 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI-derived quantification of hepatic vessel-to-volume ratios in chronic liver disease using a deep learning approach
Oct 09, 2025Background: We aimed to quantify hepatic vessel volumes across chronic liver disease stages and healthy controls using deep learning-based magnetic resonance imaging (MRI) analysis, and assess correlations with biomarkers for liver (dys)function and fibrosis/portal hypertension. Methods: We assessed retrospectively healthy controls, non-advanced and advanced chronic liver disease (ACLD) patients using a 3D U-Net model for hepatic vessel segmentation on portal venous phase gadoxetic acid-enhanced 3-T MRI. Total (TVVR), hepatic (HVVR), and intrahepatic portal vein-to-volume ratios (PVVR) were compared between groups and correlated with: albumin-bilirubin (ALBI) and model for end-stage liver disease-sodium (MELD-Na) score, and fibrosis/portal hypertension (Fibrosis-4 [FIB-4] score, liver stiffness measurement [LSM], hepatic venous pressure gradient [HVPG], platelet count [PLT], and spleen volume). Results: We included 197 subjects, aged 54.9 $\pm$ 13.8 years (mean $\pm$ standard deviation), 111 males (56.3\%): 35 healthy controls, 44 non-ACLD, and 118 ACLD patients. TVVR and HVVR were highest in controls (3.9; 2.1), intermediate in non-ACLD (2.8; 1.7), and lowest in ACLD patients (2.3; 1.0) ($p \leq 0.001$). PVVR was reduced in both non-ACLD and ACLD patients (both 1.2) compared to controls (1.7) ($p \leq 0.001$), but showed no difference between CLD groups ($p = 0.999$). HVVR significantly correlated indirectly with FIB-4, ALBI, MELD-Na, LSM, and spleen volume ($\rho$ ranging from -0.27 to -0.40), and directly with PLT ($\rho = 0.36$). TVVR and PVVR showed similar but weaker correlations. Conclusions: Deep learning-based hepatic vessel volumetry demonstrated differences between healthy liver and chronic liver disease stages and shows correlations with established markers of disease severity.
Harnessing Generative AI for Economic Insights
Oct 04, 2024



We use generative AI to extract managerial expectations about their economic outlook from over 120,000 corporate conference call transcripts. The overall measure, AI Economy Score, robustly predicts future economic indicators such as GDP growth, production, and employment, both in the short term and to 10 quarters. This predictive power is incremental to that of existing measures, including survey forecasts. Moreover, industry and firm-level measures provide valuable information about sector-specific and individual firm activities. Our findings suggest that managerial expectations carry unique insights about economic activities, with implications for both macroeconomic and microeconomic decision-making.
Interpretable Anomaly Detection in Cellular Networks by Learning Concepts in Variational Autoencoders
Jun 28, 2023This paper addresses the challenges of detecting anomalies in cellular networks in an interpretable way and proposes a new approach using variational autoencoders (VAEs) that learn interpretable representations of the latent space for each Key Performance Indicator (KPI) in the dataset. This enables the detection of anomalies based on reconstruction loss and Z-scores. We ensure the interpretability of the anomalies via additional information centroids (c) using the K-means algorithm to enhance representation learning. We evaluate the performance of the model by analyzing patterns in the latent dimension for specific KPIs and thereby demonstrate the interpretability and anomalies. The proposed framework offers a faster and autonomous solution for detecting anomalies in cellular networks and showcases the potential of deep learning-based algorithms in handling big data.
