 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Challenges in Retrieval-Augmented Generation
Oct 01, 2025Organizations increasingly adopt Retrieval-Augmented Generation (RAG) to enhance Large Language Models with enterprise-specific knowledge. However, current data quality (DQ) frameworks have been primarily developed for static datasets, and only inadequately address the dynamic, multi-stage nature of RAG systems. This study aims to develop DQ dimensions for this new type of AI-based systems. We conduct 16 semi-structured interviews with practitioners of leading IT service companies. Through a qualitative content analysis, we inductively derive 15 distinct DQ dimensions across the four processing stages of RAG systems: data extraction, data transformation, prompt & search, and generation. Our findings reveal that (1) new dimensions have to be added to traditional DQ frameworks to also cover RAG contexts; (2) these new dimensions are concentrated in early RAG steps, suggesting the need for front-loaded quality management strategies, and (3) DQ issues transform and propagate through the RAG pipeline, necessitating a dynamic, step-aware approach to quality management.
PromptPilot: Improving Human-AI Collaboration Through LLM-Enhanced Prompt Engineering
Oct 01, 2025Effective prompt engineering is critical to realizing the promised productivity gains of large language models (LLMs) in knowledge-intensive tasks. Yet, many users struggle to craft prompts that yield high-quality outputs, limiting the practical benefits of LLMs. Existing approaches, such as prompt handbooks or automated optimization pipelines, either require substantial effort, expert knowledge, or lack interactive guidance. To address this gap, we design and evaluate PromptPilot, an interactive prompting assistant grounded in four empirically derived design objectives for LLM-enhanced prompt engineering. We conducted a randomized controlled experiment with 80 participants completing three realistic, work-related writing tasks. Participants supported by PromptPilot achieved significantly higher performance (median: 78.3 vs. 61.7; p = .045, d = 0.56), and reported enhanced efficiency, ease-of-use, and autonomy during interaction. These findings empirically validate the effectiveness of our proposed design objectives, establishing LLM-enhanced prompt engineering as a viable technique for improving human-AI collaboration.
Evaluating Adversarial Attacks on Traffic Sign Classifiers beyond Standard Baselines
Dec 12, 2024



Adversarial attacks on traffic sign classification models were among the first successfully tried in the real world. Since then, the research in this area has been mainly restricted to repeating baseline models, such as LISA-CNN or GTSRB-CNN, and similar experiment settings, including white and black patches on traffic signs. In this work, we decouple model architectures from the datasets and evaluate on further generic models to make a fair comparison. Furthermore, we compare two attack settings, inconspicuous and visible, which are usually regarded without direct comparison. Our results show that standard baselines like LISA-CNN or GTSRB-CNN are significantly more susceptible than the generic ones. We, therefore, suggest evaluating new attacks on a broader spectrum of baselines in the future. Our code is available at \url{https://github.com/KASTEL-MobilityLab/attacks-on-traffic-sign-recognition/}.
Utilizing Data Fingerprints for Privacy-Preserving Algorithm Selection in Time Series Classification: Performance and Uncertainty Estimation on Unseen Datasets
Sep 13, 2024



The selection of algorithms is a crucial step in designing AI services for real-world time series classification use cases. Traditional methods such as neural architecture search, automated machine learning, combined algorithm selection, and hyperparameter optimizations are effective but require considerable computational resources and necessitate access to all data points to run their optimizations. In this work, we introduce a novel data fingerprint that describes any time series classification dataset in a privacy-preserving manner and provides insight into the algorithm selection problem without requiring training on the (unseen) dataset. By decomposing the multi-target regression problem, only our data fingerprints are used to estimate algorithm performance and uncertainty in a scalable and adaptable manner. Our approach is evaluated on the 112 University of California riverside benchmark datasets, demonstrating its effectiveness in predicting the performance of 35 state-of-the-art algorithms and providing valuable insights for effective algorithm selection in time series classification service systems, improving a naive baseline by 7.32% on average in estimating the mean performance and 15.81% in estimating the uncertainty.
Navigating the Synthetic Realm: Harnessing Diffusion-based Models for Laparoscopic Text-to-Image Generation
Dec 05, 2023Recent advances in synthetic imaging open up opportunities for obtaining additional data in the field of surgical imaging. This data can provide reliable supplements supporting surgical applications and decision-making through computer vision. Particularly the field of image-guided surgery, such as laparoscopic and robotic-assisted surgery, benefits strongly from synthetic image datasets and virtual surgical training methods. Our study presents an intuitive approach for generating synthetic laparoscopic images from short text prompts using diffusion-based generative models. We demonstrate the usage of state-of-the-art text-to-image architectures in the context of laparoscopic imaging with regard to the surgical removal of the gallbladder as an example. Results on fidelity and diversity demonstrate that diffusion-based models can acquire knowledge about the style and semantics in the field of image-guided surgery. A validation study with a human assessment survey underlines the realistic nature of our synthetic data, as medical personnel detects actual images in a pool with generated images causing a false-positive rate of 66%. In addition, the investigation of a state-of-the-art machine learning model to recognize surgical actions indicates enhanced results when trained with additional generated images of up to 5.20%. Overall, the achieved image quality contributes to the usage of computer-generated images in surgical applications and enhances its path to maturity.
Redefining the Laparoscopic Spatial Sense: AI-based Intra- and Postoperative Measurement from Stereoimages
Nov 16, 2023A significant challenge in image-guided surgery is the accurate measurement task of relevant structures such as vessel segments, resection margins, or bowel lengths. While this task is an essential component of many surgeries, it involves substantial human effort and is prone to inaccuracies. In this paper, we develop a novel human-AI-based method for laparoscopic measurements utilizing stereo vision that has been guided by practicing surgeons. Based on a holistic qualitative requirements analysis, this work proposes a comprehensive measurement method, which comprises state-of-the-art machine learning architectures, such as RAFT-Stereo and YOLOv8. The developed method is assessed in various realistic experimental evaluation environments. Our results outline the potential of our method achieving high accuracies in distance measurements with errors below 1 mm. Furthermore, on-surface measurements demonstrate robustness when applied in challenging environments with textureless regions. Overall, by addressing the inherent challenges of image-guided surgery, we lay the foundation for a more robust and accurate solution for intra- and postoperative measurements, enabling more precise, safe, and efficient surgical procedures.
Suppress with a Patch: Revisiting Universal Adversarial Patch Attacks against Object Detection
Sep 27, 2022



