 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Operational Collective Intelligence of Humans and Machines
Feb 16, 2024We explore the use of aggregative crowdsourced forecasting (ACF) as a mechanism to help operationalize ``collective intelligence'' of human-machine teams for coordinated actions. We adopt the definition for Collective Intelligence as: ``A property of groups that emerges from synergies among data-information-knowledge, software-hardware, and individuals (those with new insights as well as recognized authorities) that enables just-in-time knowledge for better decisions than these three elements acting alone.'' Collective Intelligence emerges from new ways of connecting humans and AI to enable decision-advantage, in part by creating and leveraging additional sources of information that might otherwise not be included. Aggregative crowdsourced forecasting (ACF) is a recent key advancement towards Collective Intelligence wherein predictions (X\% probability that Y will happen) and rationales (why I believe it is this probability that X will happen) are elicited independently from a diverse crowd, aggregated, and then used to inform higher-level decision-making. This research asks whether ACF, as a key way to enable Operational Collective Intelligence, could be brought to bear on operational scenarios (i.e., sequences of events with defined agents, components, and interactions) and decision-making, and considers whether such a capability could provide novel operational capabilities to enable new forms of decision-advantage.
User-friendly Comparison of Similarity Algorithms on Wikidata
Aug 11, 2021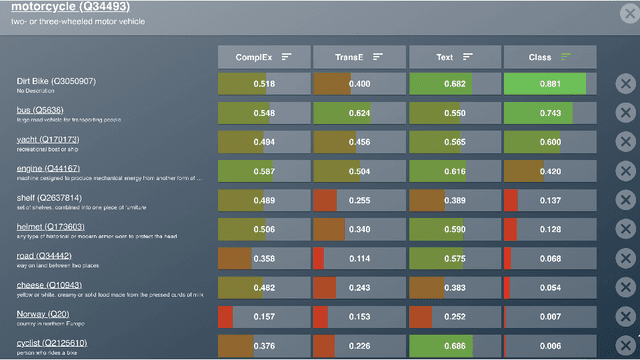
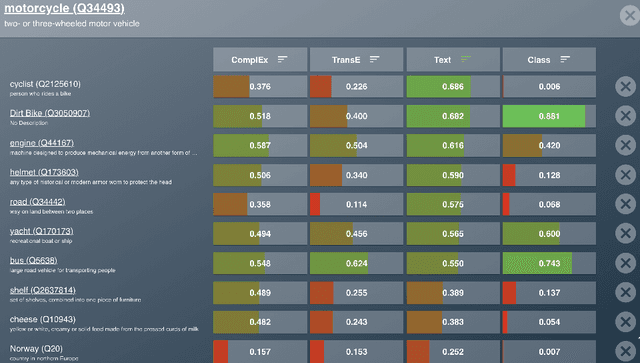
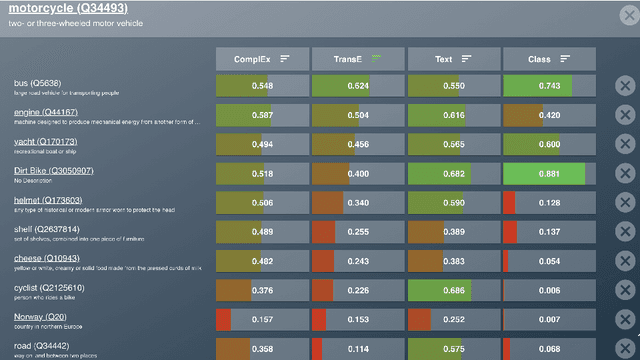
While the similarity between two concept words has been evaluated and studied for decades, much less attention has been devoted to algorithms that can compute the similarity of nodes in very large knowledge graphs, like Wikidata. To facilitate investigations and head-to-head comparisons of similarity algorithms on Wikidata, we present a user-friendly interface that allows flexible computation of similarity between Qnodes in Wikidata. At present, the similarity interface supports four algorithms, based on: graph embeddings (TransE, ComplEx), text embeddings (BERT), and class-based similarity. We demonstrate the behavior of the algorithms on representative examples about semantically similar, related, and entirely unrelated entity pairs. To support anticipated applications that require efficient similarity computations, like entity linking and recommendation, we also provide a REST API that can compute most similar neighbors for any Qnode in Wikidata.