 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Wikidata with Linked Open Data
Jul 01, 2022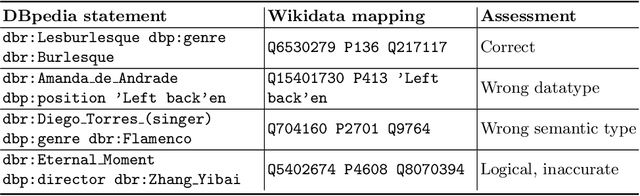
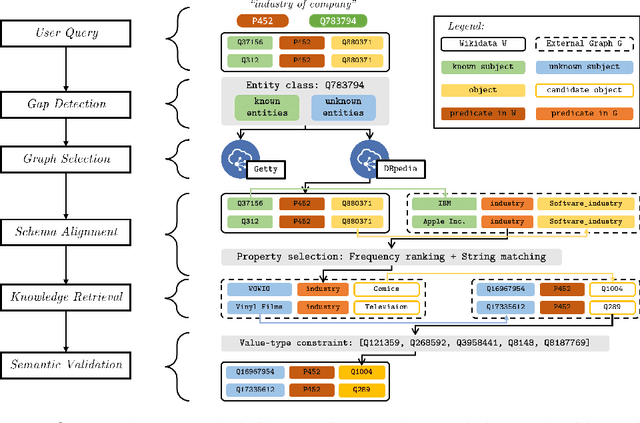


Large public knowledge graphs, like Wikidata, contain billions of statements about tens of millions of entities, thus inspiring various use cases to exploit such knowledge graphs. However, practice shows that much of the relevant information that fits users' needs is still missing in Wikidata, while current linked open data (LOD) tools are not suitable to enrich large graphs like Wikidata. In this paper, we investigate the potential of enriching Wikidata with structured data sources from the LOD cloud. We present a novel workflow that includes gap detection, source selection, schema alignment, and semantic validation. We evaluate our enrichment method with two complementary LOD sources: a noisy source with broad coverage, DBpedia, and a manually curated source with narrow focus on the art domain, Getty. Our experiments show that our workflow can enrich Wikidata with millions of novel statements from external LOD sources with a high quality. Property alignment and data quality are key challenges, whereas entity alignment and source selection are well-supported by existing Wikidata mechanisms. We make our code and data available to support future work.
Robust (Controlled) Table-to-Text Generation with Structure-Aware Equivariance Learning
May 08, 2022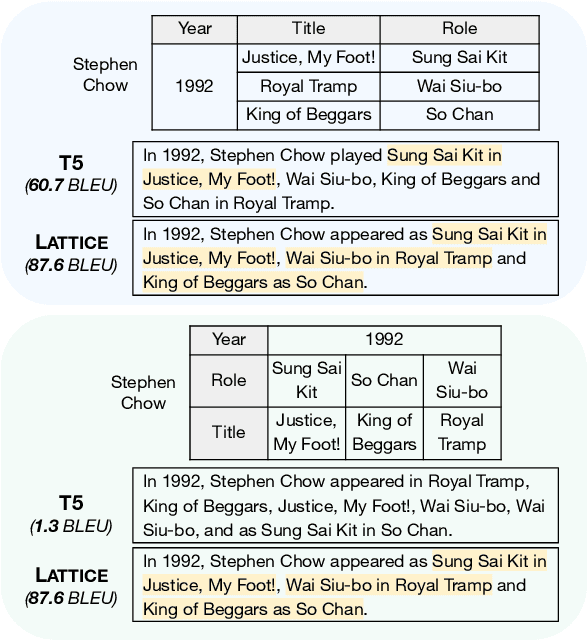
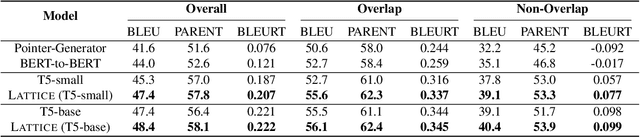
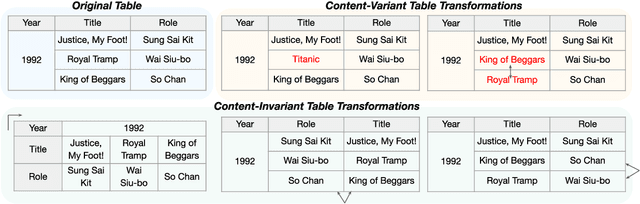

Controlled table-to-text generation seeks to generate natural language descriptions for highlighted subparts of a table. Previous SOTA systems still employ a sequence-to-sequence generation method, which merely captures the table as a linear structure and is brittle when table layouts change. We seek to go beyond this paradigm by (1) effectively expressing the relations of content pieces in the table, and (2) making our model robust to content-invariant structural transformations. Accordingly, we propose an equivariance learning framework, which encodes tables with a structure-aware self-attention mechanism. This prunes the full self-attention structure into an order-invariant graph attention that captures the connected graph structure of cells belonging to the same row or column, and it differentiates between relevant cells and irrelevant cells from the structural perspective. Our framework also modifies the positional encoding mechanism to preserve the relative position of tokens in the same cell but enforce position invariance among different cells. Our technology is free to be plugged into existing table-to-text generation models, and has improved T5-based models to offer better performance on ToTTo and HiTab. Moreover, on a harder version of ToTTo, we preserve promising performance, while previous SOTA systems, even with transformation-based data augmentation, have seen significant performance drops. Our code is available at https://github.com/luka-group/Lattice.
