 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025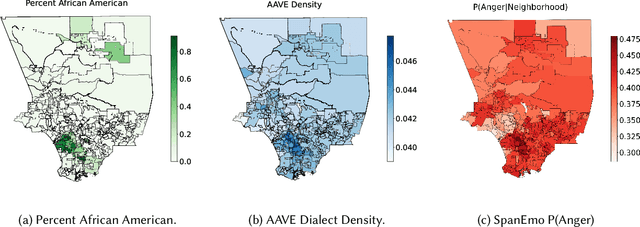
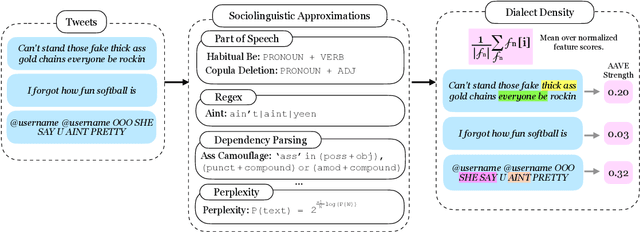
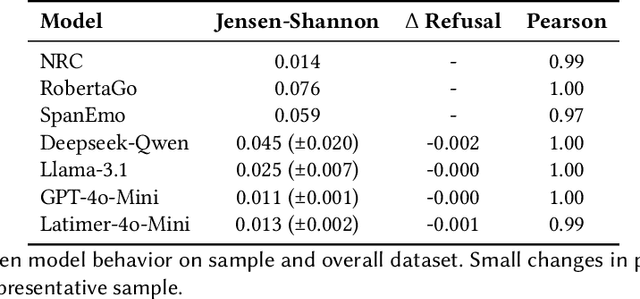

Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
Decoding Neural Signatures of Semantic Evaluations in Depression and Suicidality
Jul 30, 2025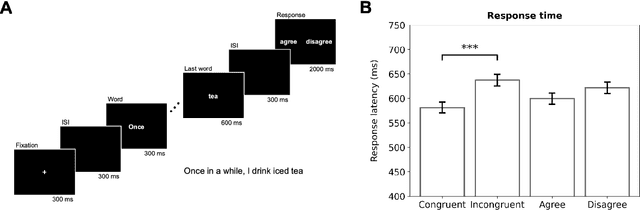
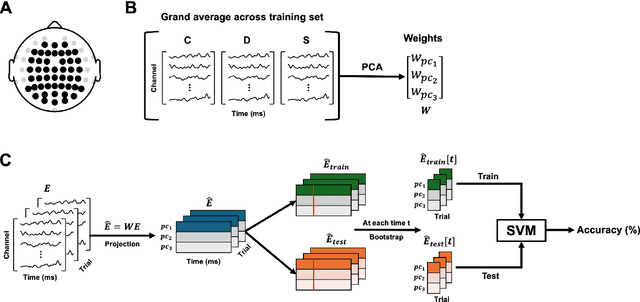
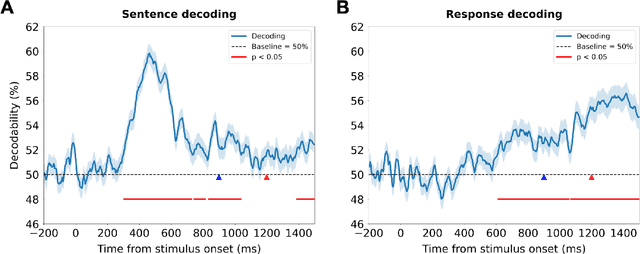
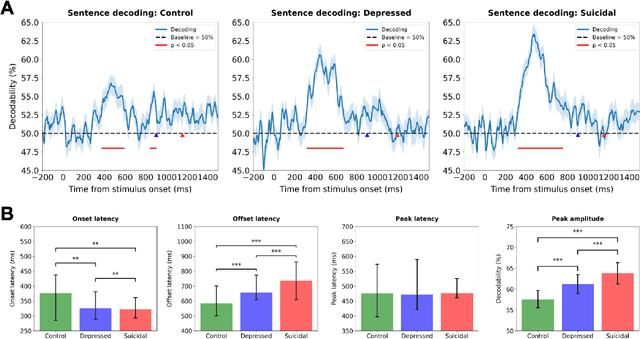
Depression and suicidality profoundly impact cognition and emotion, yet objective neurophysiological biomarkers remain elusive. We investigated the spatiotemporal neural dynamics underlying affective semantic processing in individuals with varying levels of clinical severity of depression and suicidality using multivariate decoding of electroencephalography (EEG) data. Participants (N=137) completed a sentence evaluation task involving emotionally charged self-referential statements while EEG was recorded. We identified robust, neural signatures of semantic processing, with peak decoding accuracy between 300-600 ms -- a window associated with automatic semantic evaluation and conflict monitoring. Compared to healthy controls, individuals with depression and suicidality showed earlier onset, longer duration, and greater amplitude decoding responses, along with broader cross-temporal generalization and increased activation of frontocentral and parietotemporal components. These findings suggest altered sensitivity and impaired disengagement from emotionally salient content in the clinical groups, advancing our understanding of the neurocognitive basis of mental health and providing a principled basis for developing reliable EEG-based biomarkers of depression and suicidality.