Adversarial Vulnerability of Temporal Feature Networks for Object Detection
Aug 23, 2022


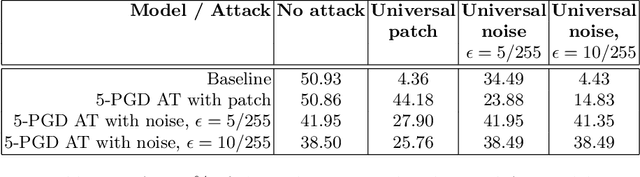
Taking into account information across the temporal domain helps to improve environment perception in autonomous driving. However, it has not been studied so far whether temporally fused neural networks are vulnerable to deliberately generated perturbations, i.e. adversarial attacks, or whether temporal history is an inherent defense against them. In this work, we study whether temporal feature networks for object detection are vulnerable to universal adversarial attacks. We evaluate attacks of two types: imperceptible noise for the whole image and locally-bound adversarial patch. In both cases, perturbations are generated in a white-box manner using PGD. Our experiments confirm, that attacking even a portion of a temporal input suffices to fool the network. We visually assess generated perturbations to gain insights into the functioning of attacks. To enhance the robustness, we apply adversarial training using 5-PGD. Our experiments on KITTI and nuScenes datasets demonstrate, that a model robustified via K-PGD is able to withstand the studied attacks while keeping the mAP-based performance comparable to that of an unattacked model.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Temporal Feature Networks for CNN based Object Detection
Mar 22, 2021
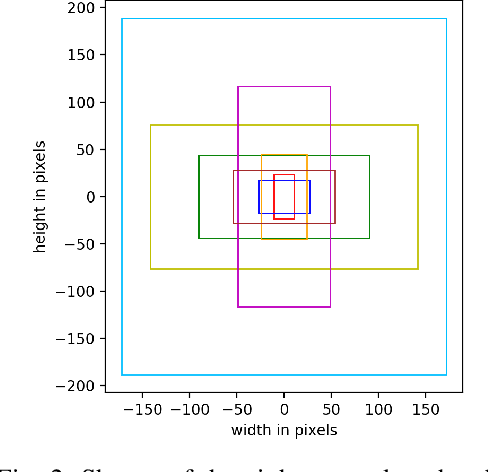
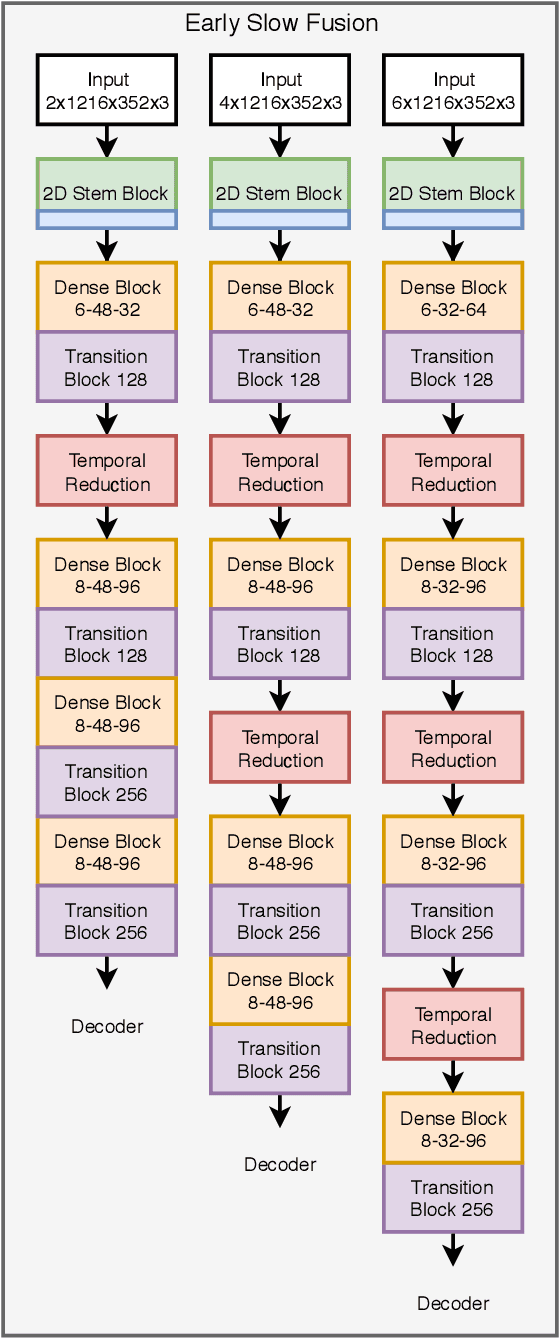
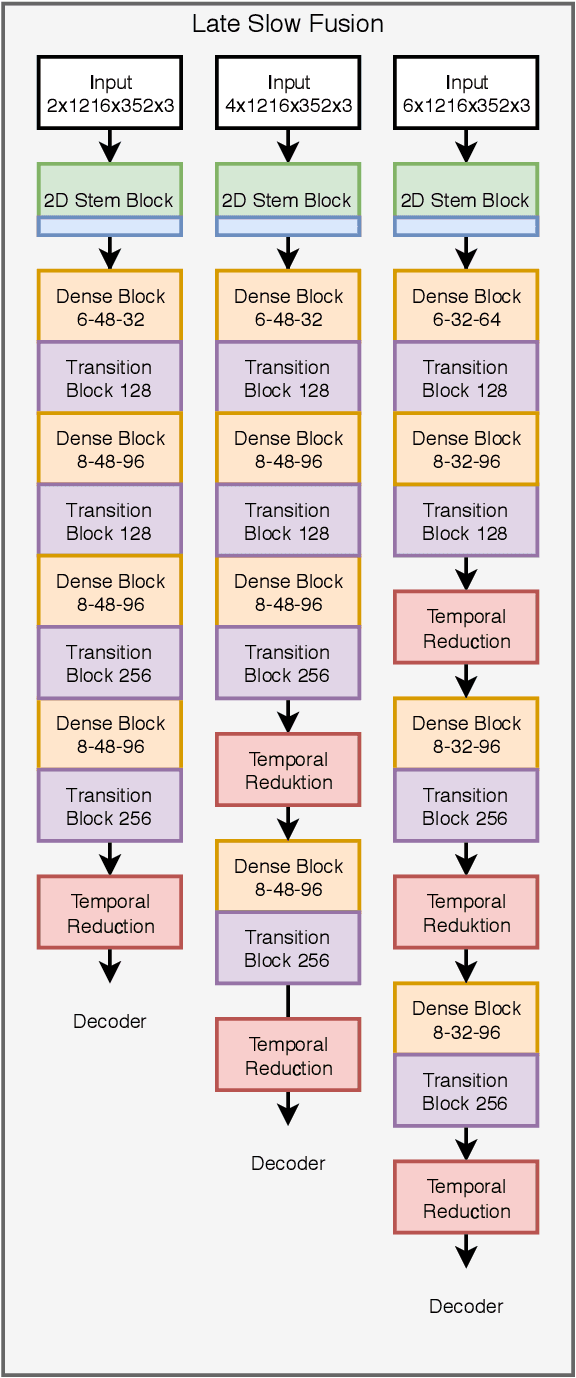
For reliable environment perception, the use of temporal information is essential in some situations. Especially for object detection, sometimes a situation can only be understood in the right perspective through temporal information. Since image-based object detectors are currently based almost exclusively