 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRAG: A Framework for Fine-Tuning Retrieval-Augmented Generation Systems
Jun 12, 2025Retrieval-augmented generation (RAG) systems have been shown to be effective in addressing many of the drawbacks of relying solely on the parametric memory of large language models. Recent work has demonstrated that RAG systems can be improved via fine-tuning of their retriever and generator models. In this work, we introduce FedRAG, a framework for fine-tuning RAG systems across centralized and federated architectures. FedRAG supports state-of-the-art fine-tuning methods, offering a simple and intuitive interface and a seamless conversion from centralized to federated training tasks. FedRAG is also deeply integrated with the modern RAG ecosystem, filling a critical gap in available tools.
Spatiotemporal deep learning models for detection of rapid intensification in cyclones
Jun 10, 2025Cyclone rapid intensification is the rapid increase in cyclone wind intensity, exceeding a threshold of 30 knots, within 24 hours. Rapid intensification is considered an extreme event during a cyclone, and its occurrence is relatively rare, contributing to a class imbalance in the dataset. A diverse array of factors influences the likelihood of a cyclone undergoing rapid intensification, further complicating the task for conventional machine learning models. In this paper, we evaluate deep learning, ensemble learning and data augmentation frameworks to detect cyclone rapid intensification based on wind intensity and spatial coordinates. We note that conventional data augmentation methods cannot be utilised for generating spatiotemporal patterns replicating cyclones that undergo rapid intensification. Therefore, our framework employs deep learning models to generate spatial coordinates and wind intensity that replicate cyclones to address the class imbalance problem of rapid intensification. We also use a deep learning model for the classification module within the data augmentation framework to differentiate between rapid and non-rapid intensification events during a cyclone. Our results show that data augmentation improves the results for rapid intensification detection in cyclones, and spatial coordinates play a critical role as input features to the given models. This paves the way for research in synthetic data generation for spatiotemporal data with extreme events.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
Hybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Choice Models and Permutation Invariance
Jul 13, 2023



Choice Modeling is at the core of many economics, operations, and marketing problems. In this paper, we propose a fundamental characterization of choice functions that encompasses a wide variety of extant choice models. We demonstrate how nonparametric estimators like neural nets can easily approximate such functionals and overcome the curse of dimensionality that is inherent in the non-parametric estimation of choice functions. We demonstrate through extensive simulations that our proposed functionals can flexibly capture underlying consumer behavior in a completely data-driven fashion and outperform traditional parametric models. As demand settings often exhibit endogenous features, we extend our framework to incorporate estimation under endogenous features. Further, we also describe a formal inference procedure to construct valid confidence intervals on objects of interest like price elasticity. Finally, to assess the practical applicability of our estimator, we utilize a real-world dataset from S. Berry, Levinsohn, and Pakes (1995). Our empirical analysis confirms that the estimator generates realistic and comparable own- and cross-price elasticities that are consistent with the observations reported in the existing literature.
Interpretable Anomaly Detection in Cellular Networks by Learning Concepts in Variational Autoencoders
Jun 28, 2023This paper addresses the challenges of detecting anomalies in cellular networks in an interpretable way and proposes a new approach using variational autoencoders (VAEs) that learn interpretable representations of the latent space for each Key Performance Indicator (KPI) in the dataset. This enables the detection of anomalies based on reconstruction loss and Z-scores. We ensure the interpretability of the anomalies via additional information centroids (c) using the K-means algorithm to enhance representation learning. We evaluate the performance of the model by analyzing patterns in the latent dimension for specific KPIs and thereby demonstrate the interpretability and anomalies. The proposed framework offers a faster and autonomous solution for detecting anomalies in cellular networks and showcases the potential of deep learning-based algorithms in handling big data.
