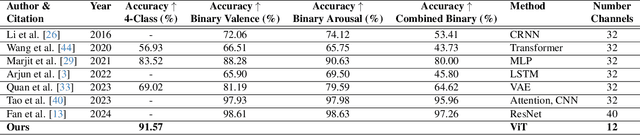


Accurately predicting emotions from brain signals has the potential to achieve goals such as improving mental health, human-computer interaction, and affective computing. Emotion prediction through neural signals offers a promising alternative to traditional methods, such as self-assessment and facial expression analysis, which can be subjective or ambiguous. Measurements of the brain activity via electroencephalogram (EEG) provides a more direct and unbiased data source. However, conducting a full EEG is a complex, resource-intensive process, leading to the rise of low-cost EEG devices with simplified measurement capabilities. This work examines how subsets of EEG channels from the DEAP dataset can be used for sufficiently accurate emotion prediction with low-cost EEG devices, rather than fully equipped EEG-measurements. Using Continuous Wavelet Transformation to convert EEG data into scaleograms, we trained a vision transformer (ViT) model for emotion classification. The model achieved over 91,57% accuracy in predicting 4 quadrants (high/low per arousal and valence) with only 12 measuring points (also referred to as channels). Our work shows clearly, that a significant reduction of input channels yields high results compared to state-of-the-art results of 96,9% with 32 channels. Training scripts to reproduce our code can be found here: https://gitlab.kit.edu/kit/aifb/ATKS/public/AutoSMiLeS/DEAP-DIVE.
Robust Experts: the Effect of Adversarial Training on CNNs with Sparse Mixture-of-Experts Layers
Sep 05, 2025Robustifying convolutional neural networks (CNNs) against adversarial attacks remains challenging and often requires resource-intensive countermeasures. We explore the use of sparse mixture-of-experts (MoE) layers to improve robustness by replacing selected residual blocks or convolutional layers, thereby increasing model capacity without additional inference cost. On ResNet architectures trained on CIFAR-100, we find that inserting a single MoE layer in the deeper stages leads to consistent improvements in robustness under PGD and AutoPGD attacks when combined with adversarial training. Furthermore, we discover that when switch loss is used for balancing, it causes routing to collapse onto a small set of overused experts, thereby concentrating adversarial training on these paths and inadvertently making them more robust. As a result, some individual experts outperform the gated MoE model in robustness, suggesting that robust subpaths emerge through specialization. Our code is available at https://github.com/KASTEL-MobilityLab/robust-sparse-moes.
Extracting Uncertainty Estimates from Mixtures of Experts for Semantic Segmentation
Sep 05, 2025Estimating accurate and well-calibrated predictive uncertainty is important for enhancing the reliability of computer vision models, especially in safety-critical applications like traffic scene perception. While ensemble methods are commonly used to quantify uncertainty by combining multiple models, a mixture of experts (MoE) offers an efficient alternative by leveraging a gating network to dynamically weight expert predictions based on the input. Building on the promising use of MoEs for semantic segmentation in our previous works, we show that well-calibrated predictive uncertainty estimates can be extracted from MoEs without architectural modifications. We investigate three methods to extract predictive uncertainty estimates: predictive entropy, mutual information, and expert variance. We evaluate these methods for an MoE with two experts trained on a semantical split of the A2D2 dataset. Our results show that MoEs yield more reliable uncertainty estimates than ensembles in terms of conditional correctness metrics under out-of-distribution (OOD) data. Additionally, we evaluate routing uncertainty computed via gate entropy and find that simple gating mechanisms lead to better calibration of routing uncertainty estimates than more complex classwise gates. Finally, our experiments on the Cityscapes dataset suggest that increasing the number of experts can further enhance uncertainty calibration. Our code is available at https://github.com/KASTEL-MobilityLab/mixtures-of-experts/.
Fool the Stoplight: Realistic Adversarial Patch Attacks on Traffic Light Detectors
Jun 05, 2025Realistic adversarial attacks on various camera-based perception tasks of autonomous vehicles have been successfully demonstrated so far. However, only a few works considered attacks on traffic light detectors. This work shows how CNNs for traffic light detection can be attacked with printed patches. We propose a threat model, where each instance of a traffic light is attacked with a patch placed under it, and describe a training strategy. We demonstrate successful adversarial patch attacks in universal settings. Our experiments show realistic targeted red-to-green label-flipping attacks and attacks on pictogram classification. Finally, we perform a real-world evaluation with printed patches and demonstrate attacks in the lab settings with a mobile traffic light for construction sites and in a test area with stationary traffic lights. Our code is available at https://github.com/KASTEL-MobilityLab/attacks-on-traffic-light-detection.
Towards Adversarial Robustness of Model-Level Mixture-of-Experts Architectures for Semantic Segmentation
Dec 16, 2024



