 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Evaluation of Task-Oriented Dialogue Flows
Nov 15, 2024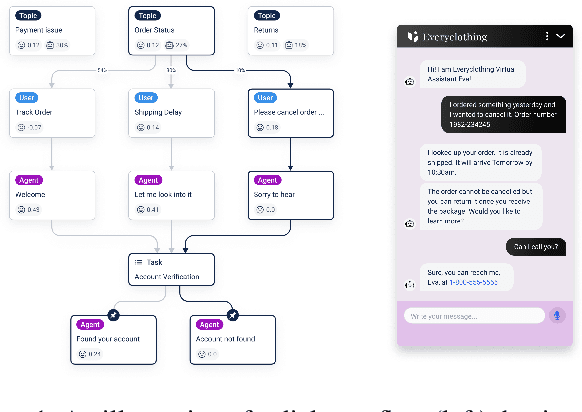
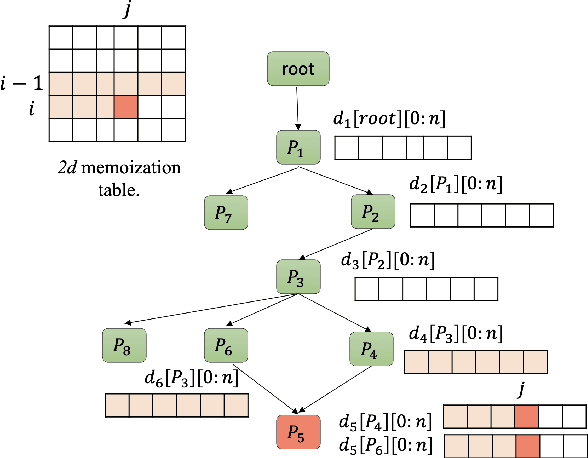
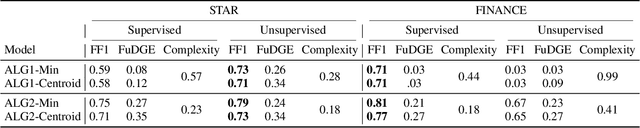
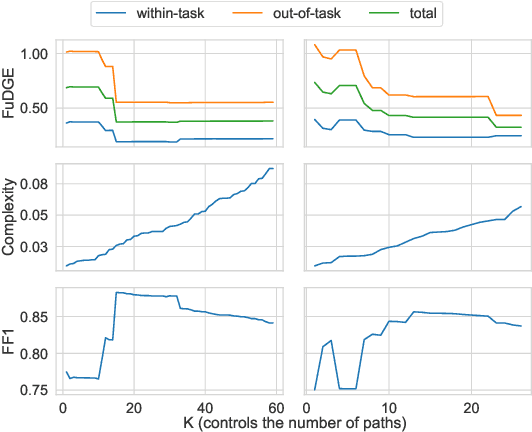
Task-oriented dialogue systems rely on predefined conversation schemes (dialogue flows) often represented as directed acyclic graphs. These flows can be manually designed or automatically generated from previously recorded conversations. Due to variations in domain expertise or reliance on different sets of prior conversations, these dialogue flows can manifest in significantly different graph structures. Despite their importance, there is no standard method for evaluating the quality of dialogue flows. We introduce FuDGE (Fuzzy Dialogue-Graph Edit Distance), a novel metric that evaluates dialogue flows by assessing their structural complexity and representational coverage of the conversation data. FuDGE measures how well individual conversations align with a flow and, consequently, how well a set of conversations is represented by the flow overall. Through extensive experiments on manually configured flows and flows generated by automated techniques, we demonstrate the effectiveness of FuDGE and its evaluation framework. By standardizing and optimizing dialogue flows, FuDGE enables conversational designers and automated techniques to achieve higher levels of efficiency and automation.