on CNN architectures, an extension of their feature extraction with temporal features seems promising. Within this work we investigate different architectural components for a CNN-based temporal information extraction. We present a Temporal Feature Network which is based on the insights gained from our architectural investigations. This network is trained from scratch without any ImageNet information based pre-training as these images are not available with temporal information. The object detector based on this network is evaluated against the non-temporal counterpart as baseline and achieves competitive results in an evaluation on the KITTI object detection dataset.
Automated Focal Loss for Image based Object Detection
Apr 19, 2019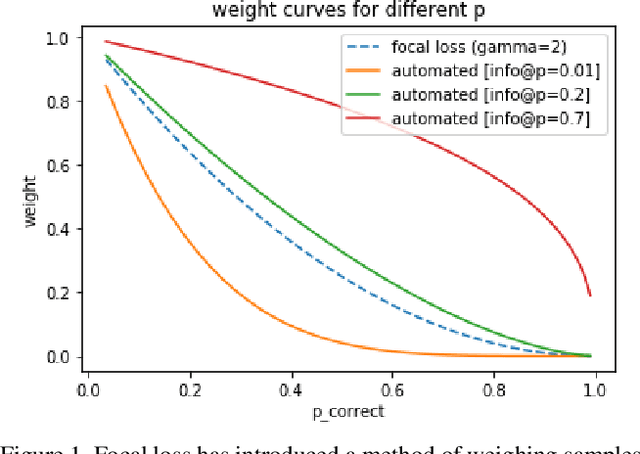
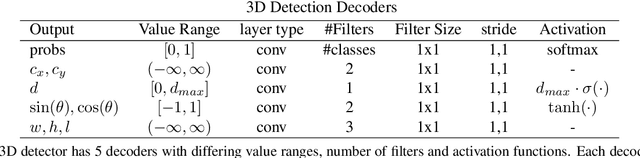
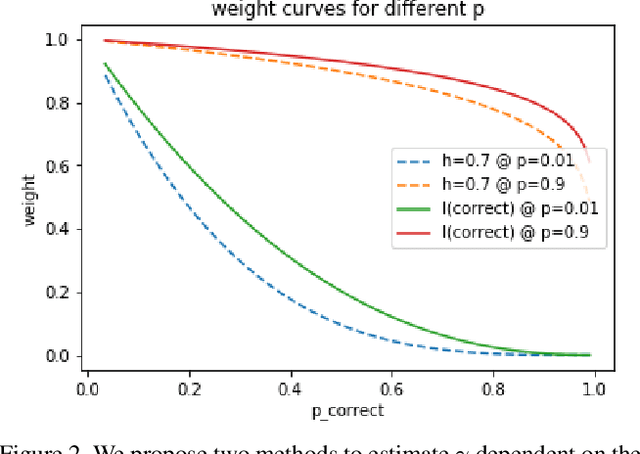
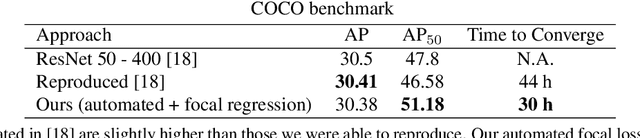
Current state-of-the-art object detection algorithms still suffer the problem of imbalanced distribution of training data over object classes and background. Recent work introduced a new loss function called focal loss to mitigate this problem, but at the cost of an additional hyperparameter. Manually tuning this hyperparameter for each training task is highly time-consuming. With automated focal loss we introduce a new loss function which substitutes this hyperparameter by a parameter that is automatically adapted during the training progress and controls the amount of focusing on hard training examples. We show on the COCO benchmark that this leads to an up to 30% faster training convergence. We further introduced a focal regression loss which on the more challenging task of 3D vehicle detection outperforms other loss functions by up to 1.8 AOS and can be used as a value range independent metric for regression.
MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
May 08, 2018
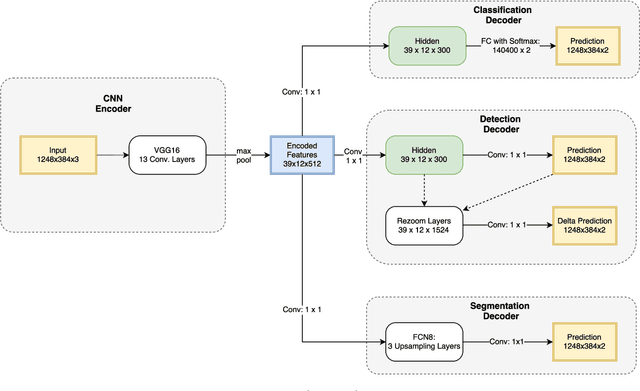
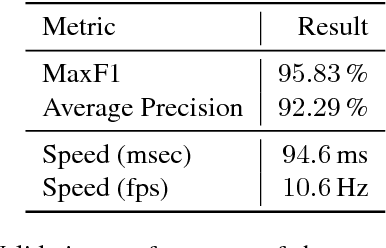
While most approaches to semantic reasoning have focused on improving performance, in this paper we argue that computational times are very important in order to enable real time applications such as autonomous driving. Towards this goal, we present an approach to joint classification, detection and semantic segmentation via a unified architecture where the encoder is shared amongst the three tasks. Our approach is very simple, can be trained end-to-end and performs extremely well in the challenging KITTI dataset, outperforming the state-of-the-art in the road segmentation task. Our approach is also very efficient, taking less than 100 ms to perform all tasks.
Fully Convolutional Neural Networks for Dynamic Object Detection in Grid Maps
Sep 10, 2017
Grid maps are widely used in robotics to represent obstacles in the environment and differentiating dynamic objects from static infrastructure is essential for many practical applications. In this work, we present a methods that uses a deep convolutional neural network (CNN) to infer whether grid cells are covering a moving object or not. Compared to tracking approaches, that use e.g. a particle filter to estimate grid cell velocities and then make a decision for individual grid cells based on this estimate, our approach uses the entire grid map as input image for a CNN that inspects a larger area around each cell and thus takes the structural appearance in the grid map into account to make a decision. Compared to our reference method, our concept yields a performance increase from 83.9% to 97.2%. A runtime optimized version of our approach yields similar improvements with an execution time of just 10 milliseconds.