Neural Responses to Affective Sentences Reveal Signatures of Depression
Jun 06, 2025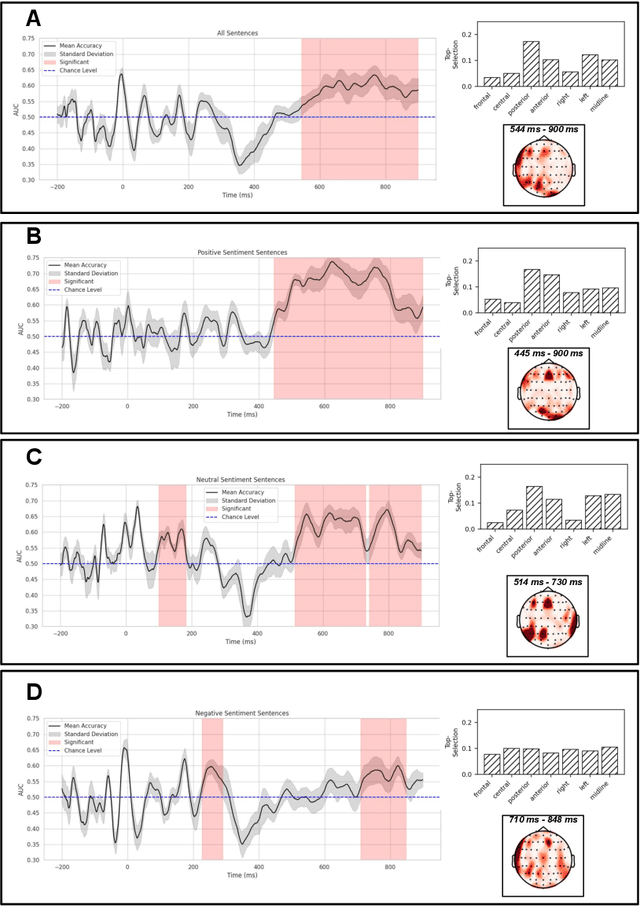
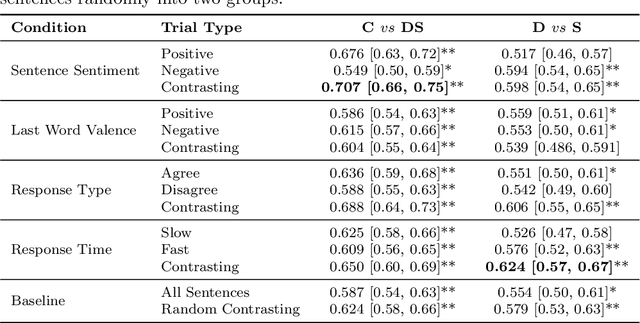
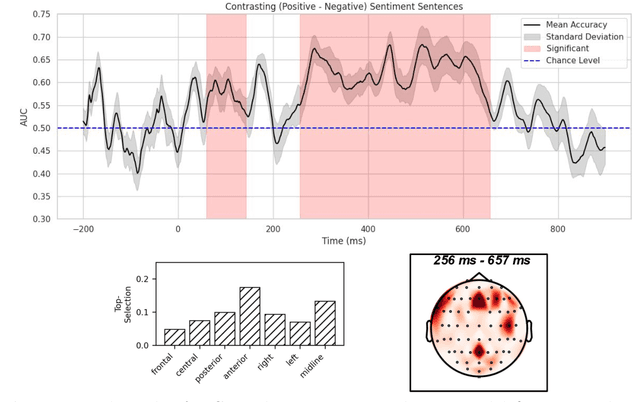

Major Depressive Disorder (MDD) is a highly prevalent mental health condition, and a deeper understanding of its neurocognitive foundations is essential for identifying how core functions such as emotional and self-referential processing are affected. We investigate how depression alters the temporal dynamics of emotional processing by measuring neural responses to self-referential affective sentences using surface electroencephalography (EEG) in healthy and depressed individuals. Our results reveal significant group-level differences in neural activity during sentence viewing, suggesting disrupted integration of emotional and self-referential information in depression. Deep learning model trained on these responses achieves an area under the receiver operating curve (AUC) of 0.707 in distinguishing healthy from depressed participants, and 0.624 in differentiating depressed subgroups with and without suicidal ideation. Spatial ablations highlight anterior electrodes associated with semantic and affective processing as key contributors. These findings suggest stable, stimulus-driven neural signatures of depression that may inform future diagnostic tools.
STEER-BENCH: A Benchmark for Evaluating the Steerability of Large Language Models
May 27, 2025Steerability, or the ability of large language models (LLMs) to adapt outputs to align with diverse community-specific norms, perspectives, and communication styles, is critical for real-world applications but remains under-evaluated. We introduce Steer-Bench, a benchmark for assessing population-specific steering using contrasting Reddit communities. Covering 30 contrasting subreddit pairs across 19 domains, Steer-Bench includes over 10,000 instruction-response pairs and validated 5,500 multiple-choice question with corresponding silver labels to test alignment with diverse community norms. Our evaluation of 13 popular LLMs using Steer-Bench reveals that while human experts achieve an accuracy of 