KULCQ: An Unsupervised Keyword-based Utterance Level Clustering Quality Metric
Nov 15, 2024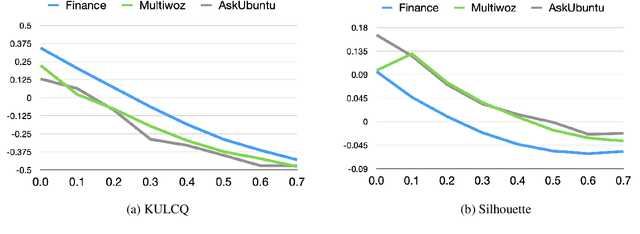


Intent discovery is crucial for both building new conversational agents and improving existing ones. While several approaches have been proposed for intent discovery, most rely on clustering to group similar utterances together. Traditional evaluation of these utterance clusters requires intent labels for each utterance, limiting scalability. Although some clustering quality metrics exist that do not require labeled data, they focus solely on cluster geometry while ignoring the linguistic nuances present in conversational transcripts. In this paper, we introduce Keyword-based Utterance Level Clustering Quality (KULCQ), an unsupervised metric that leverages keyword analysis to evaluate clustering quality. We demonstrate KULCQ's effectiveness by comparing it with existing unsupervised clustering metrics and validate its performance through comprehensive ablation studies. Our results show that KULCQ better captures semantic relationships in conversational data while maintaining consistency with geometric clustering principles.
Cognitive Homeostatic Agents
Feb 27, 2021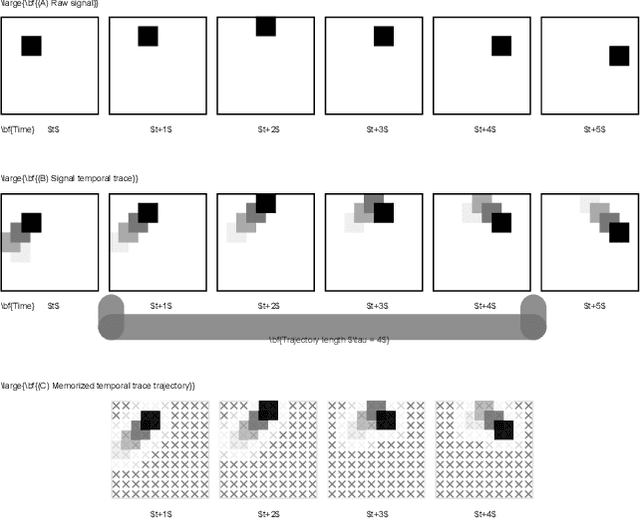
Human brain has been used as an inspiration for building autonomous agents, but it is not obvious what level of computational description of the brain one should use. This has led to overly opinionated symbolic approaches and overly unstructured connectionist approaches. We propose that using homeostasis as the computational description provides a good compromise. Similar to how physiological homeostasis is the regulation of certain homeostatic variables, cognition can be interpreted as the regulation of certain 'cognitive homeostatic variables'. We present an outline of a Cognitive Homeostatic Agent, built as a hierarchy of physiological and cognitive homeostatic subsystems and describe structures and processes to guide future exploration. We expect this to be a fruitful line of investigation towards building sophisticated artificial agents that can act flexibly in complex environments, and produce behaviors indicating planning, thinking and feelings.
Generation of complex database queries and API calls from natural language utterances
Dec 15, 2020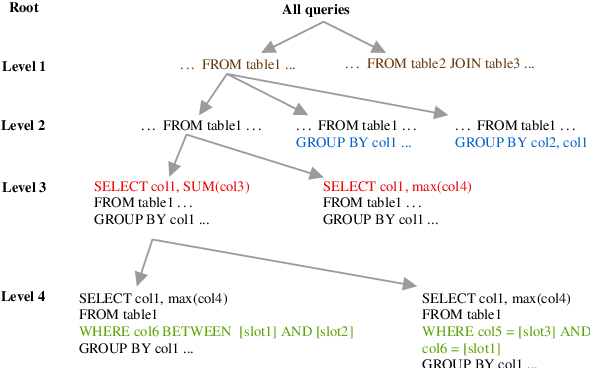
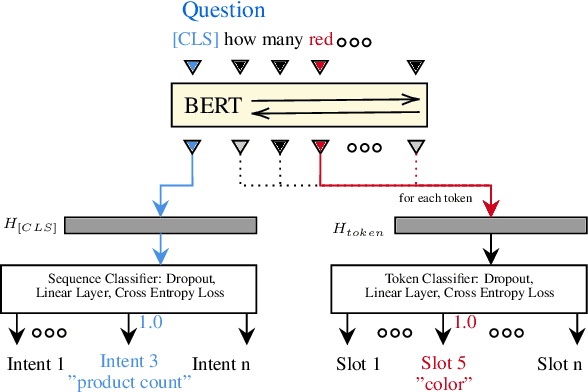
Generating queries corresponding to natural language questions is a long standing problem. Traditional methods lack language flexibility, while newer sequence-to-sequence models require large amount of data. Schema-agnostic sequence-to-sequence models can be fine-tuned for a specific schema using a small dataset but these models have relatively low accuracy. We present a method that transforms the query generation problem into an intent classification and slot filling problem. This method can work using small datasets. For questions similar to the ones in the training dataset, it produces complex queries with high accuracy. For other questions, it can use a template-based approach or predict query pieces to construct the queries, still at a higher accuracy than sequence-to-sequence models. On a real-world dataset, a schema fine-tuned state-of-the-art generative model had 60\% exact match accuracy for the query generation task, while our method resulted in 92\% exact match accuracy.
