 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonological Representation Learning for Isolated Signs Improves Out-of-Vocabulary Generalization
Sep 05, 2025Sign language datasets are often not representative in terms of vocabulary, underscoring the need for models that generalize to unseen signs. Vector quantization is a promising approach for learning discrete, token-like representations, but it has not been evaluated whether the learned units capture spurious correlations that hinder out-of-vocabulary performance. This work investigates two phonological inductive biases: Parameter Disentanglement, an architectural bias, and Phonological Semi-Supervision, a regularization technique, to improve isolated sign recognition of known signs and reconstruction quality of unseen signs with a vector-quantized autoencoder. The primary finding is that the learned representations from the proposed model are more effective for one-shot reconstruction of unseen signs and more discriminative for sign identification compared to a controlled baseline. This work provides a quantitative analysis of how explicit, linguistically-motivated biases can improve the generalization of learned representations of sign language.
The American Sign Language Knowledge Graph: Infusing ASL Models with Linguistic Knowledge
Nov 06, 2024

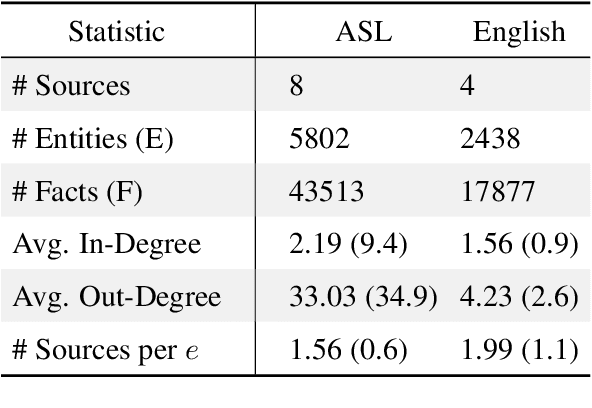
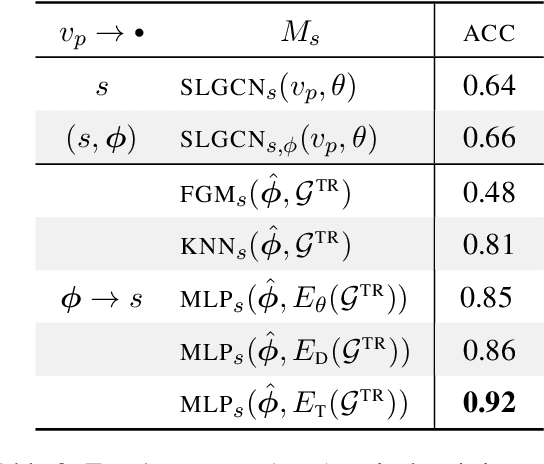
Language models for American Sign Language (ASL) could make language technologies substantially more accessible to those who sign. To train models on tasks such as isolated sign recognition (ISR) and ASL-to-English translation, datasets provide annotated video examples of ASL signs. To facilitate the generalizability and explainability of these models, we introduce the American Sign Language Knowledge Graph (ASLKG), compiled from twelve sources of expert linguistic knowledge. We use the ASLKG to train neuro-symbolic models for 3 ASL understanding tasks, achieving accuracies of 91% on ISR, 14% for predicting the semantic features of unseen signs, and 36% for classifying the topic of Youtube-ASL videos.
Harmful Speech Detection by Language Models Exhibits Gender-Queer Dialect Bias
May 23, 2024Content moderation on social media platforms shapes the dynamics of online discourse, influencing whose voices are amplified and whose are suppressed. Recent studies have raised concerns about the fairness of content moderation practices, particularly for aggressively flagging posts from transgender and non-binary individuals as toxic. In this study, we investigate the presence of bias in harmful speech classification of gender-queer dialect online, focusing specifically on the treatment of reclaimed slurs. We introduce a novel dataset, QueerReclaimLex, based on 109 curated templates exemplifying non-derogatory uses of LGBTQ+ slurs. Dataset instances are scored by gender-queer annotators for potential harm depending on additional context about speaker identity. We systematically evaluate the performance of five off-the-shelf language models in assessing the harm of these texts and explore the effectiveness of chain-of-thought prompting to teach large language models (LLMs) to leverage author identity context. We reveal a tendency for these models to inaccurately flag texts authored by gender-queer individuals as harmful. Strikingly, across all LLMs the performance is poorest for texts that show signs of being written by individuals targeted by the featured slur (F1 <= 0.24). We highlight an urgent need for fairness and inclusivity in content moderation systems. By uncovering these biases, this work aims to inform the development of more equitable content moderation practices and contribute to the creation of inclusive online spaces for all users.
Detecting Unseen Multiword Expressions in American Sign Language
Sep 30, 2023Multiword expressions present unique challenges in many translation tasks. In an attempt to ultimately apply a multiword expression detection system to the translation of American Sign Language, we built and tested two systems that apply word embeddings from GloVe to determine whether or not the word embeddings of lexemes can be used to predict whether or not those lexemes compose a multiword expression. It became apparent that word embeddings carry data that can detect non-compositionality with decent accuracy.
Exploring Strategies for Modeling Sign Language Phonology
Sep 30, 2023