Language, Time Preferences, and Consumer Behavior: Evidence from Large Language Models
May 04, 2023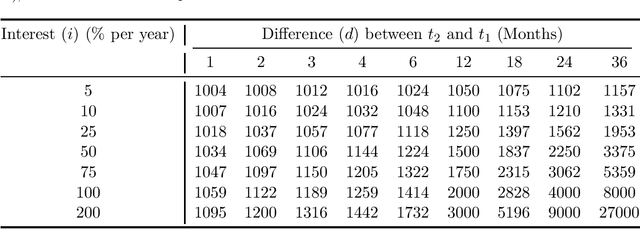


Language has a strong influence on our perceptions of time and rewards. This raises the question of whether large language models, when asked in different languages, show different preferences for rewards over time and if their choices are similar to those of humans. In this study, we analyze the responses of GPT-3.5 (hereafter referred to as GPT) to prompts in multiple languages, exploring preferences between smaller, sooner rewards and larger, later rewards. Our results show that GPT displays greater patience when prompted in languages with weak future tense references (FTR), such as German and Mandarin, compared to languages with strong FTR, like English and French. These findings are consistent with existing literature and suggest a correlation between GPT's choices and the preferences of speakers of these languages. However, further analysis reveals that the preference for earlier or later rewards does not systematically change with reward gaps, indicating a lexicographic preference for earlier payments. While GPT may capture intriguing variations across languages, our findings indicate that the choices made by these models do not correspond to those of human decision-makers.
User-friendly Comparison of Similarity Algorithms on Wikidata
Aug 11, 2021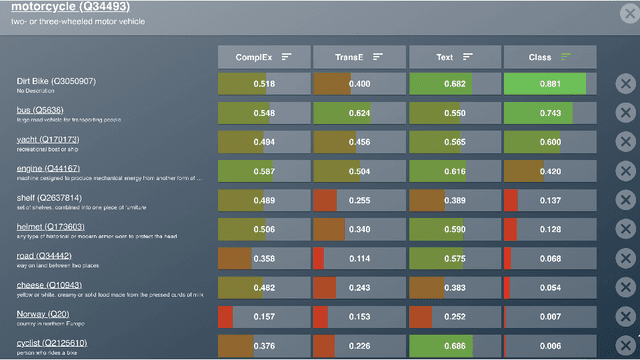
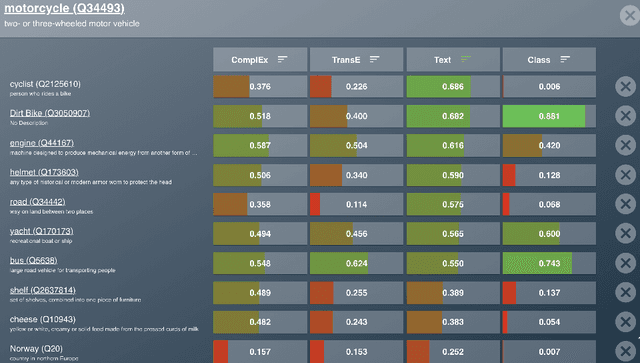
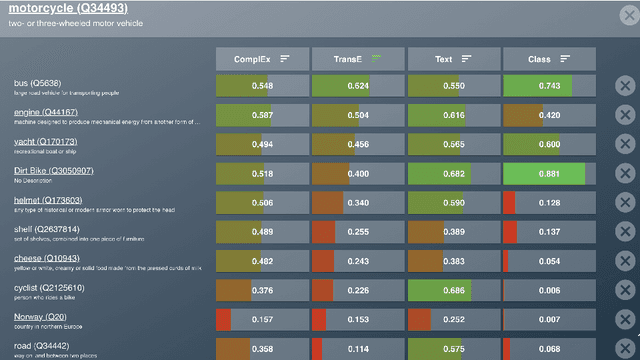
While the similarity between two concept words has been evaluated and studied for decades, much less attention has been devoted to algorithms that can compute the similarity of nodes in very large knowledge graphs, like Wikidata. To facilitate investigations and head-to-head comparisons of similarity algorithms on Wikidata, we present a user-friendly interface that allows flexible computation of similarity between Qnodes in Wikidata. At present, the similarity interface supports four algorithms, based on: graph embeddings (TransE, ComplEx), text embeddings (BERT), and class-based similarity. We demonstrate the behavior of the algorithms on representative examples about semantically similar, related, and entirely unrelated entity pairs. To support anticipated applications that require efficient similarity computations, like entity linking and recommendation, we also provide a REST API that can compute most similar neighbors for any Qnode in Wikidata.
