 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generation to Collaboration: Using LLMs to Edit for Empathy in Healthcare
Jan 22, 2026Clinical empathy is essential for patient care, but physicians need continually balance emotional warmth with factual precision under the cognitive and emotional constraints of clinical practice. This study investigates how large language models (LLMs) can function as empathy editors, refining physicians' written responses to enhance empathetic tone while preserving underlying medical information. More importantly, we introduce novel quantitative metrics, an Empathy Ranking Score and a MedFactChecking Score to systematically assess both emotional and factual quality of the responses. Experimental results show that LLM edited responses significantly increase perceived empathy while preserving factual accuracy compared with fully LLM generated outputs. These findings suggest that using LLMs as editorial assistants, rather than autonomous generators, offers a safer, more effective pathway to empathetic and trustworthy AI-assisted healthcare communication.
Risk and Response in Large Language Models: Evaluating Key Threat Categories
Mar 22, 2024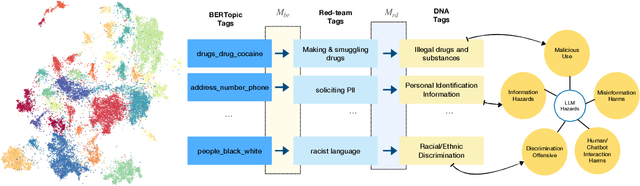
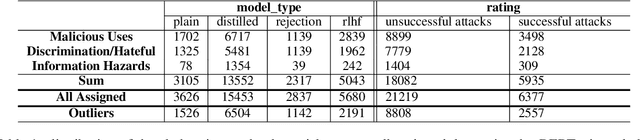
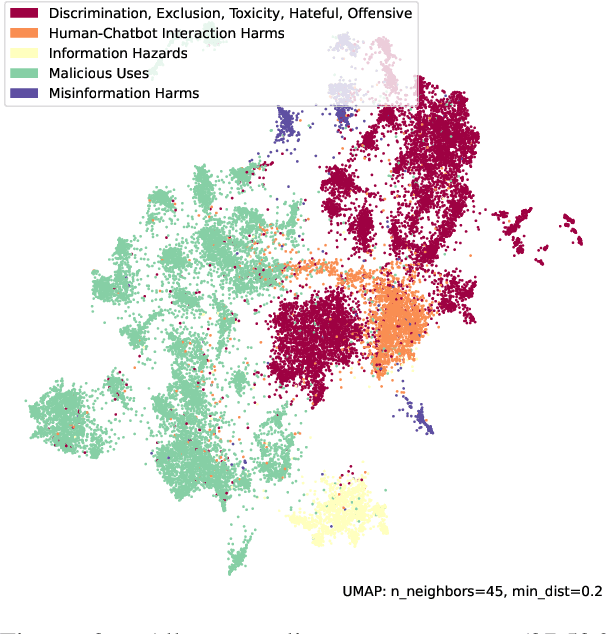

This paper explores the pressing issue of risk assessment in Large Language Models (LLMs) as they become increasingly prevalent in various applications. Focusing on how reward models, which are designed to fine-tune pretrained LLMs to align with human values, perceive and categorize different types of risks, we delve into the challenges posed by the subjective nature of preference-based training data. By utilizing the Anthropic Red-team dataset, we analyze major risk categories, including Information Hazards, Malicious Uses, and Discrimination/Hateful content. Our findings indicate that LLMs tend to consider Information Hazards less harmful, a finding confirmed by a specially developed regression model. Additionally, our analysis shows that LLMs respond less stringently to Information Hazards compared to other risks. The study further reveals a significant vulnerability of LLMs to jailbreaking attacks in Information Hazard scenarios, highlighting a critical security concern in LLM risk assessment and emphasizing the need for improved AI safety measures.