Augmenting Knowledge Graphs for Better Link Prediction
Mar 26, 2022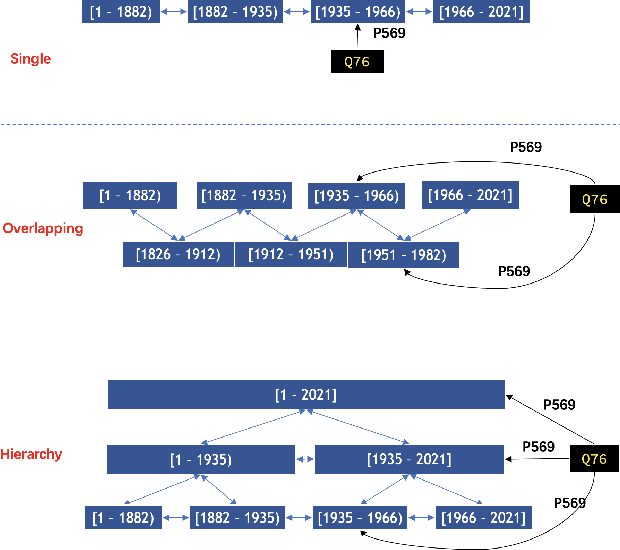

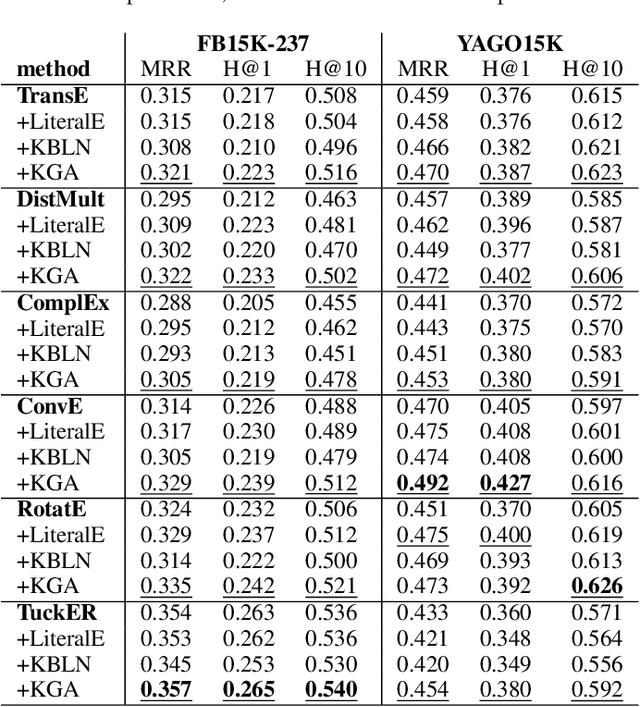
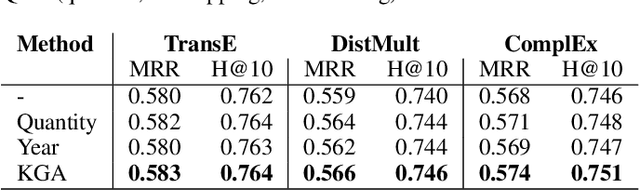
Embedding methods have demonstrated robust performance on the task of link prediction in knowledge graphs, by mostly encoding entity relationships. Recent methods propose to enhance the loss function with a literal-aware term. In this paper, we propose KGA: a knowledge graph augmentation method that incorporates literals in an embedding model without modifying its loss function. KGA discretizes quantity and year values into bins, and chains these bins both horizontally, modeling neighboring values, and vertically, modeling multiple levels of granularity. KGA is scalable and can be used as a pre-processing step for any existing knowledge graph embedding model. Experiments on legacy benchmarks and a new large benchmark, DWD, show that augmenting the knowledge graph with quantities and years is beneficial for predicting both entities and numbers, as KGA outperforms the vanilla models and other relevant baselines. Our ablation studies confirm that both quantities and years contribute to KGA's performance, and that its performance depends on the discretization and binning settings. We make the code, models, and the DWD benchmark publicly available to facilitate reproducibility and future research.
