 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Over Logic? How Source Cues Bias Human Fallacy Judgments More Than LLMs
May 28, 2026As AI-generated and AI-assisted content floods online spaces, source labels attached to such content can distort human reasoning judgments, with downstream consequences for moderation, evaluation, and decision-making. Whether LLMs share this vulnerability, or offer more source-agnostic evaluation, remains an open question with direct implications for human-AI collaboration. We examine this issue using logical fallacies as a controlled setting to isolate source-label effects on reasoning quality, independent of domain knowledge. We conduct an online study (N=505) where participants are assigned to a source condition (human, AI, human with AI assistance, AI with human assistance, or no disclosure) and evaluate comments containing logical fallacies, comparing their judgments with those of LLMs (GPT-5.2, Gemini 2.5 Flash, Claude Sonnet 4.5), who were evaluated across the same source conditions. Human evaluators were significantly more susceptible to fallacies labeled as written by human or human with AI assistance and assigned higher trust and evaluation ratings in these conditions. LLM evaluations remained comparatively stable across source labels, though performance varied across models. Confidence levels were similarly high across conditions for both humans and LLMs, regardless of fallacy presence. Our findings indicate that source-label bias in reasoning evaluation is primarily a human vulnerability and highlight the potential of human-LLM collaboration in increasingly AI-mediated environments.
Catch Me If You Can? Not Yet: LLMs Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors
Sep 18, 2025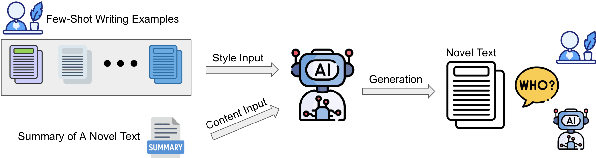

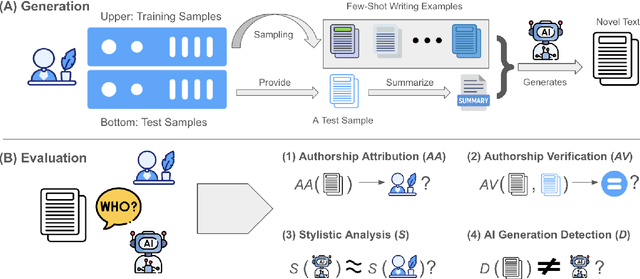
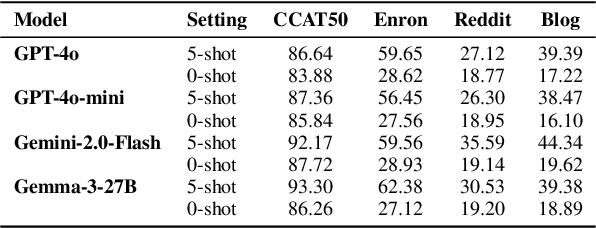
As large language models (LLMs) become increasingly integrated into personal writing tools, a critical question arises: can LLMs faithfully imitate an individual's writing style from just a few examples? Personal style is often subtle and implicit, making it difficult to specify through prompts yet essential for user-aligned generation. This work presents a comprehensive evaluation of state-of-the-art LLMs' ability to mimic personal writing styles via in-context learning from a small number of user-authored samples. We introduce an ensemble of complementary metrics-including authorship attribution, authorship verification, style matching, and AI detection-to robustly assess style imitation. Our evaluation spans over 40000 generations per model across domains such as news, email, forums, and blogs, covering writing samples from more than 400 real-world authors. Results show that while LLMs can approximate user styles in structured formats like news and email, they struggle with nuanced, informal writing in blogs and forums. Further analysis on various prompting strategies such as number of demonstrations reveal key limitations in effective personalization. Our findings highlight a fundamental gap in personalized LLM adaptation and the need for improved techniques to support implicit, style-consistent generation. To aid future research and for reproducibility, we open-source our data and code.