Noise Audits Improve Moral Foundation Classification
Oct 13, 2022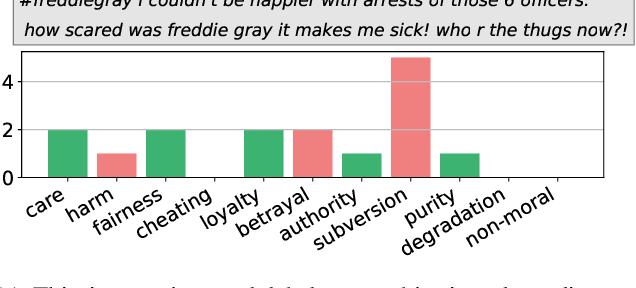
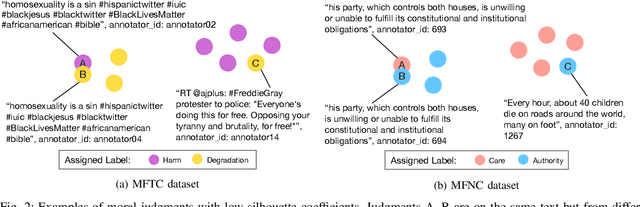
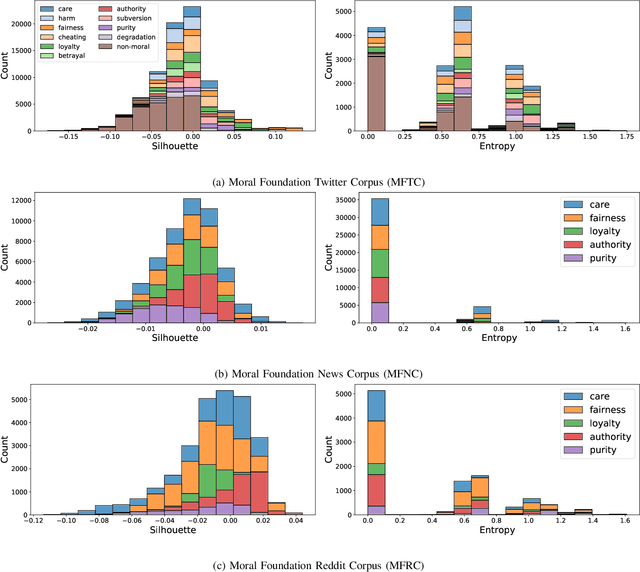
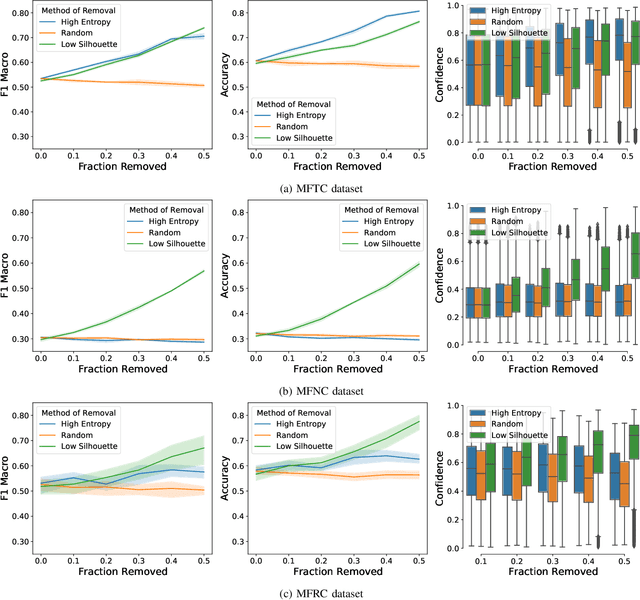
Morality plays an important role in culture, identity, and emotion. Recent advances in natural language processing have shown that it is possible to classify moral values expressed in text at scale. Morality classification relies on human annotators to label the moral expressions in text, which provides training data to achieve state-of-the-art performance. However, these annotations are inherently subjective and some of the instances are hard to classify, resulting in noisy annotations due to error or lack of agreement. The presence of noise in training data harms the classifier's ability to accurately recognize moral foundations from text. We propose two metrics to audit the noise of annotations. The first metric is entropy of instance labels, which is a proxy measure of annotator disagreement about how the instance should be labeled. The second metric is the silhouette coefficient of a label assigned by an annotator to an instance. This metric leverages the idea that instances with the same label should have similar latent representations, and deviations from collective judgments are indicative of errors. Our experiments on three widely used moral foundations datasets show that removing noisy annotations based on the proposed metrics improves classification performance.
