 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Overfitting in Convolutional Neural Networks using Adversarial Perturbations and Label Noise
Sep 27, 2022
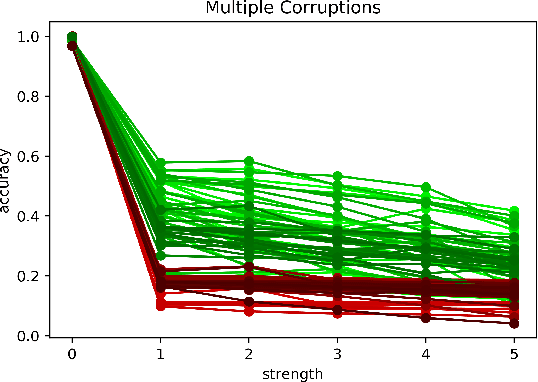
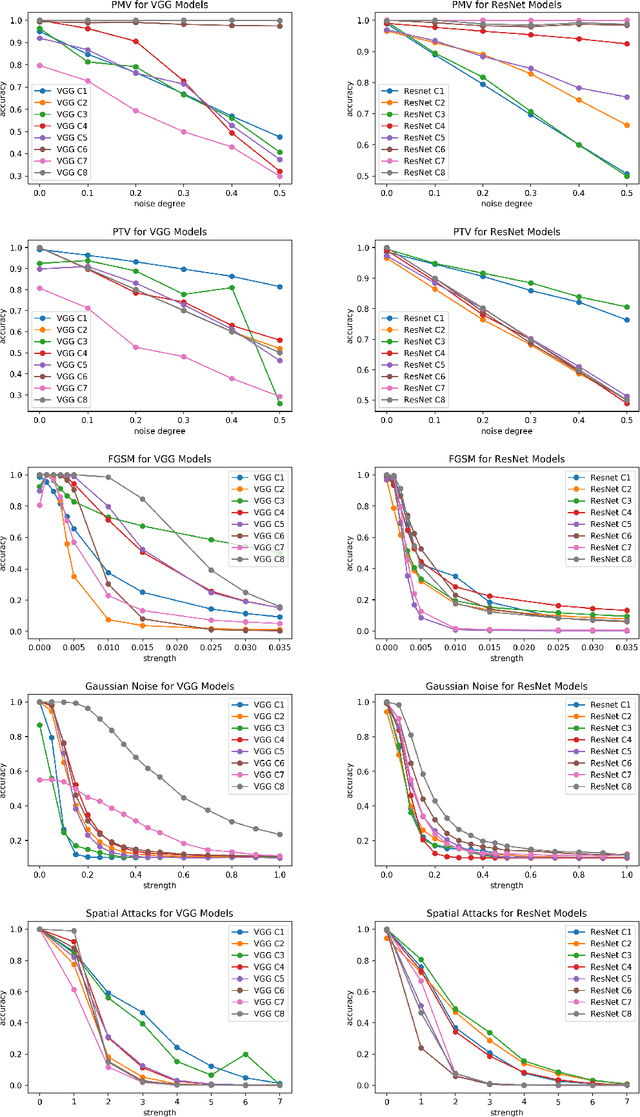

Although numerous methods to reduce the overfitting of convolutional neural networks (CNNs) exist, it is still not clear how to confidently measure the degree of overfitting. A metric reflecting the overfitting level might be, however, extremely helpful for the comparison of different architectures and for the evaluation of various techniques to tackle overfitting. Motivated by the fact that overfitted neural networks tend to rather memorize noise in the training data than generalize to unseen data, we examine how the training accuracy changes in the presence of increasing data perturbations and study the connection to overfitting. While previous work focused on label noise only, we examine a spectrum of techniques to inject noise into the training data, including adversarial perturbations and input corruptions. Based on this, we define two new metrics that can confidently distinguish between correct and overfitted models. For the evaluation, we derive a pool of models for which the overfitting behavior is known beforehand. To test the effect of various factors, we introduce several anti-overfitting measures in architectures based on VGG and ResNet and study their impact, including regularization techniques, training set size, and the number of parameters. Finally, we assess the applicability of the proposed metrics by measuring the overfitting degree of several CNN architectures outside of our model pool.
Suppress with a Patch: Revisiting Universal Adversarial Patch Attacks against Object Detection
Sep 27, 2022



