 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Analysis of Base Model Choice for Reward Modeling
May 16, 2025Reinforcement learning from human feedback (RLHF) and, at its core, reward modeling have become a crucial part of training powerful large language models (LLMs). One commonly overlooked factor in training high-quality reward models (RMs) is the effect of the base model, which is becoming more challenging to choose given the rapidly growing pool of LLMs. In this work, we present a systematic analysis of the effect of base model selection on reward modeling performance. Our results show that the performance can be improved by up to 14% compared to the most common (i.e., default) choice. Moreover, we showcase the strong statistical relation between some existing benchmarks and downstream performances. We also demonstrate that the results from a small set of benchmarks could be combined to boost the model selection ($+$18% on average in the top 5-10). Lastly, we illustrate the impact of different post-training steps on the final performance and explore using estimated data distributions to reduce performance prediction error.
KULCQ: An Unsupervised Keyword-based Utterance Level Clustering Quality Metric
Nov 15, 2024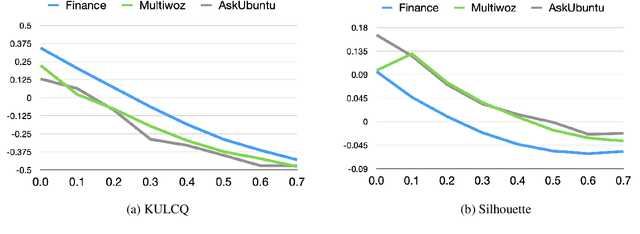


Intent discovery is crucial for both building new conversational agents and improving existing ones. While several approaches have been proposed for intent discovery, most rely on clustering to group similar utterances together. Traditional evaluation of these utterance clusters requires intent labels for each utterance, limiting scalability. Although some clustering quality metrics exist that do not require labeled data, they focus solely on cluster geometry while ignoring the linguistic nuances present in conversational transcripts. In this paper, we introduce Keyword-based Utterance Level Clustering Quality (KULCQ), an unsupervised metric that leverages keyword analysis to evaluate clustering quality. We demonstrate KULCQ's effectiveness by comparing it with existing unsupervised clustering metrics and validate its performance through comprehensive ablation studies. Our results show that KULCQ better captures semantic relationships in conversational data while maintaining consistency with geometric clustering principles.
Don't Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations
Mar 06, 2024Researchers have raised awareness about the harms of aggregating labels especially in subjective tasks that naturally contain disagreements among human annotators. In this work we show that models that are only provided aggregated labels show low confidence on high-disagreement data instances. While previous studies consider such instances as mislabeled, we argue that the reason the high-disagreement text instances have been hard-to-learn is that the conventional aggregated models underperform in extracting useful signals from subjective tasks. Inspired by recent studies demonstrating the effectiveness of learning from raw annotations, we investigate classifying using Multiple Ground Truth (Multi-GT) approaches. Our experiments show an improvement of confidence for the high-disagreement instances.
Reading Between the Tweets: Deciphering Ideological Stances of Interconnected Mixed-Ideology Communities
Feb 02, 2024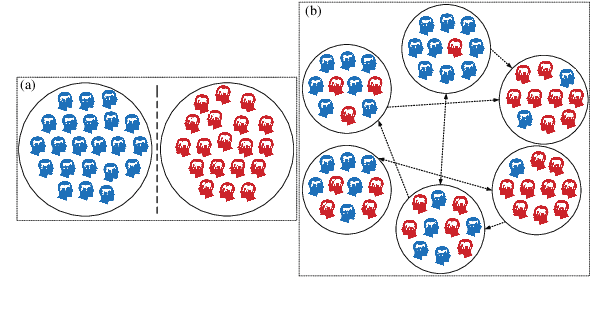
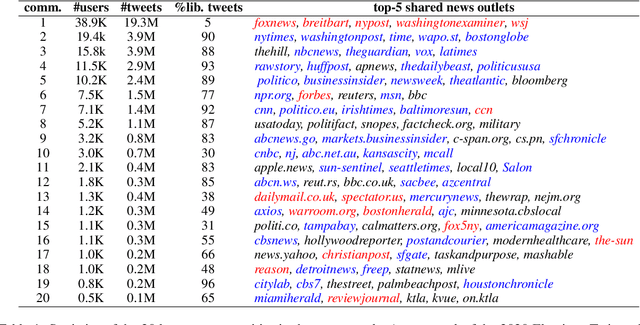
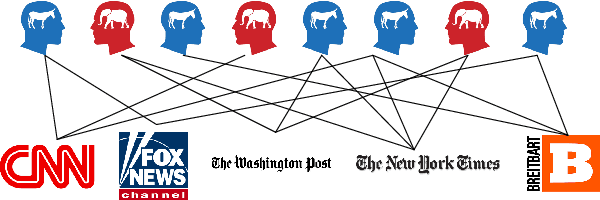
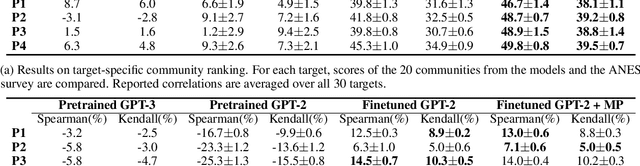
Recent advances in NLP have improved our ability to understand the nuanced worldviews of online communities. Existing research focused on probing ideological stances treats liberals and conservatives as separate groups. However, this fails to account for the nuanced views of the organically formed online communities and the connections between them. In this paper, we study discussions of the 2020 U.S. election on Twitter to identify complex interacting communities. Capitalizing on this interconnectedness, we introduce a novel approach that harnesses message passing when finetuning language models (LMs) to probe the nuanced ideologies of these communities. By comparing the responses generated by LMs and real-world survey results, our method shows higher alignment than existing baselines, highlighting the potential of using LMs in revealing complex ideologies within and across interconnected mixed-ideology communities.
Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Nov 16, 2023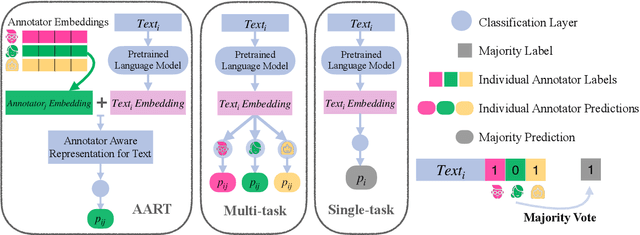
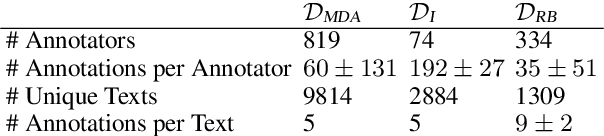
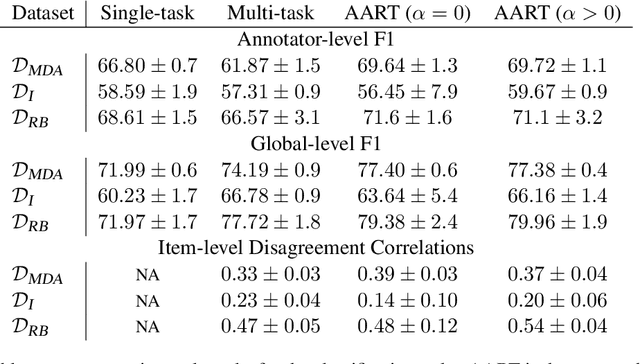
In most classification models, it has been assumed to have a single ground truth label for each data point. However, subjective tasks like toxicity classification can lead to genuine disagreement among annotators. In these cases aggregating labels will result in biased labeling and, consequently, biased models that can overlook minority opinions. Previous studies have shed light on the pitfalls of label aggregation and have introduced a handful of practical approaches to tackle this issue. Recently proposed multi-annotator models, which predict labels individually per annotator, are vulnerable to under-determination for annotators with small samples. This problem is especially the case in crowd-sourced datasets. In this work, we propose Annotator Aware Representations for Texts (AART) for subjective classification tasks. We will show the improvement of our method on metrics that assess the performance on capturing annotators' perspectives. Additionally, our approach involves learning representations for annotators, allowing for an exploration of the captured annotation behaviors.
A Data Fusion Framework for Multi-Domain Morality Learning
Apr 04, 2023Language models can be trained to recognize the moral sentiment of text, creating new opportunities to study the role of morality in human life. As interest in language and morality has grown, several ground truth datasets with moral annotations have been released. However, these datasets vary in the method of data collection, domain, topics, instructions for annotators, etc. Simply aggregating such heterogeneous datasets during training can yield models that fail to generalize well. We describe a data fusion framework for training on multiple heterogeneous datasets that improve performance and generalizability. The model uses domain adversarial training to align the datasets in feature space and a weighted loss function to deal with label shift. We show that the proposed framework achieves state-of-the-art performance in different datasets compared to prior works in morality inference.