81% with silver labels, the best-performing models reach only around 65% accuracy depending on the domain and configuration. Some models lag behind human-level alignment by over 15 percentage points, highlighting significant gaps in community-sensitive steerability. Steer-Bench is a benchmark to systematically assess how effectively LLMs understand community-specific instructions, their resilience to adversarial steering attempts, and their ability to accurately represent diverse cultural and ideological perspectives.
Humans Hallucinate Too: Language Models Identify and Correct Subjective Annotation Errors With Label-in-a-Haystack Prompts
May 22, 2025Modeling complex subjective tasks in Natural Language Processing, such as recognizing emotion and morality, is considerably challenging due to significant variation in human annotations. This variation often reflects reasonable differences in semantic interpretations rather than mere noise, necessitating methods to distinguish between legitimate subjectivity and error. We address this challenge by exploring label verification in these contexts using Large Language Models (LLMs). First, we propose a simple In-Context Learning binary filtering baseline that estimates the reasonableness of a document-label pair. We then introduce the Label-in-a-Haystack setting: the query and its label(s) are included in the demonstrations shown to LLMs, which are prompted to predict the label(s) again, while receiving task-specific instructions (e.g., emotion recognition) rather than label copying. We show how the failure to copy the label(s) to the output of the LLM are task-relevant and informative. Building on this, we propose the Label-in-a-Haystack Rectification (LiaHR) framework for subjective label correction: when the model outputs diverge from the reference gold labels, we assign the generated labels to the example instead of discarding it. This approach can be integrated into annotation pipelines to enhance signal-to-noise ratios. Comprehensive analyses, human evaluations, and ecological validity studies verify the utility of LiaHR for label correction. Code is available at https://github.com/gchochla/LiaHR.