Adversarial patch-based attacks aim to fool a neural network with an intentionally generated noise, which is concentrated in a particular region of an input image. In this work, we perform an in-depth analysis of different patch generation parameters, including initialization, patch size, and especially positioning a patch in an image during training. We focus on the object vanishing attack and run experiments with YOLOv3 as a model under attack in a white-box setting and use images from the COCO dataset. Our experiments have shown, that inserting a patch inside a window of increasing size during training leads to a significant increase in attack strength compared to a fixed position. The best results were obtained when a patch was positioned randomly during training, while patch position additionally varied within a batch.
Provident Vehicle Detection at Night: The PVDN Dataset
Jan 23, 2021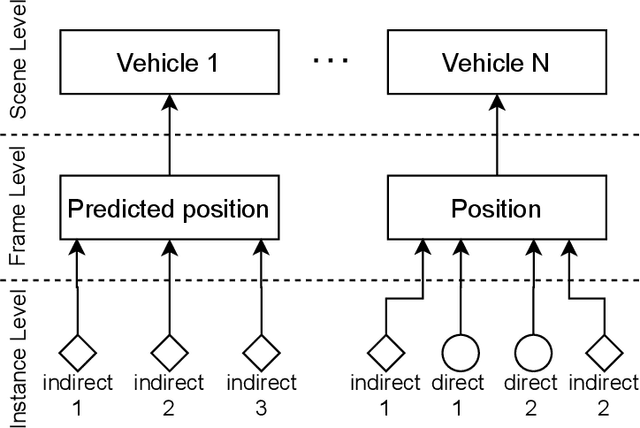
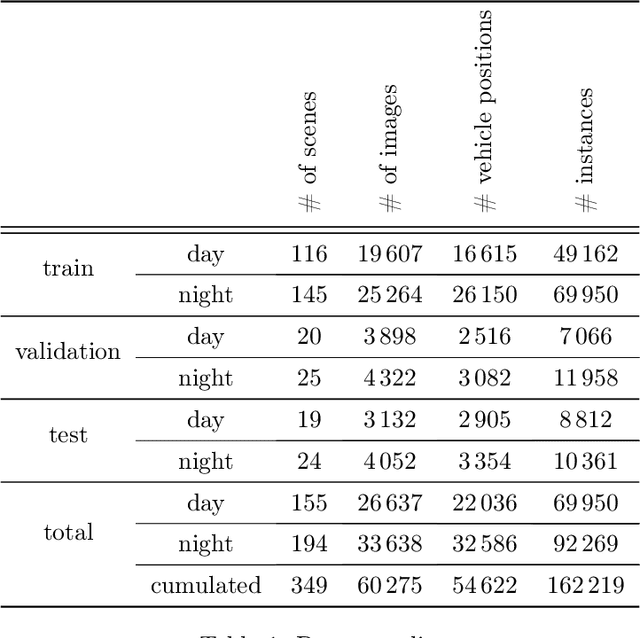

For advanced driver assistance systems, it is crucial to have information about oncoming vehicles as early as possible. At night, this task is especially difficult due to poor lighting conditions. For that, during nighttime, every vehicle uses headlamps to improve sight and therefore ensure safe driving. As humans, we intuitively assume oncoming vehicles before the vehicles are actually physically visible by detecting light reflections caused by their headlamps. In this paper, we present a novel dataset containing 59746 annotated grayscale images out of 346 different scenes in a rural environment at night. In these images, all oncoming vehicles, their corresponding light objects (e.g., headlamps), and their respective light reflections (e.g., light reflections on guardrails) are labeled. This is accompanied by an in-depth analysis of the dataset characteristics. With that, we are providing the first open-source dataset with comprehensive ground truth data to enable research into new methods of detecting oncoming vehicles based on the light reflections they cause, long before they are directly visible. We consider this as an essential step to further close the performance gap between current advanced driver assistance systems and human behavior.