 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025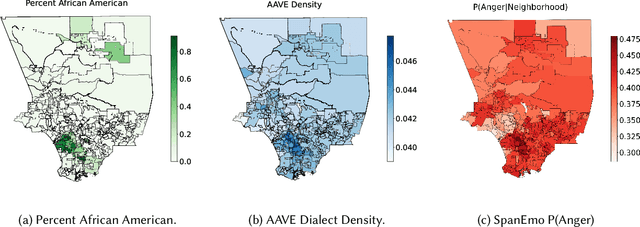
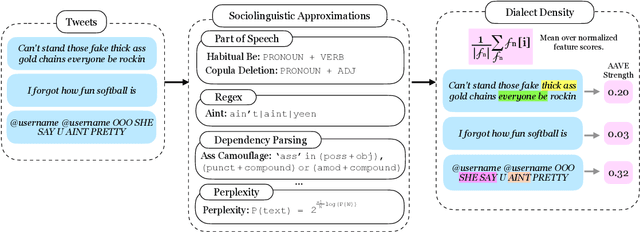
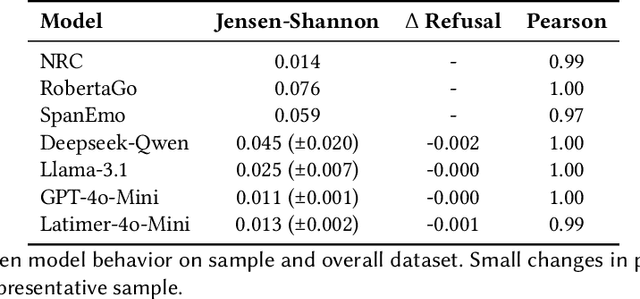

Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
Characterizing Network Structure of Anti-Trans Actors on TikTok
Jan 27, 2025The recent proliferation of short form video social media sites such as TikTok has been effectively utilized for increased visibility, communication, and community connection amongst trans/nonbinary creators online. However, these same platforms have also been exploited by right-wing actors targeting trans/nonbinary people, enabling such anti-trans actors to efficiently spread hate speech and propaganda. Given these divergent groups, what are the differences in network structure between anti-trans and pro-trans communities on TikTok, and to what extent do they amplify the effects of anti-trans content? In this paper, we collect a sample of TikTok videos containing pro and anti-trans content, and develop a taxonomy of trans related sentiment to enable the classification of content on TikTok, and ultimately analyze the reply network structures of pro-trans and anti-trans communities. In order to accomplish this, we worked with hired expert data annotators from the trans/nonbinary community in order to generate a sample of highly accurately labeled data. From this subset, we utilized a novel classification pipeline leveraging Retrieval-Augmented Generation (RAG) with annotated examples and taxonomy definitions to classify content into pro-trans, anti-trans, or neutral categories. We find that incorporating our taxonomy and its logics into our classification engine results in improved ability to differentiate trans related content, and that Results from network analysis indicate many interactions between posters of pro-trans and anti-trans content exist, further demonstrating targeting of trans individuals, and demonstrating the need for better content moderation tools
Hybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Estimating Causal Effects of Text Interventions Leveraging LLMs
Oct 28, 2024Quantifying the effect of textual interventions in social systems, such as reducing anger in social media posts to see its impact on engagement, poses significant challenges. Direct interventions on real-world systems are often infeasible, necessitating reliance on observational data. Traditional causal inference methods, typically designed for binary or discrete treatments, are inadequate for handling the complex, high-dimensional nature of textual data. This paper addresses these challenges by proposing a novel approach, CausalDANN, to estimate causal effects using text transformations facilitated by large language models (LLMs). Unlike existing methods, our approach accommodates arbitrary textual interventions and leverages text-level classifiers with domain adaptation ability to produce robust effect estimates against domain shifts, even when only the control group is observed. This flexibility in handling various text interventions is a key advancement in causal estimation for textual data, offering opportunities to better understand human behaviors and develop effective policies within social systems.
Artificial Intuition: Efficient Classification of Scientific Abstracts
Jul 08, 2024



It is desirable to coarsely classify short scientific texts, such as grant or publication abstracts, for strategic insight or research portfolio management. These texts efficiently transmit dense information to experts possessing a rich body of knowledge to aid interpretation. Yet this task is remarkably difficult to automate because of brevity and the absence of context. To address this gap, we have developed a novel approach to generate and appropriately assign coarse domain-specific labels. We show that a Large Language Model (LLM) can provide metadata essential to the task, in a process akin to the augmentation of supplemental knowledge representing human intuition, and propose a workflow. As a pilot study, we use a corpus of award abstracts from the National Aeronautics and Space Administration (NASA). We develop new assessment tools in concert with established performance metrics.
UniPlane: Unified Plane Detection and Reconstruction from Posed Monocular Videos
Jul 04, 2024We present UniPlane, a novel method that unifies plane detection and reconstruction from posed monocular videos. Unlike existing methods that detect planes from local observations and associate them across the video for the final reconstruction, UniPlane unifies both the detection and the reconstruction tasks in a single network, which allows us to directly optimize final reconstruction quality and fully leverage temporal information. Specifically, we build a Transformers-based deep neural network that jointly constructs a 3D feature volume for the environment and estimates a set of per-plane embeddings as queries. UniPlane directly reconstructs the 3D planes by taking dot products between voxel embeddings and the plane embeddings followed by binary thresholding. Extensive experiments on real-world datasets demonstrate that UniPlane outperforms state-of-the-art methods in both plane detection and reconstruction tasks, achieving +4.6 in F-score in geometry as well as consistent improvements in other geometry and segmentation metrics.
OrientDream: Streamlining Text-to-3D Generation with Explicit Orientation Control
Jun 14, 2024