Noise Audits Improve Moral Foundation Classification
Oct 13, 2022
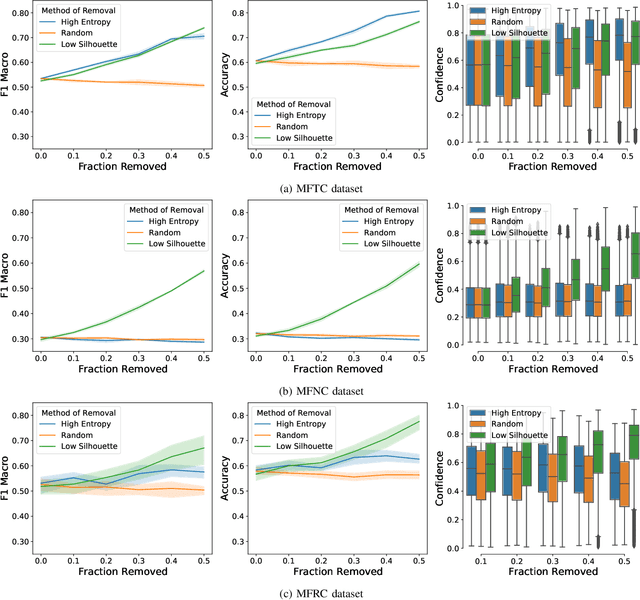
Morality plays an important role in culture, identity, and emotion. Recent advances in natural language processing have shown that it is possible to classify moral values expressed in text at scale. Morality classification relies on human annotators to label the moral expressions in text, which provides training data to achieve state-of-the-art performance. However, these annotations are inherently subjective and some of the instances are hard to classify, resulting in noisy annotations due to error or lack of agreement. The presence of noise in training data harms the classifier's ability to accurately recognize moral foundations from text. We propose two metrics to audit the noise of annotations. The first metric is entropy of instance labels, which is a proxy measure of annotator disagreement about how the instance should be labeled. The second metric is the silhouette coefficient of a label assigned by an annotator to an instance. This metric leverages the idea that instances with the same label should have similar latent representations, and deviations from collective judgments are indicative of errors. Our experiments on three widely used moral foundations datasets show that removing noisy annotations based on the proposed metrics improves classification performance.
Infusing Knowledge from Wikipedia to Enhance Stance Detection
Apr 08, 2022
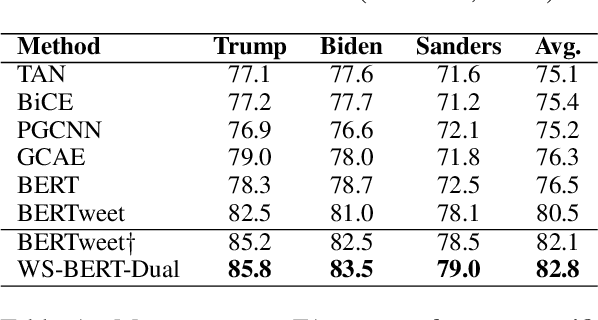
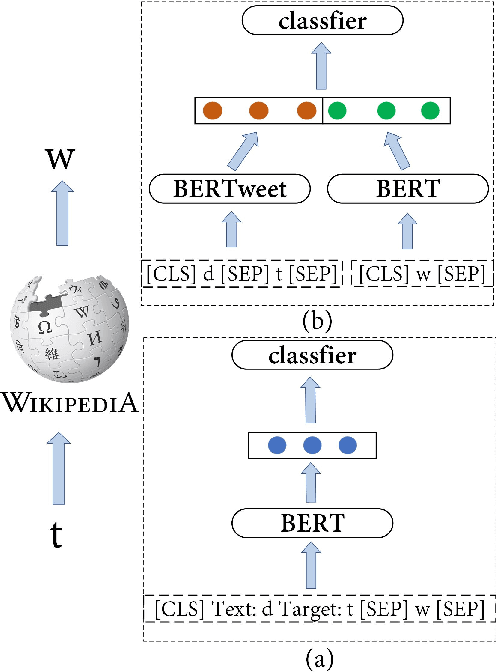
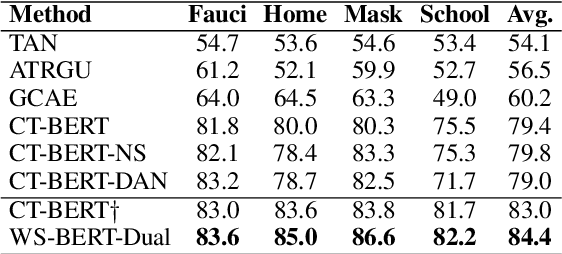
Stance detection infers a text author's attitude towards a target. This is challenging when the model lacks background knowledge about the target. Here, we show how background knowledge from Wikipedia can help enhance the performance on stance detection. We introduce Wikipedia Stance Detection BERT (WS-BERT) that infuses the knowledge into stance encoding. Extensive results on three benchmark datasets covering social media discussions and online debates indicate that our model significantly outperforms the state-of-the-art methods on target-specific stance detection, cross-target stance detection, and zero/few-shot stance detection.