Vulnerability to adversarial attacks is a well-known deficiency of deep neural networks. Larger networks are generally more robust, and ensembling is one method to increase adversarial robustness: each model's weaknesses are compensated by the strengths of others. While an ensemble uses a deterministic rule to combine model outputs, a mixture of experts (MoE) includes an additional learnable gating component that predicts weights for the outputs of the expert models, thus determining their contributions to the final prediction. MoEs have been shown to outperform ensembles on specific tasks, yet their susceptibility to adversarial attacks has not been studied yet. In this work, we evaluate the adversarial vulnerability of MoEs for semantic segmentation of urban and highway traffic scenes. We show that MoEs are, in most cases, more robust to per-instance and universal white-box adversarial attacks and can better withstand transfer attacks. Our code is available at \url{https://github.com/KASTEL-MobilityLab/mixtures-of-experts/}.
Evaluating Adversarial Attacks on Traffic Sign Classifiers beyond Standard Baselines
Dec 12, 2024



Adversarial attacks on traffic sign classification models were among the first successfully tried in the real world. Since then, the research in this area has been mainly restricted to repeating baseline models, such as LISA-CNN or GTSRB-CNN, and similar experiment settings, including white and black patches on traffic signs. In this work, we decouple model architectures from the datasets and evaluate on further generic models to make a fair comparison. Furthermore, we compare two attack settings, inconspicuous and visible, which are usually regarded without direct comparison. Our results show that standard baselines like LISA-CNN or GTSRB-CNN are significantly more susceptible than the generic ones. We, therefore, suggest evaluating new attacks on a broader spectrum of baselines in the future. Our code is available at \url{https://github.com/KASTEL-MobilityLab/attacks-on-traffic-sign-recognition/}.
TLD-READY: Traffic Light Detection -- Relevance Estimation and Deployment Analysis
Sep 11, 2024Effective traffic light detection is a critical component of the perception stack in autonomous vehicles. This work introduces a novel deep-learning detection system while addressing the challenges of previous work. Utilizing a comprehensive dataset amalgamation, including the Bosch Small Traffic Lights Dataset, LISA, the DriveU Traffic Light Dataset, and a proprietary dataset from Karlsruhe, we ensure a robust evaluation across varied scenarios. Furthermore, we propose a relevance estimation system that innovatively uses directional arrow markings on the road, eliminating the need for prior map creation. On the DriveU dataset, this approach results in 96% accuracy in relevance estimation. Finally, a real-world evaluation is performed to evaluate the deployment and generalizing abilities of these models. For reproducibility and to facilitate further research, we provide the model weights and code: https://github.com/KASTEL-MobilityLab/traffic-light-detection.
Efficient Edge AI: Deploying Convolutional Neural Networks on FPGA with the Gemmini Accelerator
Aug 14, 2024The growing concerns regarding energy consumption and privacy have prompted the development of AI solutions deployable on the edge, circumventing the substantial CO2 emissions associated with cloud servers and mitigating risks related to sharing sensitive data. But deploying Convolutional Neural Networks (CNNs) on non-off-the-shelf edge devices remains a complex and labor-intensive task. In this paper, we present and end-to-end workflow for deployment of CNNs on Field Programmable Gate Arrays (FPGAs) using the Gemmini accelerator, which we modified for efficient implementation on FPGAs. We describe how we leverage the use of open source software on each optimization step of the deployment process, the customizations we added to them and its impact on the final system's performance. We were able to achieve real-time performance by deploying a YOLOv7 model on a Xilinx ZCU102 FPGA with an energy efficiency of 36.5 GOP/s/W. Our FPGA-based solution demonstrates superior power efficiency compared with other embedded hardware devices, and even outperforms other FPGA reference implementations. Finally, we present how this kind of solution can be integrated into a wider system, by testing our proposed platform in a traffic monitoring scenario.
Complementary Learning for Real-World Model Failure Detection
Jul 19, 2024In real-world autonomous driving, deep learning models can experience performance degradation due to distributional shifts between the training data and the driving conditions encountered. As is typical in machine learning, it is difficult to acquire a large and potentially representative labeled test set to validate models in preparation for deployment in the wild. In this work, we introduce complementary learning, where we use learned characteristics from different training paradigms to detect model errors. We demonstrate our approach by learning semantic and predictive motion labels in point clouds in a supervised and self-supervised manner and detect and classify model discrepancies subsequently. We perform a large-scale qualitative analysis and present LidarCODA, the first dataset with labeled anomalies in lidar point clouds, for an extensive quantitative analysis.