In the evolving landscape of text-to-3D technology, Dreamfusion has showcased its proficiency by utilizing Score Distillation Sampling (SDS) to optimize implicit representations such as NeRF. This process is achieved through the distillation of pretrained large-scale text-to-image diffusion models. However, Dreamfusion encounters fidelity and efficiency constraints: it faces the multi-head Janus issue and exhibits a relatively slow optimization process. To circumvent these challenges, we introduce OrientDream, a camera orientation conditioned framework designed for efficient and multi-view consistent 3D generation from textual prompts. Our strategy emphasizes the implementation of an explicit camera orientation conditioned feature in the pre-training of a 2D text-to-image diffusion module. This feature effectively utilizes data from MVImgNet, an extensive external multi-view dataset, to refine and bolster its functionality. Subsequently, we utilize the pre-conditioned 2D images as a basis for optimizing a randomly initialized implicit representation (NeRF). This process is significantly expedited by a decoupled back-propagation technique, allowing for multiple updates of implicit parameters per optimization cycle. Our experiments reveal that our method not only produces high-quality NeRF models with consistent multi-view properties but also achieves an optimization speed significantly greater than existing methods, as quantified by comparative metrics.
Harmful Speech Detection by Language Models Exhibits Gender-Queer Dialect Bias
May 23, 2024Content moderation on social media platforms shapes the dynamics of online discourse, influencing whose voices are amplified and whose are suppressed. Recent studies have raised concerns about the fairness of content moderation practices, particularly for aggressively flagging posts from transgender and non-binary individuals as toxic. In this study, we investigate the presence of bias in harmful speech classification of gender-queer dialect online, focusing specifically on the treatment of reclaimed slurs. We introduce a novel dataset, QueerReclaimLex, based on 109 curated templates exemplifying non-derogatory uses of LGBTQ+ slurs. Dataset instances are scored by gender-queer annotators for potential harm depending on additional context about speaker identity. We systematically evaluate the performance of five off-the-shelf language models in assessing the harm of these texts and explore the effectiveness of chain-of-thought prompting to teach large language models (LLMs) to leverage author identity context. We reveal a tendency for these models to inaccurately flag texts authored by gender-queer individuals as harmful. Strikingly, across all LLMs the performance is poorest for texts that show signs of being written by individuals targeted by the featured slur (F1 <= 0.24). We highlight an urgent need for fairness and inclusivity in content moderation systems. By uncovering these biases, this work aims to inform the development of more equitable content moderation practices and contribute to the creation of inclusive online spaces for all users.
Offset Unlearning for Large Language Models
Apr 17, 2024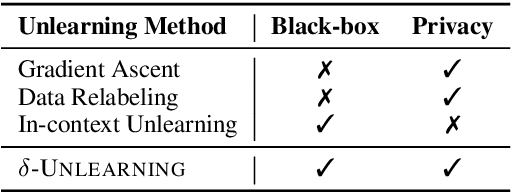

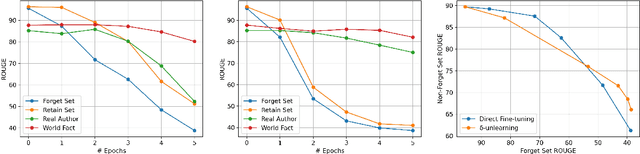
Despite the strong capabilities of Large Language Models (LLMs) to acquire knowledge from their training corpora, the memorization of sensitive information in the corpora such as copyrighted, harmful, and private content has led to ethical and legal concerns. In response to these challenges, unlearning has emerged as a potential remedy for LLMs affected by problematic training data. However, previous unlearning techniques are either not applicable to black-box LLMs due to required access to model internal weights, or violate data protection principles by retaining sensitive data for inference-time correction. We propose $\delta$-unlearning, an offset unlearning framework for black-box LLMs. Instead of tuning the black-box LLM itself, $\delta$-unlearning learns the logit offset needed for unlearning by contrasting the logits from a pair of smaller models. Experiments demonstrate that $\delta$-unlearning can effectively unlearn target data while maintaining similar or even stronger performance on general out-of-forget-scope tasks. $\delta$-unlearning also effectively incorporates different unlearning algorithms, making our approach a versatile solution to adapting various existing unlearning algorithms to black-box LLMs.
Secret Keepers: The Impact of LLMs on Linguistic Markers of Personal Traits
Apr 03, 2024



Prior research has established associations between individuals' language usage and their personal traits; our linguistic patterns reveal information about our personalities, emotional states, and beliefs. However, with the increasing adoption of Large Language Models (LLMs) as writing assistants in everyday writing, a critical question emerges: are authors' linguistic patterns still predictive of their personal traits when LLMs are involved in the writing process? We investigate the impact of LLMs on the linguistic markers of demographic and psychological traits, specifically examining three LLMs - GPT3.5, Llama 2, and Gemini - across six different traits: gender, age, political affiliation, personality, empathy, and morality. Our findings indicate that although the use of LLMs slightly reduces the predictive power of linguistic patterns over authors' personal traits, the significant changes are infrequent, and the use of LLMs does not fully diminish the predictive power of authors' linguistic patterns over their personal traits. We also note that some theoretically established lexical-based linguistic markers lose their reliability as predictors when LLMs are used in the writing process. Our findings have important implications for the study of linguistic markers of personal traits in the age of LLMs.