 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Audits Improve Moral Foundation Classification
Paper and Code
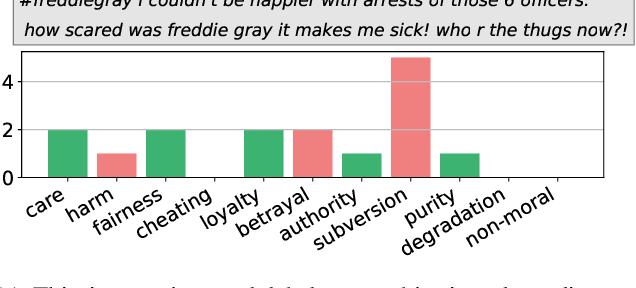
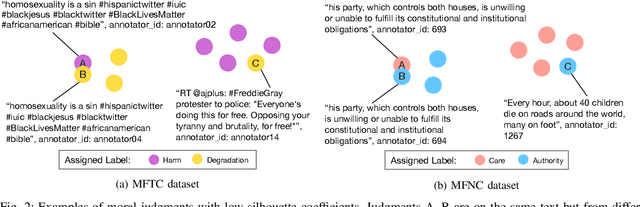
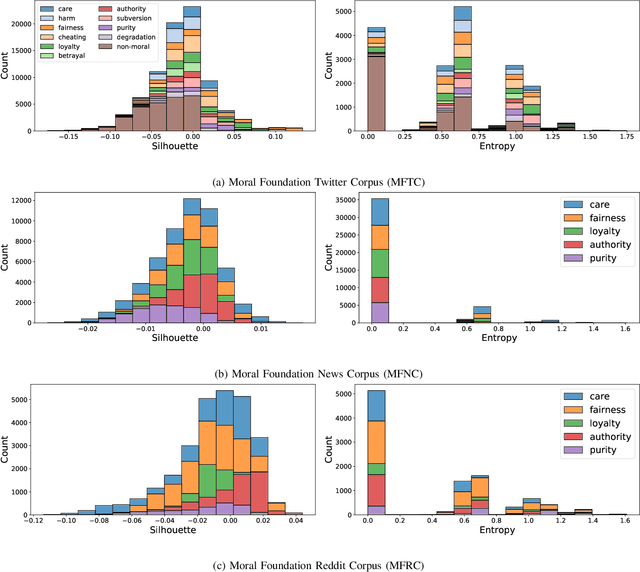
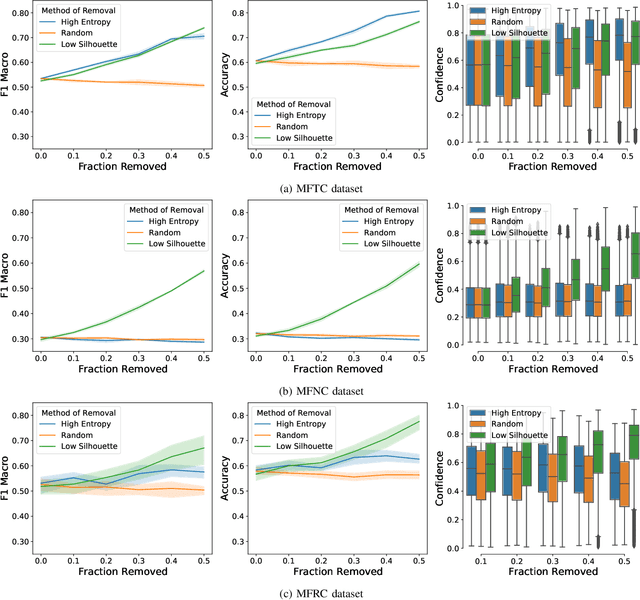
Morality plays an important role in culture, identity, and emotion. Recent advances in natural language processing have shown that it is possible to classify moral values expressed in text at scale. Morality classification relies on human annotators to label the moral expressions in text, which provides training data to achieve state-of-the-art performance. However, these annotations are inherently subjective and some of the instances are hard to classify, resulting in noisy annotations due to error or lack of agreement. The presence of noise in training data harms the classifier's ability to accurately recognize moral foundations from text. We propose two metrics to audit the noise of annotations. The first metric is entropy of instance labels, which is a proxy measure of annotator disagreement about how the instance should be labeled. The second metric is the silhouette coefficient of a label assigned by an annotator to an instance. This metric leverages the idea that instances with the same label should have similar latent representations, and deviations from collective judgments are indicative of errors. Our experiments on three widely used moral foundations datasets show that removing noisy annotations based on the proposed metrics improves classification performance.