Sparse-Push: Communication- & Energy-Efficient Decentralized Distributed Learning over Directed & Time-Varying Graphs with non-IID Datasets
Feb 12, 2021



Current deep learning (DL) systems rely on a centralized computing paradigm which limits the amount of available training data, increases system latency, and adds privacy and security constraints. On-device learning, enabled by decentralized and distributed training of DL models over peer-to-peer wirelessly connected edge devices, not only alleviate the above limitations but also enable next-gen applications that need DL models to continuously interact and learn from their environment. However, this necessitates the development of novel training algorithms that train DL models over time-varying and directed peer-to-peer graph structures while minimizing the amount of communication between the devices and also being resilient to non-IID data distributions. In this work we propose, Sparse-Push, a communication efficient decentralized distributed training algorithm that supports training over peer-to-peer, directed, and time-varying graph topologies. The proposed algorithm enables 466x reduction in communication with only 1% degradation in performance when training various DL models such as ResNet-20 and VGG11 over the CIFAR-10 dataset. Further, we demonstrate how communication compression can lead to significant performance degradation in-case of non-IID datasets, and propose Skew-Compensated Sparse Push algorithm that recovers this performance drop while maintaining similar levels of communication compression.
Causal Gradient Boosting: Boosted Instrumental Variable Regression
Jan 15, 2021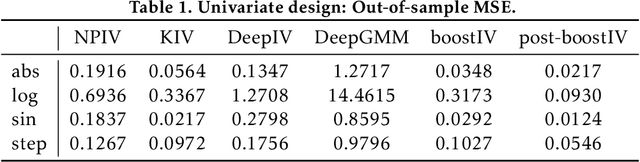
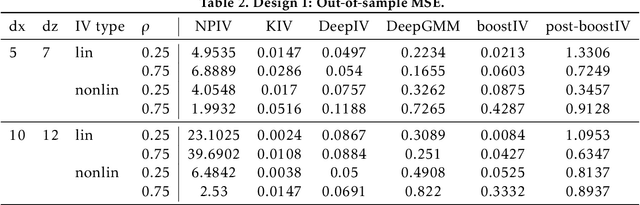

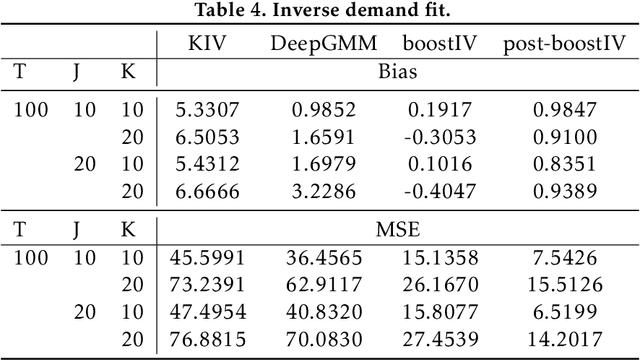
Recent advances in the literature have demonstrated that standard supervised learning algorithms are ill-suited for problems with endogenous explanatory variables. To correct for the endogeneity bias, many variants of nonparameteric instrumental variable regression methods have been developed. In this paper, we propose an alternative algorithm called boostIV that builds on the traditional gradient boosting algorithm and corrects for the endogeneity bias. The algorithm is very intuitive and resembles an iterative version of the standard 2SLS estimator. Moreover, our approach is data driven, meaning that the researcher does not have to make a stance on neither the form of the target function approximation nor the choice of instruments. We demonstrate that our estimator is consistent under mild conditions. We carry out extensive Monte Carlo simulations to demonstrate the finite sample performance of our algorithm compared to other recently developed methods. We show that boostIV is at worst on par with the existing methods and on average significantly outperforms them.