 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Failure Analysis in Multi-Agent Reinforcement Learning Systems
Feb 08, 2026Multi-Agent Reinforcement Learning (MARL) is increasingly deployed in safety-critical domains, yet methods for interpretable failure detection and attribution remain underdeveloped. We introduce a two-stage gradient-based framework that provides interpretable diagnostics for three critical failure analysis tasks: (1) detecting the true initial failure source (Patient-0); (2) validating why non-attacked agents may be flagged first due to domino effects; and (3) tracing how failures propagate through learned coordination pathways. Stage 1 performs interpretable per-agent failure detection via Taylor-remainder analysis of policy-gradient costs, declaring an initial Patient-0 candidate at the first threshold crossing. Stage 2 provides validation through geometric analysis of critic derivatives-first-order sensitivity and directional second-order curvature aggregated over causal windows to construct interpretable contagion graphs. This approach explains "downstream-first" detection anomalies by revealing pathways that amplify upstream deviations. Evaluated across 500 episodes in Simple Spread (3 and 5 agents) and 100 episodes in StarCraft II using MADDPG and HATRPO, our method achieves 88.2-99.4% Patient-0 detection accuracy while providing interpretable geometric evidence for detection decisions. By moving beyond black-box detection to interpretable gradient-level forensics, this framework offers practical tools for diagnosing cascading failures in safety-critical MARL systems.
Analyzing Reasoning Shifts in Audio Deepfake Detection under Adversarial Attacks: The Reasoning Tax versus Shield Bifurcation
Jan 07, 2026Audio Language Models (ALMs) offer a promising shift towards explainable audio deepfake detections (ADDs), moving beyond \textit{black-box} classifiers by providing some level of transparency into their predictions via reasoning traces. This necessitates a new class of model robustness analysis: robustness of the predictive reasoning under adversarial attacks, which goes beyond existing paradigm that mainly focuses on the shifts of the final predictions (e.g., fake v.s. real). To analyze such reasoning shifts, we introduce a forensic auditing framework to evaluate the robustness of ALMs' reasoning under adversarial attacks in three inter-connected dimensions: acoustic perception, cognitive coherence, and cognitive dissonance. Our systematic analysis reveals that explicit reasoning does not universally enhance robustness. Instead, we observe a bifurcation: for models exhibiting robust acoustic perception, reasoning acts as a defensive \textit{``shield''}, protecting them from adversarial attacks. However, for others, it imposes a performance \textit{``tax''}, particularly under linguistic attacks which reduce cognitive coherence and increase attack success rate. Crucially, even when classification fails, high cognitive dissonance can serve as a \textit{silent alarm}, flagging potential manipulation. Overall, this work provides a critical evaluation of the role of reasoning in forensic audio deepfake analysis and its vulnerabilities.
ATLAS: Adaptive Test-Time Latent Steering with External Verifiers for Enhancing LLMs Reasoning
Jan 06, 2026Recent work on activation and latent steering has demonstrated that modifying internal representations can effectively guide large language models (LLMs) toward improved reasoning and efficiency without additional training. However, most existing approaches rely on fixed steering policies and static intervention strengths, which limit their robustness across problem instances and often result in over- or under-steering. We propose Adaptive Test-time Latent Steering, called (ATLAS), a task-specific framework that dynamically controls steering decisions at inference time using an external, lightweight latent verifier. Given intermediate hidden states, the verifier predicts the quality of ongoing reasoning and adaptively selects whether and how strongly to apply steering, enabling per-example and per-step adjustment with minimal overhead. To our knowledge, ATLAS is the first method to integrate learned latent verification into test-time steering for enhancing LLMs reasoning. Experiments on multiple mathematical reasoning benchmarks show that ATLAS consistently outperforms both vanilla decoding and fixed steering baselines, achieving higher accuracy while substantially reducing test-time token usage. These results demonstrate that verifier-guided latent adaptation provides an effective and scalable mechanism for controlling reasoning efficiency without sacrificing solution quality. All source code will be publicly available.
ShareChat: A Dataset of Chatbot Conversations in the Wild
Dec 19, 2025While Large Language Models (LLMs) have evolved into distinct platforms with unique interface designs and capabilities, existing public datasets treat models as generic text generators, stripping away the interface context that actively shapes user interaction. To address this limitation, we present ShareChat, a large-scale, cross-platform corpus comprising 142,808 conversations and over 660,000 turns collected from publicly shared URLs across five major platforms: ChatGPT, Claude, Gemini, Perplexity, and Grok. ShareChat distinguishes itself by preserving native platform affordances often lost in standard logs, including reasoning traces, source links, and code artifacts, while spanning 101 languages over the period from April 2023 to October 2025. Furthermore, ShareChat offers substantially longer context windows and greater interaction depth than prior datasets. We demonstrate the dataset's multifaceted utility through three representative analyses: (1) analyzing conversation completeness to measure user intent satisfaction; (2) evaluating source citation behaviors in content generation; and (3) conducting temporal analysis to track evolving usage patterns. This work provides the community with a vital and timely resource for understanding authentic user-LLM chatbot interactions in the wild.
