 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG based Question-Answering for Contextual Response Prediction System
Sep 05, 2024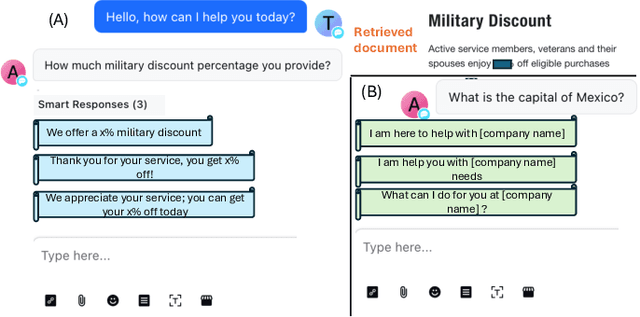
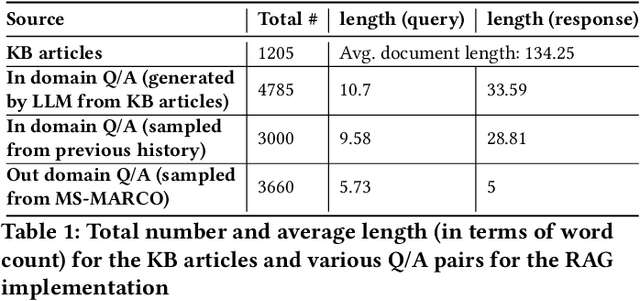
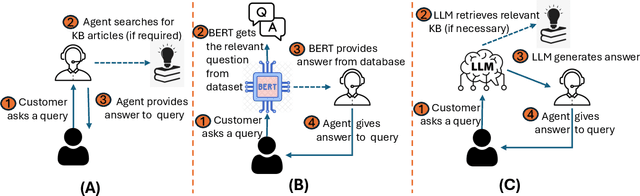
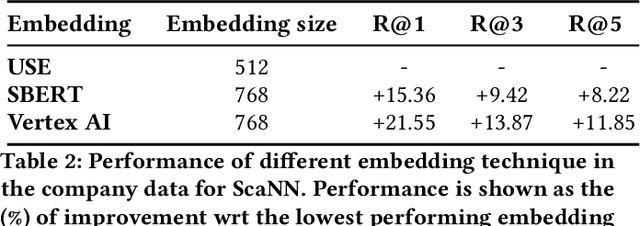
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
Bertrand-DR: Improving Text-to-SQL using a Discriminative Re-ranker
Feb 03, 2020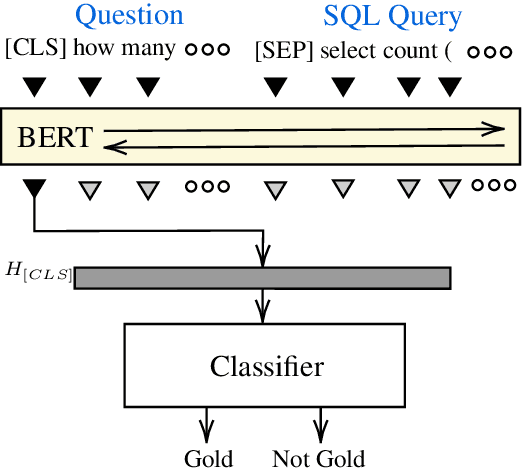
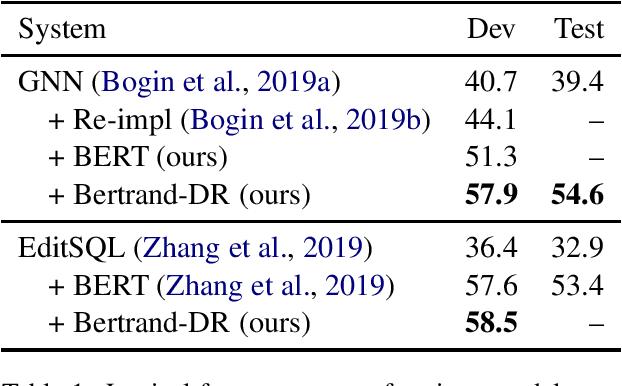
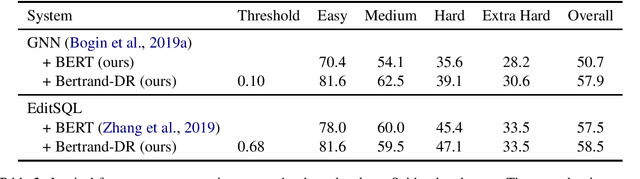
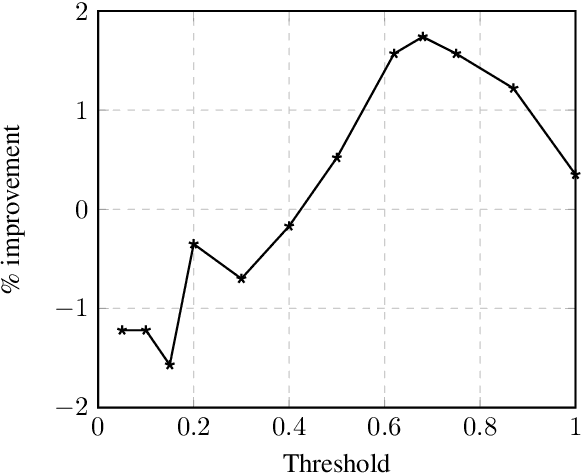
To access data stored in relational databases, users need to understand the database schema and write a query using a query language such as SQL. To simplify this task, text-to-SQL models attempt to translate a user's natural language question to corresponding SQL query. Recently, several generative text-to-SQL models have been developed. We propose a novel discriminative re-ranker to improve the performance of generative text-to-SQL models by extracting the best SQL query from the beam output predicted by the text-to-SQL generator, resulting in improved performance in the cases where the best query was in the candidate list, but not at the top of the list. We build the re-ranker as a schema agnostic BERT fine-tuned classifier. We analyze relative strengths of the text-to-SQL and re-ranker models across different query hardness levels, and suggest how to combine the two models for optimal performance. We demonstrate the effectiveness of the re-ranker by applying it to two state-of-the-art text-to-SQL models, and achieve top 4 score on the Spider leaderboard at the time of writing this article.