Detecting Polarized Topics in COVID-19 News Using Partisanship-aware Contextualized Topic Embeddings
Apr 15, 2021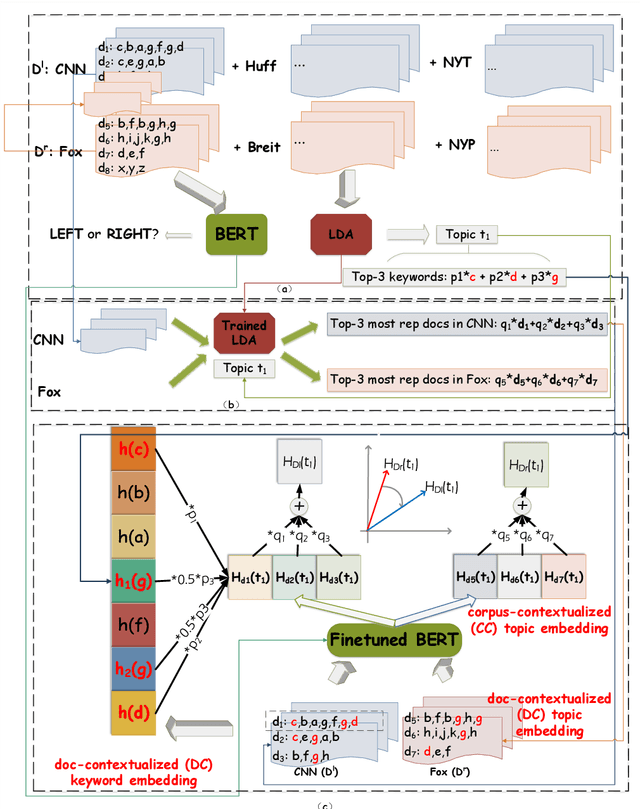

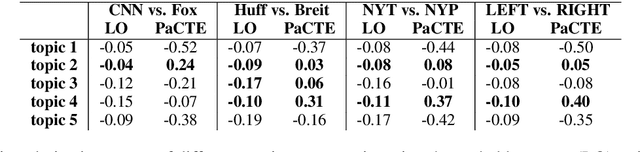
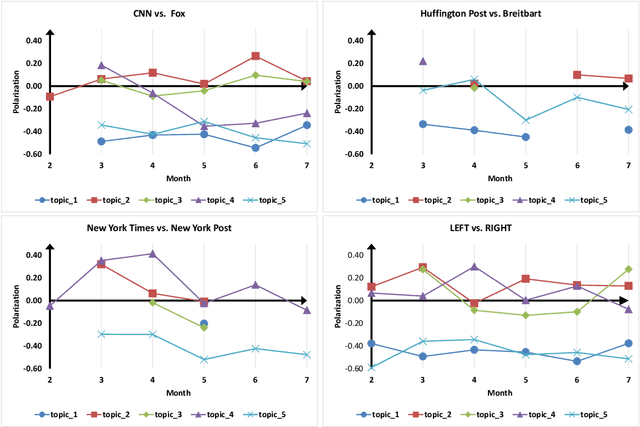
Growing polarization of the news media has been blamed for fanning disagreement, controversy and even violence. Early identification of polarized topics is thus an urgent matter that can help mitigate conflict. However, accurate measurement of polarization is still an open research challenge. To address this gap, we propose Partisanship-aware Contextualized Topic Embeddings (PaCTE), a method to automatically detect polarized topics from partisan news sources. Specifically, we represent the ideology of a news source on a topic by corpus-contextualized topic embedding utilizing a language model that has been finetuned on recognizing partisanship of the news articles, and measure the polarization between sources using cosine similarity. We apply our method to a corpus of news about COVID-19 pandemic. Extensive experiments on different news sources and topics demonstrate the effectiveness of our method to precisely capture the topical polarization and alignment between different news sources. To help clarify and validate results, we explain the polarization using the Moral Foundation Theory.
Challenges in Forecasting Malicious Events from Incomplete Data
Apr 06, 2020



The ability to accurately predict cyber-attacks would enable organizations to mitigate their growing threat and avert the financial losses and disruptions they cause. But how predictable are cyber-attacks? Researchers have attempted to combine external data -- ranging from vulnerability disclosures to discussions on Twitter and the darkweb -- with machine learning algorithms to learn indicators of impending cyber-attacks. However, successful cyber-attacks represent a tiny fraction of all attempted attacks: the vast majority are stopped, or filtered by the security appliances deployed at the target. As we show in this paper, the process of filtering reduces the predictability of cyber-attacks. The small number of attacks that do penetrate the target's defenses follow a different generative process compared to the whole data which is much harder to learn for predictive models. This could be caused by the fact that the resulting time series also depends on the filtering process in addition to all the different factors that the original time series depended on. We empirically quantify the loss of predictability due to filtering using real-world data from two organizations. Our work identifies the limits to forecasting cyber-attacks from highly filtered data.