Evaluating Machine Common Sense via Cloze Testing
Jan 19, 2022Language models (LMs) show state of the art performance for common sense (CS) question answering, but whether this ability implies a human-level mastery of CS remains an open question. Understanding the limitations and strengths of LMs can help researchers improve these models, potentially by developing novel ways of integrating external CS knowledge. We devise a series of tests and measurements to systematically quantify their performance on different aspects of CS. We propose the use of cloze testing combined with word embeddings to measure the LM's robustness and confidence. Our results show than although language models tend to achieve human-like accuracy, their confidence is subpar. Future work can leverage this information to build more complex systems, such as an ensemble of symbolic and distributed knowledge.
Table-based Fact Verification with Salience-aware Learning
Sep 09, 2021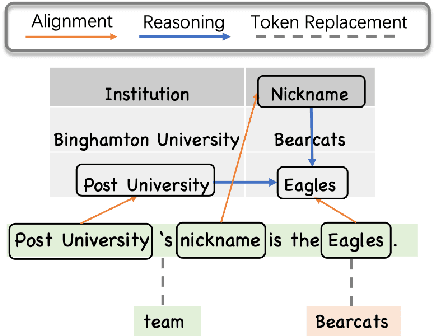
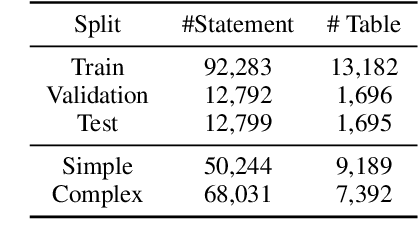
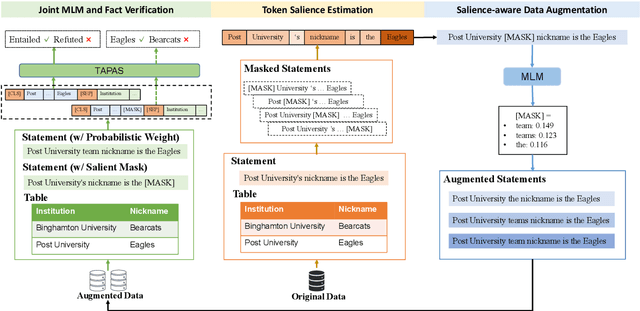
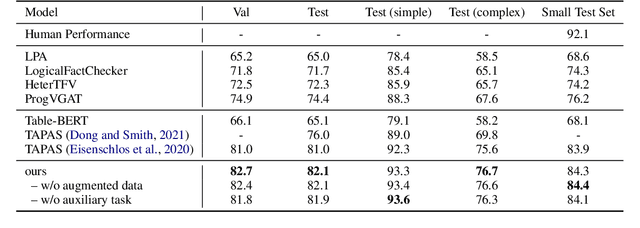
Tables provide valuable knowledge that can be used to verify textual statements. While a number of works have considered table-based fact verification, direct alignments of tabular data with tokens in textual statements are rarely available. Moreover, training a generalized fact verification model requires abundant labeled training data. In this paper, we propose a novel system to address these problems. Inspired by counterfactual causality, our system identifies token-level salience in the statement with probing-based salience estimation. Salience estimation allows enhanced learning of fact verification from two perspectives. From one perspective, our system conducts masked salient token prediction to enhance the model for alignment and reasoning between the table and the statement. From the other perspective, our system applies salience-aware data augmentation to generate a more diverse set of training instances by replacing non-salient terms. Experimental results on TabFact show the effective improvement by the proposed salience-aware learning techniques, leading to the new SOTA performance on the benchmark. Our code is publicly available at https://github.com/luka-group/Salience-aware-Learning .