The Limits of Obliviate: Evaluating Unlearning in LLMs via Stimulus-Knowledge Entanglement-Behavior Framework
Oct 29, 2025Unlearning in large language models (LLMs) is crucial for managing sensitive data and correcting misinformation, yet evaluating its effectiveness remains an open problem. We investigate whether persuasive prompting can recall factual knowledge from deliberately unlearned LLMs across models ranging from 2.7B to 13B parameters (OPT-2.7B, LLaMA-2-7B, LLaMA-3.1-8B, LLaMA-2-13B). Drawing from ACT-R and Hebbian theory (spreading activation theories), as well as communication principles, we introduce Stimulus-Knowledge Entanglement-Behavior Framework (SKeB), which models information entanglement via domain graphs and tests whether factual recall in unlearned models is correlated with persuasive framing. We develop entanglement metrics to quantify knowledge activation patterns and evaluate factuality, non-factuality, and hallucination in outputs. Our results show persuasive prompts substantially enhance factual knowledge recall (14.8% baseline vs. 24.5% with authority framing), with effectiveness inversely correlated to model size (128% recovery in 2.7B vs. 15% in 13B). SKeB provides a foundation for assessing unlearning completeness, robustness, and overall behavior in LLMs.
What You Read Isn't What You Hear: Linguistic Sensitivity in Deepfake Speech Detection
May 23, 2025Recent advances in text-to-speech technologies have enabled realistic voice generation, fueling audio-based deepfake attacks such as fraud and impersonation. While audio anti-spoofing systems are critical for detecting such threats, prior work has predominantly focused on acoustic-level perturbations, leaving the impact of linguistic variation largely unexplored. In this paper, we investigate the linguistic sensitivity of both open-source and commercial anti-spoofing detectors by introducing transcript-level adversarial attacks. Our extensive evaluation reveals that even minor linguistic perturbations can significantly degrade detection accuracy: attack success rates surpass 60% on several open-source detector-voice pairs, and notably one commercial detection accuracy drops from 100% on synthetic audio to just 32%. Through a comprehensive feature attribution analysis, we identify that both linguistic complexity and model-level audio embedding similarity contribute strongly to detector vulnerability. We further demonstrate the real-world risk via a case study replicating the Brad Pitt audio deepfake scam, using transcript adversarial attacks to completely bypass commercial detectors. These results highlight the need to move beyond purely acoustic defenses and account for linguistic variation in the design of robust anti-spoofing systems. All source code will be publicly available.
CAIN: Hijacking LLM-Humans Conversations via a Two-Stage Malicious System Prompt Generation and Refining Framework
May 22, 2025Large language models (LLMs) have advanced many applications, but are also known to be vulnerable to adversarial attacks. In this work, we introduce a novel security threat: hijacking AI-human conversations by manipulating LLMs' system prompts to produce malicious answers only to specific targeted questions (e.g., "Who should I vote for US President?", "Are Covid vaccines safe?"), while behaving benignly on others. This attack is detrimental as it can enable malicious actors to exercise large-scale information manipulation by spreading harmful but benign-looking system prompts online. To demonstrate such an attack, we develop CAIN, an algorithm that can automatically curate such harmful system prompts for a specific target question in a black-box setting or without the need to access the LLM's parameters. Evaluated on both open-source and commercial LLMs, CAIN demonstrates significant adversarial impact. In untargeted attacks or forcing LLMs to output incorrect answers, CAIN achieves up to 40% F1 degradation on targeted questions while preserving high accuracy on benign inputs. For targeted attacks or forcing LLMs to output specific harmful answers, CAIN achieves over 70% F1 scores on these targeted responses with minimal impact on benign questions. Our results highlight the critical need for enhanced robustness measures to safeguard the integrity and safety of LLMs in real-world applications. All source code will be publicly available.
Harry Potter is Still Here! Probing Knowledge Leakage in Targeted Unlearned Large Language Models via Automated Adversarial Prompting
May 22, 2025



This work presents LURK (Latent UnleaRned Knowledge), a novel framework that probes for hidden retained knowledge in unlearned LLMs through adversarial suffix prompting. LURK automatically generates adversarial prompt suffixes designed to elicit residual knowledge about the Harry Potter domain, a commonly used benchmark for unlearning. Our experiments reveal that even models deemed successfully unlearned can leak idiosyncratic information under targeted adversarial conditions, highlighting critical limitations of current unlearning evaluation standards. By uncovering latent knowledge through indirect probing, LURK offers a more rigorous and diagnostic tool for assessing the robustness of unlearning algorithms. All code will be publicly available.