Like speech, signs are composed of discrete, recombinable features called phonemes. Prior work shows that models which can recognize phonemes are better at sign recognition, motivating deeper exploration into strategies for modeling sign language phonemes. In this work, we learn graph convolution networks to recognize the sixteen phoneme "types" found in ASL-LEX 2.0. Specifically, we explore how learning strategies like multi-task and curriculum learning can leverage mutually useful information between phoneme types to facilitate better modeling of sign language phonemes. Results on the Sem-Lex Benchmark show that curriculum learning yields an average accuracy of 87% across all phoneme types, outperforming fine-tuning and multi-task strategies for most phoneme types.
Finding Pragmatic Differences Between Disciplines
Sep 30, 2023Scholarly documents have a great degree of variation, both in terms of content (semantics) and structure (pragmatics). Prior work in scholarly document understanding emphasizes semantics through document summarization and corpus topic modeling but tends to omit pragmatics such as document organization and flow. Using a corpus of scholarly documents across 19 disciplines and state-of-the-art language modeling techniques, we learn a fixed set of domain-agnostic descriptors for document sections and "retrofit" the corpus to these descriptors (also referred to as "normalization"). Then, we analyze the position and ordering of these descriptors across documents to understand the relationship between discipline and structure. We report within-discipline structural archetypes, variability, and between-discipline comparisons, supporting the hypothesis that scholarly communities, despite their size, diversity, and breadth, share similar avenues for expressing their work. Our findings lay the foundation for future work in assessing research quality, domain style transfer, and further pragmatic analysis.
The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes
Sep 30, 2023Sign language recognition and translation technologies have the potential to increase access and inclusion of deaf signing communities, but research progress is bottlenecked by a lack of representative data. We introduce a new resource for American Sign Language (ASL) modeling, the Sem-Lex Benchmark. The Benchmark is the current largest of its kind, consisting of over 84k videos of isolated sign productions from deaf ASL signers who gave informed consent and received compensation. Human experts aligned these videos with other sign language resources including ASL-LEX, SignBank, and ASL Citizen, enabling useful expansions for sign and phonological feature recognition. We present a suite of experiments which make use of the linguistic information in ASL-LEX, evaluating the practicality and fairness of the Sem-Lex Benchmark for isolated sign recognition (ISR). We use an SL-GCN model to show that the phonological features are recognizable with 85% accuracy, and that they are effective as an auxiliary target to ISR. Learning to recognize phonological features alongside gloss results in a 6% improvement for few-shot ISR accuracy and a 2% improvement for ISR accuracy overall. Instructions for downloading the data can be found at https://github.com/leekezar/SemLex.
Improving Sign Recognition with Phonology
Feb 11, 2023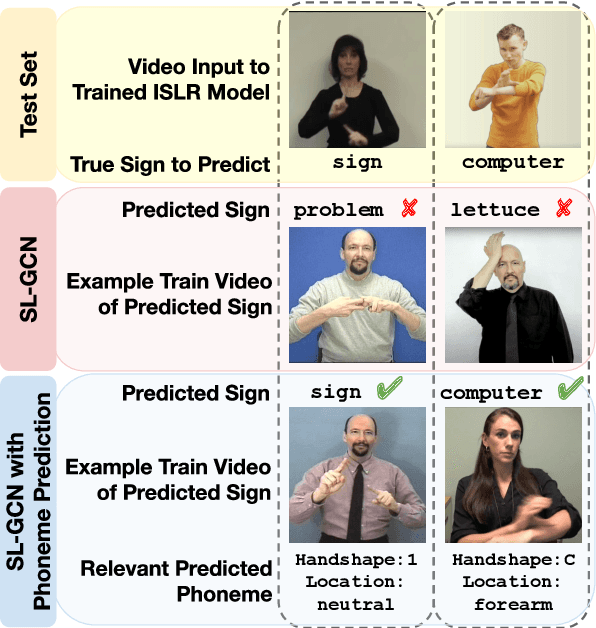

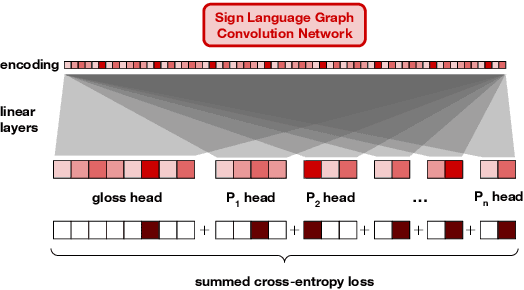

We use insights from research on American Sign Language (ASL) phonology to train models for isolated sign language recognition (ISLR), a step towards automatic sign language understanding. Our key insight is to explicitly recognize the role of phonology in sign production to achieve more accurate ISLR than existing work which does not consider sign language phonology. We train ISLR models that take in pose estimations of a signer producing a single sign to predict not only the sign but additionally its phonological characteristics, such as the handshape. These auxiliary predictions lead to a nearly 9% absolute gain in sign recognition accuracy on the WLASL benchmark, with consistent improvements in ISLR regardless of the underlying prediction model architecture. This work has the potential to accelerate linguistic research in the domain of signed languages and reduce communication barriers between deaf and hearing people.
The Role of Facial Expressions and Emotion in ASL
Jan 19, 2022There is little prior work on quantifying the relationships between facial expressions and emotionality in American Sign Language. In this final report, we provide two methods for studying these relationships through probability and prediction. Using a large corpus of natural signing manually annotated with facial features paired with lexical emotion datasets, we find that there exist many relationships between emotionality and the face, and that a simple classifier can predict what someone is saying in terms of broad emotional categories only by looking at the face.
Evaluating Machine Common Sense via Cloze Testing
Jan 19, 2022Language models (LMs) show state of the art performance for common sense (CS) question answering, but whether this ability implies a human-level mastery of CS remains an open question. Understanding the limitations and strengths of LMs can help researchers improve these models, potentially by developing novel ways of integrating external CS knowledge. We devise a series of tests and measurements to systematically quantify their performance on different aspects of CS. We propose the use of cloze testing combined with word embeddings to measure the LM's robustness and confidence. Our results show than although language models tend to achieve human-like accuracy, their confidence is subpar. Future work can leverage this information to build more complex systems, such as an ensemble of symbolic and distributed knowledge.