Creating and Querying Personalized Versions of Wikidata on a Laptop
Aug 18, 2021
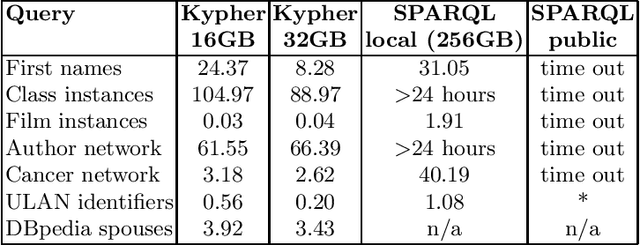


Application developers today have three choices for exploiting the knowledge present in Wikidata: they can download the Wikidata dumps in JSON or RDF format, they can use the Wikidata API to get data about individual entities, or they can use the Wikidata SPARQL endpoint. None of these methods can support complex, yet common, query use cases, such as retrieval of large amounts of data or aggregations over large fractions of Wikidata. This paper introduces KGTK Kypher, a query language and processor that allows users to create personalized variants of Wikidata on a laptop. We present several use cases that illustrate the types of analyses that Kypher enables users to run on the full Wikidata KG on a laptop, combining data from external resources such as DBpedia. The Kypher queries for these use cases run much faster on a laptop than the equivalent SPARQL queries on a Wikidata clone running on a powerful server with 24h time-out limits.
User-friendly Comparison of Similarity Algorithms on Wikidata
Aug 11, 2021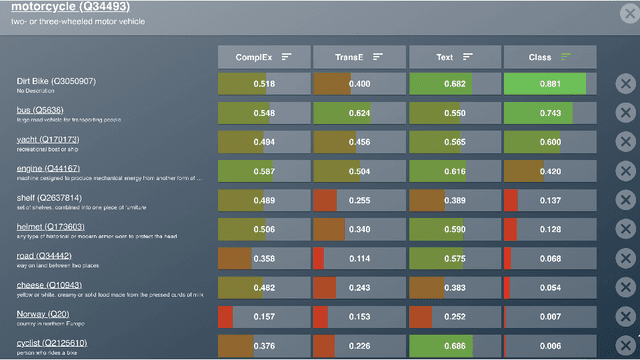
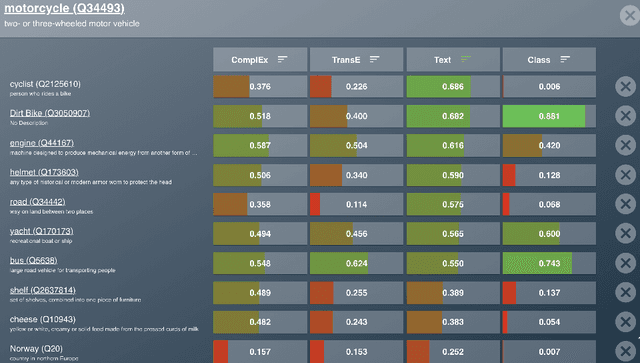
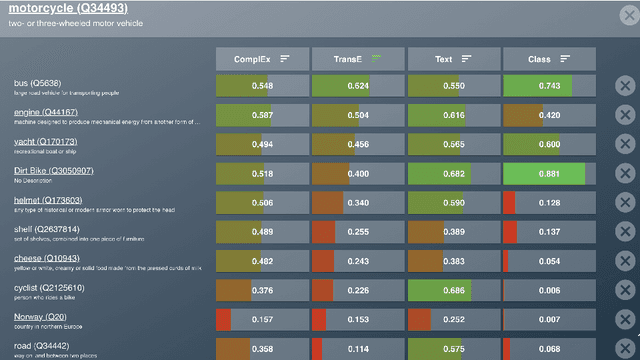
While the similarity between two concept words has been evaluated and studied for decades, much less attention has been devoted to algorithms that can compute the similarity of nodes in very large knowledge graphs, like Wikidata. To facilitate investigations and head-to-head comparisons of similarity algorithms on Wikidata, we present a user-friendly interface that allows flexible computation of similarity between Qnodes in Wikidata. At present, the similarity interface supports four algorithms, based on: graph embeddings (TransE, ComplEx), text embeddings (BERT), and class-based similarity. We demonstrate the behavior of the algorithms on representative examples about semantically similar, related, and entirely unrelated entity pairs. To support anticipated applications that require efficient similarity computations, like entity linking and recommendation, we also provide a REST API that can compute most similar neighbors for any Qnode in Wikidata.