Deep Learning Characterizes Depression and Suicidal Ideation from Eye Movements
Apr 29, 2025Identifying physiological and behavioral markers for mental health conditions is a longstanding challenge in psychiatry. Depression and suicidal ideation, in particular, lack objective biomarkers, with screening and diagnosis primarily relying on self-reports and clinical interviews. Here, we investigate eye tracking as a potential marker modality for screening purposes. Eye movements are directly modulated by neuronal networks and have been associated with attentional and mood-related patterns; however, their predictive value for depression and suicidality remains unclear. We recorded eye-tracking sequences from 126 young adults as they read and responded to affective sentences, and subsequently developed a deep learning framework to predict their clinical status. The proposed model included separate branches for trials of positive and negative sentiment, and used 2D time-series representations to account for both intra-trial and inter-trial variations. We were able to identify depression and suicidal ideation with an area under the receiver operating curve (AUC) of 0.793 (95% CI: 0.765-0.819) against healthy controls, and suicidality specifically with 0.826 AUC (95% CI: 0.797-0.852). The model also exhibited moderate, yet significant, accuracy in differentiating depressed from suicidal participants, with 0.609 AUC (95% CI 0.571-0.646). Discriminative patterns emerge more strongly when assessing the data relative to response generation than relative to the onset time of the final word of the sentences. The most pronounced effects were observed for negative-sentiment sentences, that are congruent to depressed and suicidal participants. Our findings highlight eye tracking as an objective tool for mental health assessment and underscore the modulatory impact of emotional stimuli on cognitive processes affecting oculomotor control.
Characterizing Network Structure of Anti-Trans Actors on TikTok
Jan 27, 2025The recent proliferation of short form video social media sites such as TikTok has been effectively utilized for increased visibility, communication, and community connection amongst trans/nonbinary creators online. However, these same platforms have also been exploited by right-wing actors targeting trans/nonbinary people, enabling such anti-trans actors to efficiently spread hate speech and propaganda. Given these divergent groups, what are the differences in network structure between anti-trans and pro-trans communities on TikTok, and to what extent do they amplify the effects of anti-trans content? In this paper, we collect a sample of TikTok videos containing pro and anti-trans content, and develop a taxonomy of trans related sentiment to enable the classification of content on TikTok, and ultimately analyze the reply network structures of pro-trans and anti-trans communities. In order to accomplish this, we worked with hired expert data annotators from the trans/nonbinary community in order to generate a sample of highly accurately labeled data. From this subset, we utilized a novel classification pipeline leveraging Retrieval-Augmented