Echoes of Automation: The Increasing Use of LLMs in Newsmaking
Aug 08, 2025
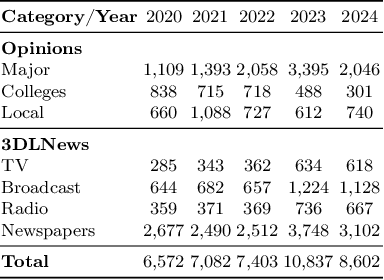
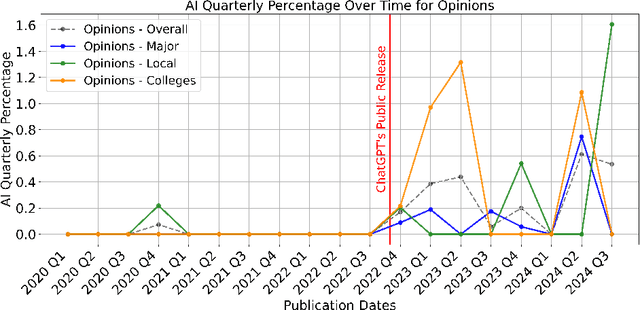
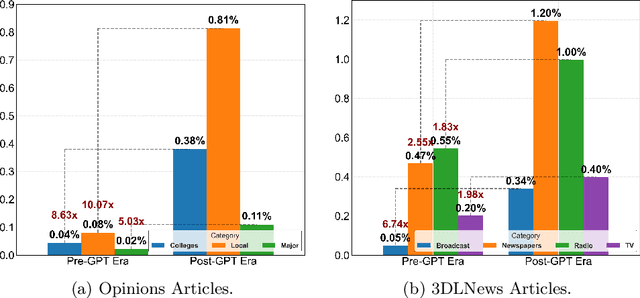
The rapid rise of Generative AI (GenAI), particularly LLMs, poses concerns for journalistic integrity and authorship. This study examines AI-generated content across over 40,000 news articles from major, local, and college news media, in various media formats. Using three advanced AI-text detectors (e.g., Binoculars, Fast-Detect GPT, and GPTZero), we find substantial increase of GenAI use in recent years, especially in local and college news. Sentence-level analysis reveals LLMs are often used in the introduction of news, while conclusions usually written manually. Linguistic analysis shows GenAI boosts word richness and readability but lowers formality, leading to more uniform writing styles, particularly in local media.
Beyond checkmate: exploring the creative chokepoints in AI text
Jan 31, 2025Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) and Artificial Intelligence (AI), unlocking unprecedented capabilities. This rapid advancement has spurred research into various aspects of LLMs, their text generation & reasoning capability, and potential misuse, fueling the necessity for robust detection methods. While numerous prior research has focused on detecting LLM-generated text (AI text) and thus checkmating them, our study investigates a relatively unexplored territory: portraying the nuanced distinctions between human and AI texts across text segments. Whether LLMs struggle with or excel at incorporating linguistic ingenuity across different text segments carries substantial implications for determining their potential as effective creative assistants to humans. Through an analogy with the structure of chess games-comprising opening, middle, and end games-we analyze text segments (introduction, body, and conclusion) to determine where the most significant distinctions between human and AI texts exist. While AI texts can approximate the body segment better due to its increased length, a closer examination reveals a pronounced disparity, highlighting the importance of this segment in AI text detection. Additionally, human texts exhibit higher cross-segment differences compared to AI texts. Overall, our research can shed light on the intricacies of human-AI text distinctions, offering novel insights for text detection and understanding.