A Study of the Quality of Wikidata
Jul 23, 2021
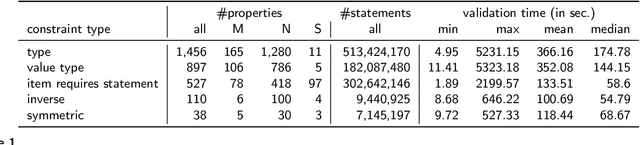
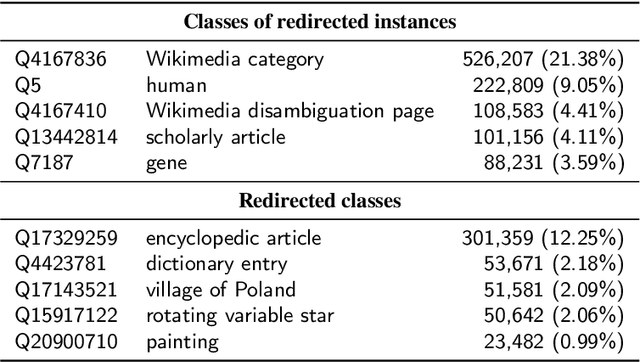
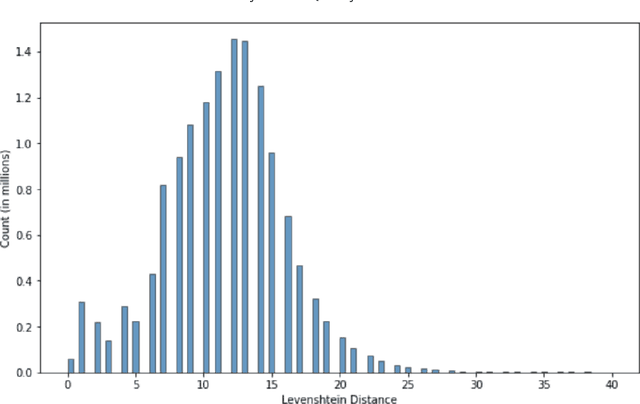
Wikidata has been increasingly adopted by many communities for a wide variety of applications, which demand high-quality knowledge to deliver successful results. In this paper, we develop a framework to detect and analyze low-quality statements in Wikidata by shedding light on the current practices exercised by the community. We explore three indicators of data quality in Wikidata, based on: 1) community consensus on the currently recorded knowledge, assuming that statements that have been removed and not added back are implicitly agreed to be of low quality; 2) statements that have been deprecated; and 3) constraint violations in the data. We combine these indicators to detect low-quality statements, revealing challenges with duplicate entities, missing triples, violated type rules, and taxonomic distinctions. Our findings complement ongoing efforts by the Wikidata community to improve data quality, aiming to make it easier for users and editors to find and correct mistakes.