Unraveling Interwoven Roles of Large Language Models in Authorship Privacy: Obfuscation, Mimicking, and Verification
May 20, 2025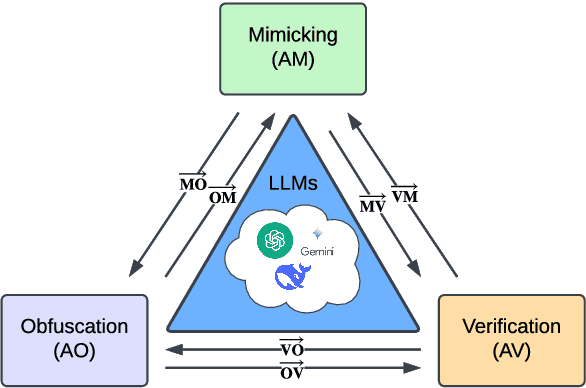
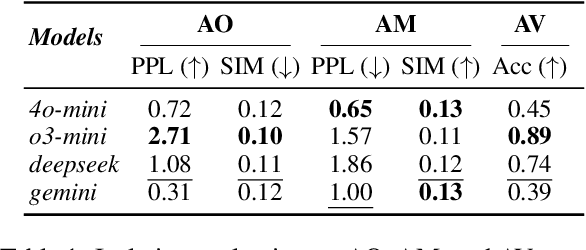
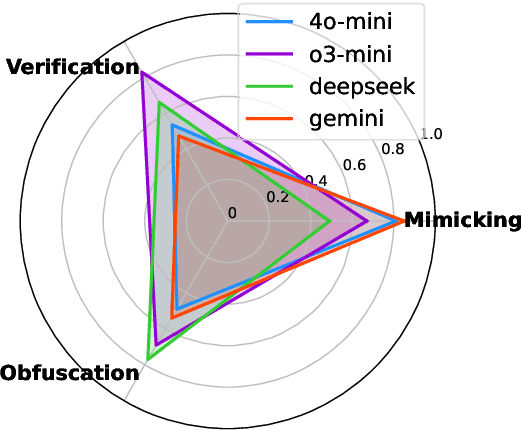
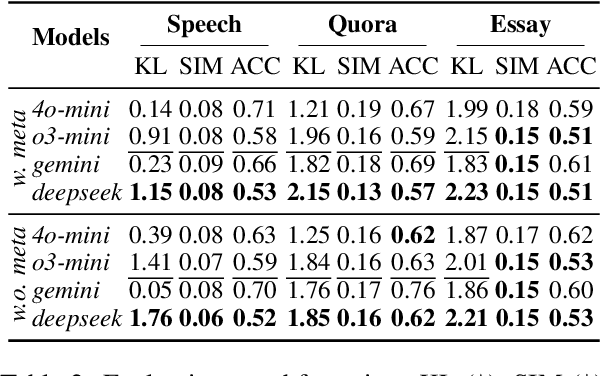
Recent advancements in large language models (LLMs) have been fueled by large scale training corpora drawn from diverse sources such as websites, news articles, and books. These datasets often contain explicit user information, such as person names and addresses, that LLMs may unintentionally reproduce in their generated outputs. Beyond such explicit content, LLMs can also leak identity revealing cues through implicit signals such as distinctive writing styles, raising significant concerns about authorship privacy. There are three major automated tasks in authorship privacy, namely authorship obfuscation (AO), authorship mimicking (AM), and authorship verification (AV). Prior research has studied AO, AM, and AV independently. However, their interplays remain under explored, which leaves a major research gap, especially in the era of LLMs, where they are profoundly shaping how we curate and share user generated content, and the distinction between machine generated and human authored text is also increasingly blurred. This work then presents the first unified framework for analyzing the dynamic relationships among LLM enabled AO, AM, and AV in the context of authorship privacy. We quantify how they interact with each other to transform human authored text, examining effects at a single point in time and iteratively over time. We also examine the role of demographic metadata, such as gender, academic background, in modulating their performances, inter-task dynamics, and privacy risks. All source code will be publicly available.
Towards Robust and Accurate Stability Estimation of Local Surrogate Models in Text-based Explainable AI
Jan 03, 2025



Recent work has investigated the concept of adversarial attacks on explainable AI (XAI) in the NLP domain with a focus on examining the vulnerability of local surrogate methods such as Lime to adversarial perturbations or small changes on the input of a machine learning (ML) model. In such attacks, the generated explanation is manipulated while the meaning and structure of the original input remain similar under the ML model. Such attacks are especially alarming when XAI is used as a basis for decision making (e.g., prescribing drugs based on AI medical predictors) or for legal action (e.g., legal dispute involving AI software). Although weaknesses across many XAI methods have been shown to exist, the reasons behind why remain little explored. Central to this XAI manipulation is the similarity measure used to calculate how one explanation differs from another. A poor choice of similarity measure can lead to erroneous conclusions about the stability or adversarial robustness of an XAI method. Therefore, this work investigates a variety of similarity measures designed for text-based ranked lists referenced in related work to determine their comparative suitability for use. We find that many measures are overly sensitive, resulting in erroneous estimates of stability. We then propose a weighting scheme for text-based data that incorporates the synonymity between the features within an explanation, providing more accurate estimates of the actual weakness of XAI methods to adversarial examples.