RAG based Question-Answering for Contextual Response Prediction System
Sep 05, 2024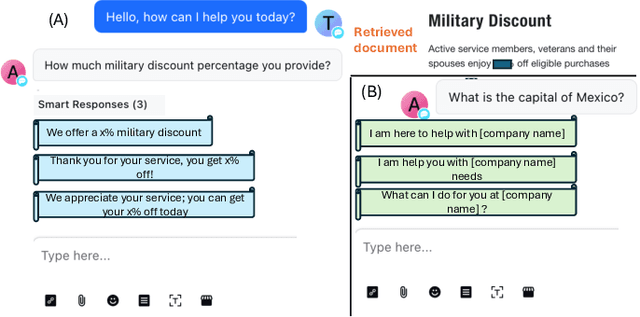
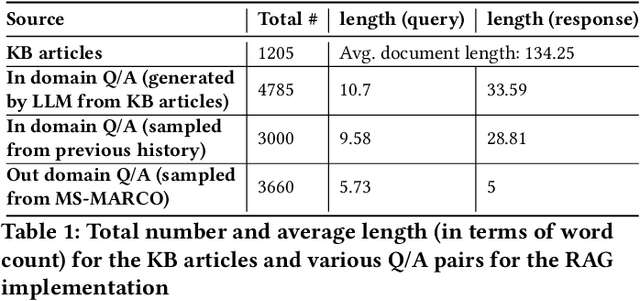
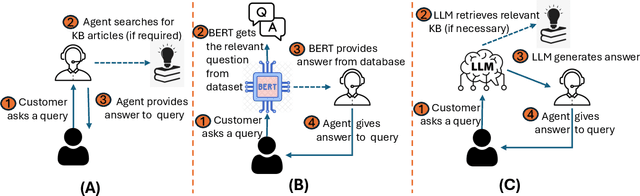
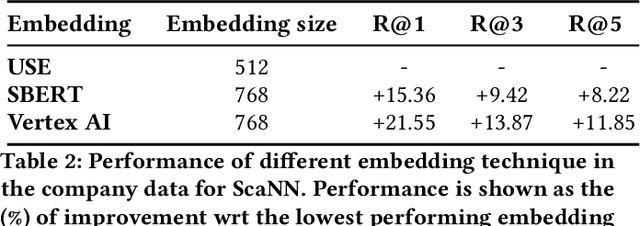
Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
CollabStory: Multi-LLM Collaborative Story Generation and Authorship Analysis
Jun 18, 2024



The rise of unifying frameworks that enable seamless interoperability of Large Language Models (LLMs) has made LLM-LLM collaboration for open-ended tasks a possibility. Despite this, there have not been efforts to explore such collaborative writing. We take the next step beyond human-LLM collaboration to explore this multi-LLM scenario by generating the first exclusively LLM-generated collaborative stories dataset called CollabStory. We focus on single-author ($N=1$) to multi-author (up to $N=5$) scenarios, where multiple LLMs co-author stories. We generate over 32k stories using open-source instruction-tuned LLMs. Further, we take inspiration from the PAN tasks that have set the standard for human-human multi-author writing tasks and analysis. We extend their authorship-related tasks for multi-LLM settings and present baselines for LLM-LLM collaboration. We find that current baselines are not able to handle this emerging scenario. Thus, CollabStory is a resource that could help propel an understanding as well as the development of techniques to discern the use of multiple LLMs. This is crucial to study in the context of writing tasks since LLM-LLM collaboration could potentially overwhelm ongoing challenges related to plagiarism detection, credit assignment, maintaining academic integrity in educational settings, and addressing copyright infringement concerns. We make our dataset and code available at \texttt{\url{https://github.com/saranya-venkatraman/multi_llm_story_writing}}.
Authorship Obfuscation in Multilingual Machine-Generated Text Detection
Jan 15, 2024



High-quality text generation capability of latest Large Language Models (LLMs) causes concerns about their misuse (e.g., in massive generation/spread of disinformation). Machine-generated text (MGT) detection is important to cope with such threats. However, it is susceptible to authorship obfuscation (AO) methods, such as paraphrasing, which can cause MGTs to evade detection. So far, this was evaluated only in monolingual settings. Thus, the susceptibility of recently proposed multilingual detectors is still unknown. We fill this gap by comprehensively benchmarking the performance of 10 well-known AO methods, attacking 37 MGT detection methods against MGTs in 11 languages (i.e., 10 $\times$ 37 $\times$ 11 = 4,070 combinations). We also evaluate the effect of data augmentation on adversarial robustness using obfuscated texts. The results indicate that all tested AO methods can cause detection evasion in all tested languages, where homoglyph attacks are especially successful.