Retrieving Complex Tables with Multi-Granular Graph Representation Learning
May 04, 2021
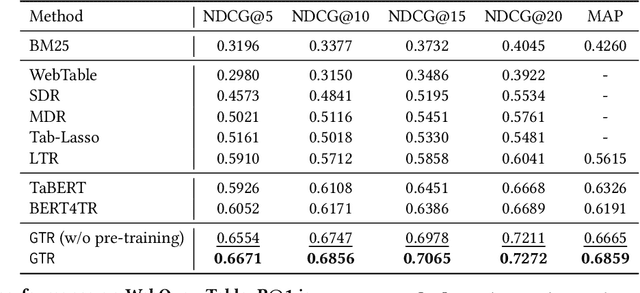
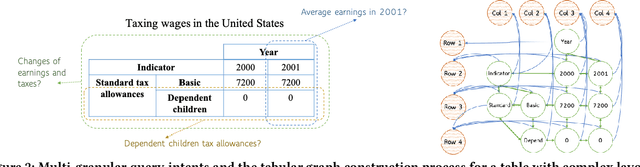
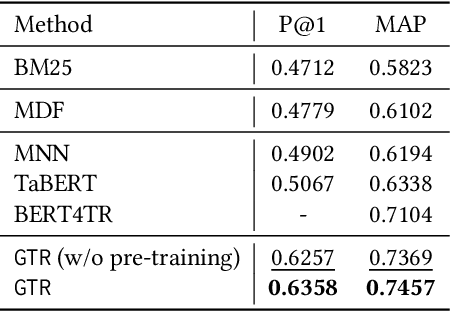
The task of natural language table retrieval (NLTR) seeks to retrieve semantically relevant tables based on natural language queries. Existing learning systems for this task often treat tables as plain text based on the assumption that tables are structured as dataframes. However, tables can have complex layouts which indicate diverse dependencies between subtable structures, such as nested headers. As a result, queries may refer to different spans of relevant content that is distributed across these structures. Moreover, such systems fail to generalize to novel scenarios beyond those seen in the training set. Prior methods are still distant from a generalizable solution to the NLTR problem, as they fall short in handling complex table layouts or queries over multiple granularities. To address these issues, we propose Graph-based Table Retrieval (GTR), a generalizable NLTR framework with multi-granular graph representation learning. In our framework, a table is first converted into a tabular graph, with cell nodes, row nodes and column nodes to capture content at different granularities. Then the tabular graph is input to a Graph Transformer model that can capture both table cell content and the layout structures. To enhance the robustness and generalizability of the model, we further incorporate a self-supervised pre-training task based on graph-context matching. Experimental results on two benchmarks show that our method leads to significant improvements over the current state-of-the-art systems. Further experiments demonstrate promising performance of our method on cross-dataset generalization, and enhanced capability of handling complex tables and fulfilling diverse query intents. Code and data are available at https://github.com/FeiWang96/GTR.
CoreQuisite: Circumstantial Preconditions of Common Sense Knowledge
Apr 18, 2021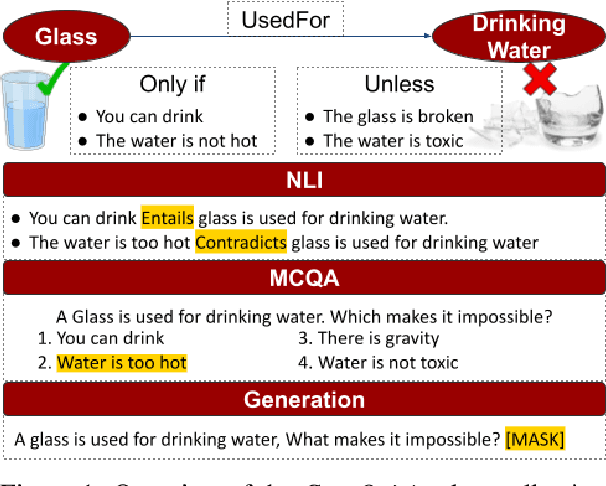

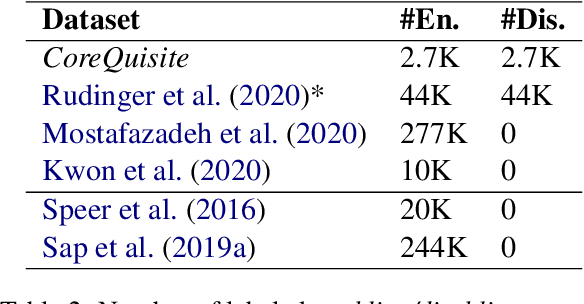
The task of identifying and reasoning with circumstantial preconditions associated with everyday facts is natural to humans. It is unclear whether state-of-the-art language models (LMs) understand the implicit preconditions that enable or invalidate commonsense facts, such as "A glass is used for drinking water", Despite their impressive accuracy on existing commonsense tasks. In this paper, we propose a new problem of reasoning with circumstantial preconditions, and present a dataset, called CoreQuisite, which annotates commonsense facts with preconditions expressed in natural language. Based on this resource, we create three canonical evaluation tasks and use them to examine the capability of existing LMs to understand situational pre-conditions. Our results show that there is a 10-30%gap between machine and human performance on our tasks. We make all resources and software publicly available.