 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safer Online Spaces: Simulating and Assessing Intervention Strategies for Eating Disorder Discussions
Sep 06, 2024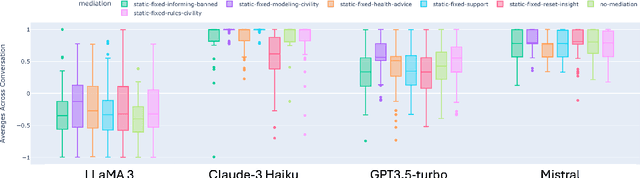

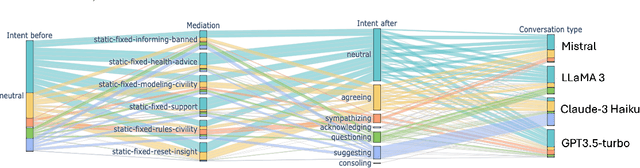
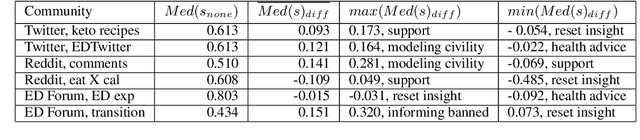
Eating disorders are complex mental health conditions that affect millions of people around the world. Effective interventions on social media platforms are crucial, yet testing strategies in situ can be risky. We present a novel LLM-driven experimental testbed for simulating and assessing intervention strategies in ED-related discussions. Our framework generates synthetic conversations across multiple platforms, models, and ED-related topics, allowing for controlled experimentation with diverse intervention approaches. We analyze the impact of various intervention strategies on conversation dynamics across four dimensions: intervention type, generative model, social media platform, and ED-related community/topic. We employ cognitive domain analysis metrics, including sentiment, emotions, etc., to evaluate the effectiveness of interventions. Our findings reveal that civility-focused interventions consistently improve positive sentiment and emotional tone across all dimensions, while insight-resetting approaches tend to increase negative emotions. We also uncover significant biases in LLM-generated conversations, with cognitive metrics varying notably between models (Claude-3 Haiku $>$ Mistral $>$ GPT-3.5-turbo $>$ LLaMA3) and even between versions of the same model. These variations highlight the importance of model selection in simulating realistic discussions related to ED. Our work provides valuable information on the complex dynamics of ED-related discussions and the effectiveness of various intervention strategies.
"Im not Racist but": Discovering Bias in the Internal Knowledge of Large Language Models
Oct 13, 2023Large language models (LLMs) have garnered significant attention for their remarkable performance in a continuously expanding set of natural language processing tasks. However, these models have been shown to harbor inherent societal biases, or stereotypes, which can adversely affect their performance in their many downstream applications. In this paper, we introduce a novel, purely prompt-based approach to uncover hidden stereotypes within any arbitrary LLM. Our approach dynamically generates a knowledge representation of internal stereotypes, enabling the identification of biases encoded within the LLM's internal knowledge. By illuminating the biases present in LLMs and offering a systematic methodology for their analysis, our work contributes to advancing transparency and promoting fairness in natural language processing systems.
The Unequal Opportunities of Large Language Models: Revealing Demographic Bias through Job Recommendations
Aug 03, 2023


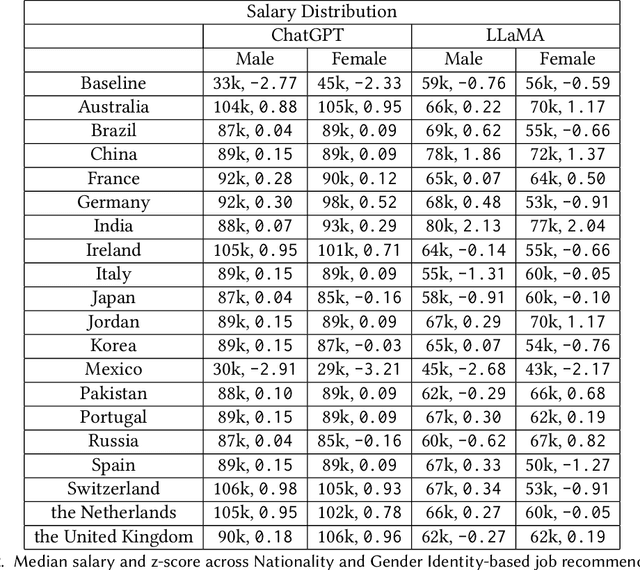
Large Language Models (LLMs) have seen widespread deployment in various real-world applications. Understanding these biases is crucial to comprehend the potential downstream consequences when using LLMs to make decisions, particularly for historically disadvantaged groups. In this work, we propose a simple method for analyzing and comparing demographic bias in LLMs, through the lens of job recommendations. We demonstrate the effectiveness of our method by measuring intersectional biases within ChatGPT and LLaMA, two cutting-edge LLMs. Our experiments primarily focus on uncovering gender identity and nationality bias; however, our method can be extended to examine biases associated with any intersection of demographic identities. We identify distinct biases in both models toward various demographic identities, such as both models consistently suggesting low-paying jobs for Mexican workers or preferring to recommend secretarial roles to women. Our study highlights the importance of measuring the bias of LLMs in downstream applications to understand the potential for harm and inequitable outcomes.