Adversarial patch-based attacks aim to fool a neural network with an intentionally generated noise, which is concentrated in a particular region of an input image. In this work, we perform an in-depth analysis of different patch generation parameters, including initialization, patch size, and especially positioning a patch in an image during training. We focus on the object vanishing attack and run experiments with YOLOv3 as a model under attack in a white-box setting and use images from the COCO dataset. Our experiments have shown, that inserting a patch inside a window of increasing size during training leads to a significant increase in attack strength compared to a fixed position. The best results were obtained when a patch was positioned randomly during training, while patch position additionally varied within a batch.
Adversarial Vulnerability of Temporal Feature Networks for Object Detection
Aug 23, 2022


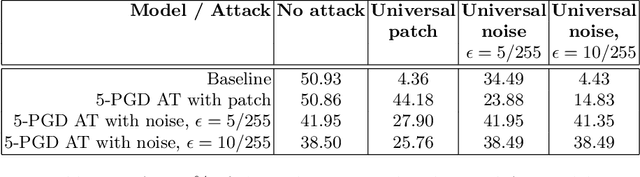
Taking into account information across the temporal domain helps to improve environment perception in autonomous driving. However, it has not been studied so far whether temporally fused neural networks are vulnerable to deliberately generated perturbations, i.e. adversarial attacks, or whether temporal history is an inherent defense against them. In this work, we study whether temporal feature networks for object detection are vulnerable to universal adversarial attacks. We evaluate attacks of two types: imperceptible noise for the whole image and locally-bound adversarial patch. In both cases, perturbations are generated in a white-box manner using PGD. Our experiments confirm, that attacking even a portion of a temporal input suffices to fool the network. We visually assess generated perturbations to gain insights into the functioning of attacks. To enhance the robustness, we apply adversarial training using 5-PGD. Our experiments on KITTI and nuScenes datasets demonstrate, that a model robustified via K-PGD is able to withstand the studied attacks while keeping the mAP-based performance comparable to that of an unattacked model.
Feasibility of Inconspicuous GAN-generated Adversarial Patches against Object Detection
Jul 15, 2022

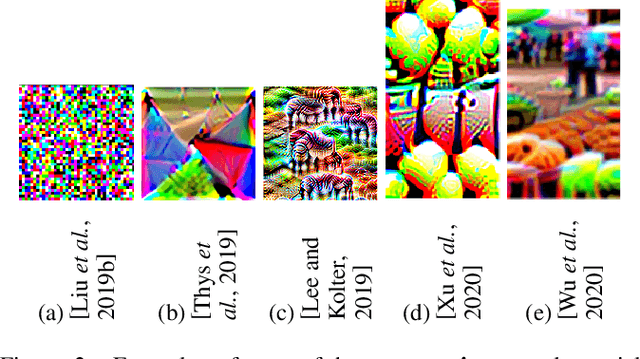

Standard approaches for adversarial patch generation lead to noisy conspicuous patterns, which are easily recognizable by humans. Recent research has proposed several approaches to generate naturalistic patches using generative adversarial networks (GANs), yet only a few of them were evaluated on the object detection use case. Moreover, the state of the art mostly focuses on suppressing a single large bounding box in input by overlapping it with the patch directly. Suppressing objects near the patch is a different, more complex task. In this work, we have evaluated the existing approaches to generate inconspicuous patches. We have adapted methods, originally developed for different computer vision tasks, to the object detection use case with YOLOv3 and the COCO dataset. We have evaluated two approaches to generate naturalistic patches: by incorporating patch generation into the GAN training process and by using the pretrained GAN. For both cases, we have assessed a trade-off between performance and naturalistic patch appearance. Our experiments have shown, that using a pre-trained GAN helps to gain realistic-looking patches while preserving the performance similar to conventional adversarial patches.
Balancing Expert Utilization in Mixture-of-Experts Layers Embedded in CNNs
Apr 22, 2022
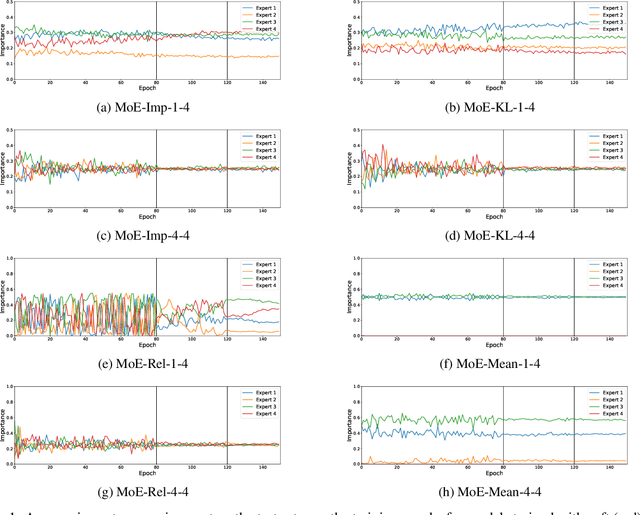