Generation (RAG) with annotated examples and taxonomy definitions to classify content into pro-trans, anti-trans, or neutral categories. We find that incorporating our taxonomy and its logics into our classification engine results in improved ability to differentiate trans related content, and that Results from network analysis indicate many interactions between posters of pro-trans and anti-trans content exist, further demonstrating targeting of trans individuals, and demonstrating the need for better content moderation tools
In-Group Love, Out-Group Hate: A Framework to Measure Affective Polarization via Contentious Online Discussions
Dec 18, 2024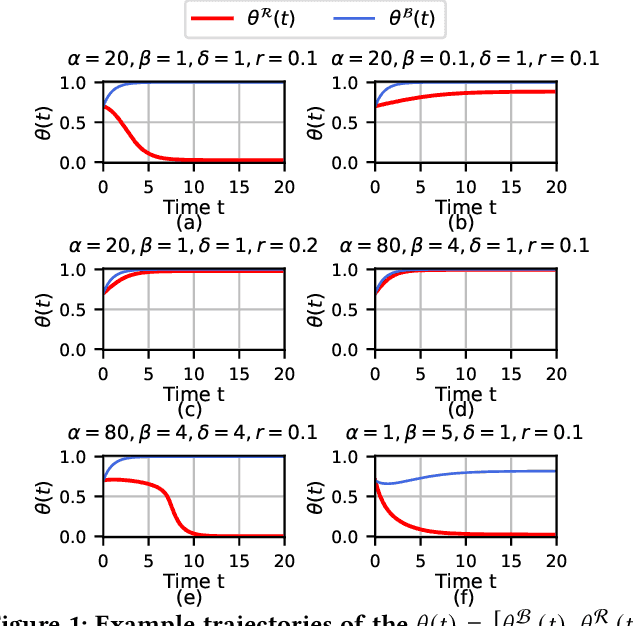
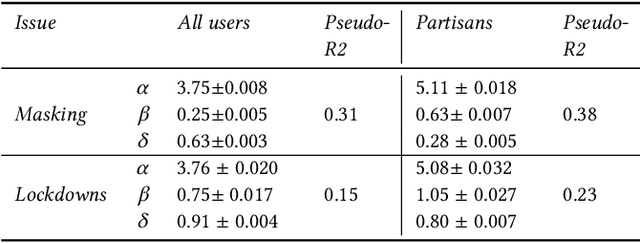
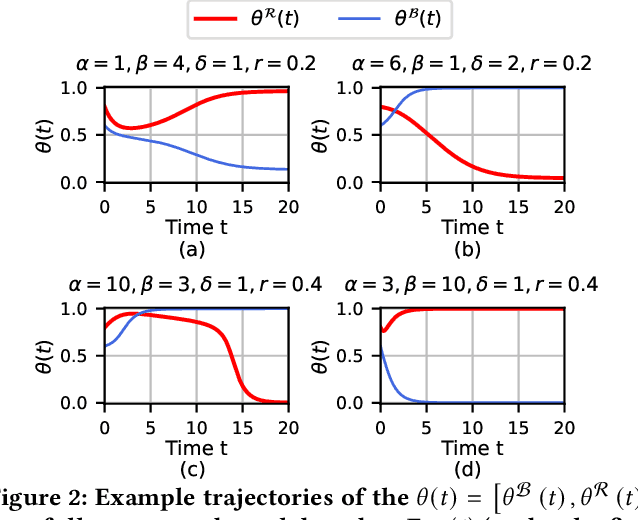
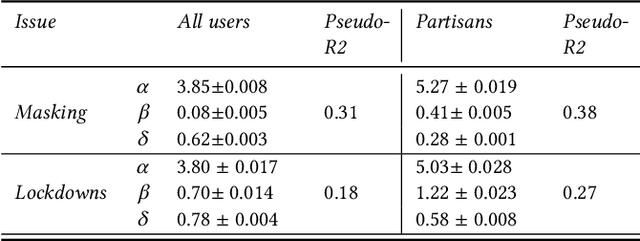
Affective polarization, the emotional divide between ideological groups marked by in-group love and out-group hate, has intensified in the United States, driving contentious issues like masking and lockdowns during the COVID-19 pandemic. Despite its societal impact, existing models of opinion change fail to account for emotional dynamics nor offer methods to quantify affective polarization robustly and in real-time. In this paper, we introduce a discrete choice model that captures decision-making within affectively polarized social networks and propose a statistical inference method estimate key parameters -- in-group love and out-group hate -- from social media data. Through empirical validation from online discussions about the COVID-19 pandemic, we demonstrate that our approach accurately captures real-world polarization dynamics and explains the rapid emergence of a partisan gap in attitudes towards masking and lockdowns. This framework allows for tracking affective polarization across contentious issues has broad implications for fostering constructive online dialogues in digital spaces.
Assessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
Estimating Causal Effects of Text Interventions Leveraging LLMs
Oct 28, 2024Quantifying the effect of textual interventions in social systems, such as reducing anger in social media posts to see its impact on engagement, poses significant challenges. Direct interventions on real-world systems are often infeasible, necessitating reliance on observational data. Traditional causal inference methods, typically designed for binary or discrete treatments, are inadequate for handling the complex, high-dimensional nature of textual data. This paper addresses these challenges by proposing a novel approach, CausalDANN, to estimate causal effects using text transformations facilitated by large language models (LLMs). Unlike existing methods, our approach accommodates arbitrary textual interventions and leverages text-level classifiers with domain adaptation ability to produce robust effect estimates against domain shifts, even when only the control group is observed. This flexibility in handling various text interventions is a key advancement in causal estimation for textual data, offering opportunities to better understand human behaviors and develop effective policies within social systems.