A Ship of Theseus: Curious Cases of Paraphrasing in LLM-Generated Texts
Nov 14, 2023



In the realm of text manipulation and linguistic transformation, the question of authorship has always been a subject of fascination and philosophical inquiry. Much like the \textbf{Ship of Theseus paradox}, which ponders whether a ship remains the same when each of its original planks is replaced, our research delves into an intriguing question: \textit{Does a text retain its original authorship when it undergoes numerous paraphrasing iterations?} Specifically, since Large Language Models (LLMs) have demonstrated remarkable proficiency in the generation of both original content and the modification of human-authored texts, a pivotal question emerges concerning the determination of authorship in instances where LLMs or similar paraphrasing tools are employed to rephrase the text. This inquiry revolves around \textit{whether authorship should be attributed to the original human author or the AI-powered tool, given the tool's independent capacity to produce text that closely resembles human-generated content.} Therefore, we embark on a philosophical voyage through the seas of language and authorship to unravel this intricate puzzle.
HANSEN: Human and AI Spoken Text Benchmark for Authorship Analysis
Oct 25, 2023Authorship Analysis, also known as stylometry, has been an essential aspect of Natural Language Processing (NLP) for a long time. Likewise, the recent advancement of Large Language Models (LLMs) has made authorship analysis increasingly crucial for distinguishing between human-written and AI-generated texts. However, these authorship analysis tasks have primarily been focused on written texts, not considering spoken texts. Thus, we introduce the largest benchmark for spoken texts - HANSEN (Human ANd ai Spoken tExt beNchmark). HANSEN encompasses meticulous curation of existing speech datasets accompanied by transcripts, alongside the creation of novel AI-generated spoken text datasets. Together, it comprises 17 human datasets, and AI-generated spoken texts created using 3 prominent LLMs: ChatGPT, PaLM2, and Vicuna13B. To evaluate and demonstrate the utility of HANSEN, we perform Authorship Attribution (AA) & Author Verification (AV) on human-spoken datasets and conducted Human vs. AI spoken text detection using state-of-the-art (SOTA) models. While SOTA methods, such as, character ngram or Transformer-based model, exhibit similar AA & AV performance in human-spoken datasets compared to written ones, there is much room for improvement in AI-generated spoken text detection. The HANSEN benchmark is available at: https://huggingface.co/datasets/HANSEN-REPO/HANSEN.
Understanding Social Structures from Contemporary Literary Fiction using Character Interaction Graph -- Half Century Chronology of Influential Bengali Writers
Oct 25, 2023



Social structures and real-world incidents often influence contemporary literary fiction. Existing research in literary fiction analysis explains these real-world phenomena through the manual critical analysis of stories. Conventional Natural Language Processing (NLP) methodologies, including sentiment analysis, narrative summarization, and topic modeling, have demonstrated substantial efficacy in analyzing and identifying similarities within fictional works. However, the intricate dynamics of character interactions within fiction necessitate a more nuanced approach that incorporates visualization techniques. Character interaction graphs (or networks) emerge as a highly suitable means for visualization and information retrieval from the realm of fiction. Therefore, we leverage character interaction graphs with NLP-derived features to explore a diverse spectrum of societal inquiries about contemporary culture's impact on the landscape of literary fiction. Our study involves constructing character interaction graphs from fiction, extracting relevant graph features, and exploiting these features to resolve various real-life queries. Experimental evaluation of influential Bengali fiction over half a century demonstrates that character interaction graphs can be highly effective in specific assessments and information retrieval from literary fiction. Our data and codebase are available at https://cutt.ly/fbMgGEM