Bertrand-DR: Improving Text-to-SQL using a Discriminative Re-ranker
Feb 03, 2020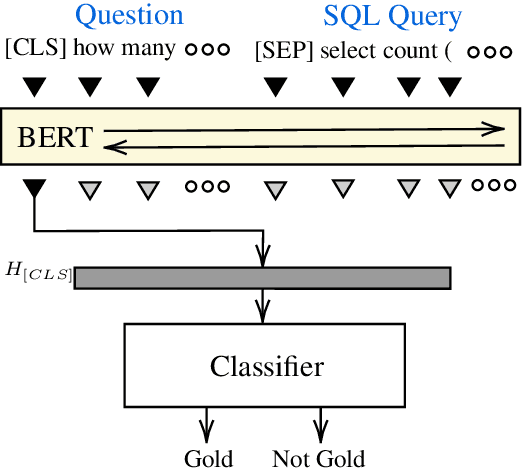
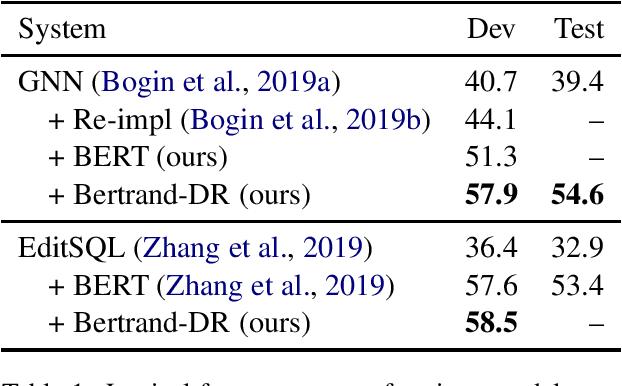
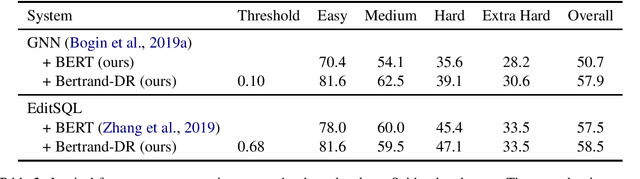
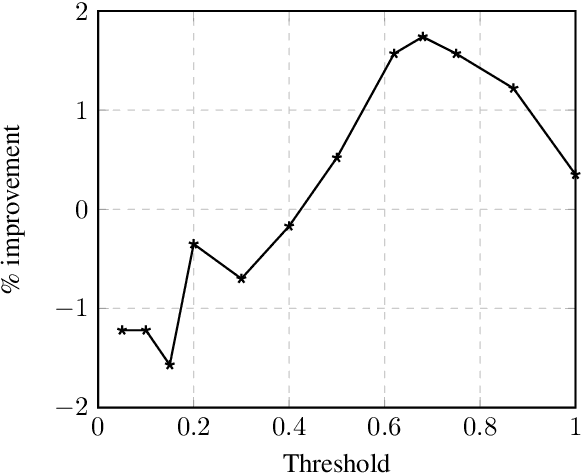
To access data stored in relational databases, users need to understand the database schema and write a query using a query language such as SQL. To simplify this task, text-to-SQL models attempt to translate a user's natural language question to corresponding SQL query. Recently, several generative text-to-SQL models have been developed. We propose a novel discriminative re-ranker to improve the performance of generative text-to-SQL models by extracting the best SQL query from the beam output predicted by the text-to-SQL generator, resulting in improved performance in the cases where the best query was in the candidate list, but not at the top of the list. We build the re-ranker as a schema agnostic BERT fine-tuned classifier. We analyze relative strengths of the text-to-SQL and re-ranker models across different query hardness levels, and suggest how to combine the two models for optimal performance. We demonstrate the effectiveness of the re-ranker by applying it to two state-of-the-art text-to-SQL models, and achieve top 4 score on the Spider leaderboard at the time of writing this article.