This work addresses the problem of unbalanced expert utilization in sparsely-gated Mixture of Expert (MoE) layers, embedded directly into convolutional neural networks. To enable a stable training process, we present both soft and hard constraint-based approaches. With hard constraints, the weights of certain experts are allowed to become zero, while soft constraints balance the contribution of experts with an additional auxiliary loss. As a result, soft constraints handle expert utilization better and support the expert specialization process, hard constraints mostly maintain generalized experts and increase the model performance for many applications. Our findings demonstrate that even with a single dataset and end-to-end training, experts can implicitly focus on individual sub-domains of the input space. Experts in the proposed models with MoE embeddings implicitly focus on distinct domains, even without suitable predefined datasets. As an example, experts trained for CIFAR-100 image classification specialize in recognizing different domains such as sea animals or flowers without previous data clustering. Experiments with RetinaNet and the COCO dataset further indicate that object detection experts can also specialize in detecting objects of distinct sizes.
Is Neuron Coverage Needed to Make Person Detection More Robust?
Apr 21, 2022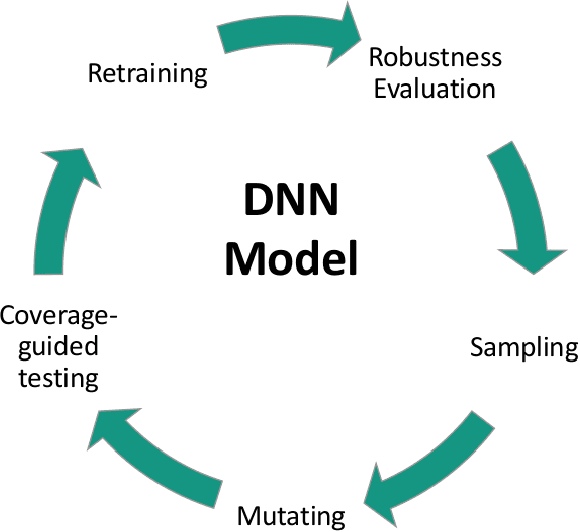



The growing use of deep neural networks (DNNs) in safety- and security-critical areas like autonomous driving raises the need for their systematic testing. Coverage-guided testing (CGT) is an approach that applies mutation or fuzzing according to a predefined coverage metric to find inputs that cause misbehavior. With the introduction of a neuron coverage metric, CGT has also recently been applied to DNNs. In this work, we apply CGT to the task of person detection in crowded scenes. The proposed pipeline uses YOLOv3 for person detection and includes finding DNN bugs via sampling and mutation, and subsequent DNN retraining on the updated training set. To be a bug, we require a mutated image to cause a significant performance drop compared to a clean input. In accordance with the CGT, we also consider an additional requirement of increased coverage in the bug definition. In order to explore several types of robustness, our approach includes natural image transformations, corruptions, and adversarial examples generated with the Daedalus attack. The proposed framework has uncovered several thousand cases of incorrect DNN behavior. The relative change in mAP performance of the retrained models reached on average between 26.21\% and 64.24\% for different robustness types. However, we have found no evidence that the investigated coverage metrics can be advantageously used to improve robustness.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.