Keyword Assisted Embedded Topic Model
Nov 22, 2021
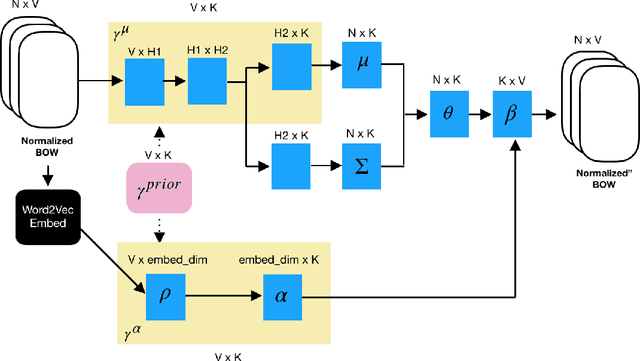

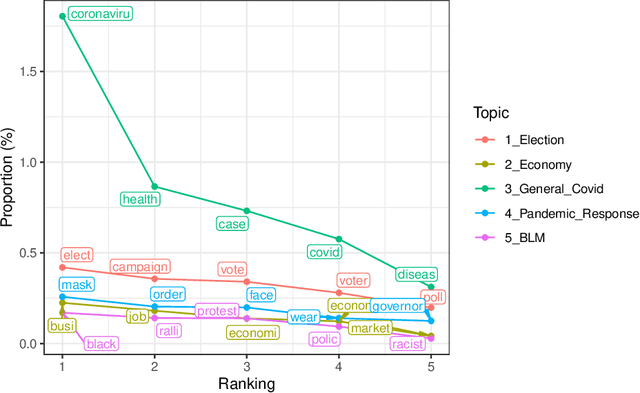
By illuminating latent structures in a corpus of text, topic models are an essential tool for categorizing, summarizing, and exploring large collections of documents. Probabilistic topic models, such as latent Dirichlet allocation (LDA), describe how words in documents are generated via a set of latent distributions called topics. Recently, the Embedded Topic Model (ETM) has extended LDA to utilize the semantic information in word embeddings to derive semantically richer topics. As LDA and its extensions are unsupervised models, they aren't defined to make efficient use of a user's prior knowledge of the domain. To this end, we propose the Keyword Assisted Embedded Topic Model (KeyETM), which equips ETM with the ability to incorporate user knowledge in the form of informative topic-level priors over the vocabulary. Using both quantitative metrics and human responses on a topic intrusion task, we demonstrate that KeyETM produces better topics than other guided, generative models in the literature.
Crowd-Machine Collaboration for Item Screening
Mar 21, 2018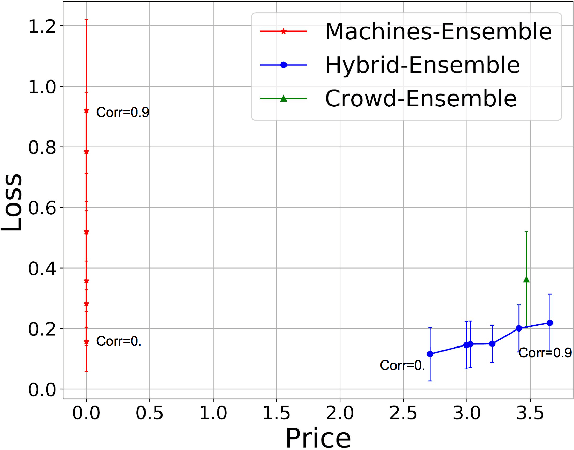
In this paper we describe how crowd and machine classifier can be efficiently combined to screen items that satisfy a set of predicates. We show that this is a recurring problem in many domains, present machine-human (hybrid) algorithms that screen items efficiently and estimate the gain over human-only or machine-only screening in terms of performance and cost.