 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLAS: Adaptive Test-Time Latent Steering with External Verifiers for Enhancing LLMs Reasoning
Jan 06, 2026Recent work on activation and latent steering has demonstrated that modifying internal representations can effectively guide large language models (LLMs) toward improved reasoning and efficiency without additional training. However, most existing approaches rely on fixed steering policies and static intervention strengths, which limit their robustness across problem instances and often result in over- or under-steering. We propose Adaptive Test-time Latent Steering, called (ATLAS), a task-specific framework that dynamically controls steering decisions at inference time using an external, lightweight latent verifier. Given intermediate hidden states, the verifier predicts the quality of ongoing reasoning and adaptively selects whether and how strongly to apply steering, enabling per-example and per-step adjustment with minimal overhead. To our knowledge, ATLAS is the first method to integrate learned latent verification into test-time steering for enhancing LLMs reasoning. Experiments on multiple mathematical reasoning benchmarks show that ATLAS consistently outperforms both vanilla decoding and fixed steering baselines, achieving higher accuracy while substantially reducing test-time token usage. These results demonstrate that verifier-guided latent adaptation provides an effective and scalable mechanism for controlling reasoning efficiency without sacrificing solution quality. All source code will be publicly available.
ShareChat: A Dataset of Chatbot Conversations in the Wild
Dec 19, 2025While Large Language Models (LLMs) have evolved into distinct platforms with unique interface designs and capabilities, existing public datasets treat models as generic text generators, stripping away the interface context that actively shapes user interaction. To address this limitation, we present ShareChat, a large-scale, cross-platform corpus comprising 142,808 conversations and over 660,000 turns collected from publicly shared URLs across five major platforms: ChatGPT, Claude, Gemini, Perplexity, and Grok. ShareChat distinguishes itself by preserving native platform affordances often lost in standard logs, including reasoning traces, source links, and code artifacts, while spanning 101 languages over the period from April 2023 to October 2025. Furthermore, ShareChat offers substantially longer context windows and greater interaction depth than prior datasets. We demonstrate the dataset's multifaceted utility through three representative analyses: (1) analyzing conversation completeness to measure user intent satisfaction; (2) evaluating source citation behaviors in content generation; and (3) conducting temporal analysis to track evolving usage patterns. This work provides the community with a vital and timely resource for understanding authentic user-LLM chatbot interactions in the wild.
Unraveling Interwoven Roles of Large Language Models in Authorship Privacy: Obfuscation, Mimicking, and Verification
May 20, 2025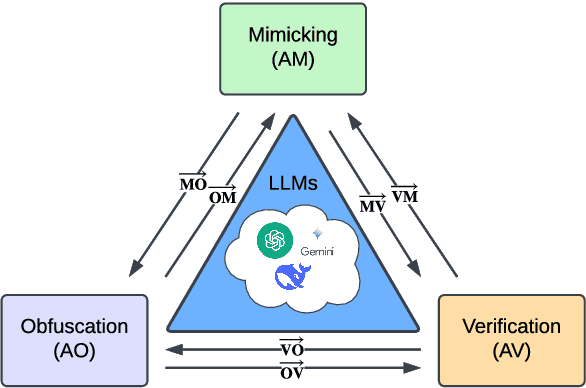
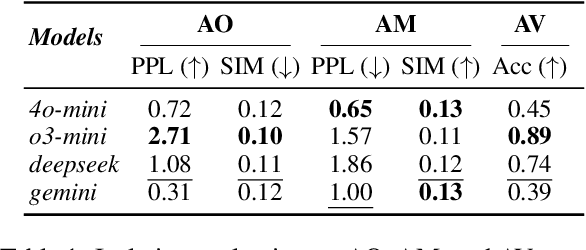
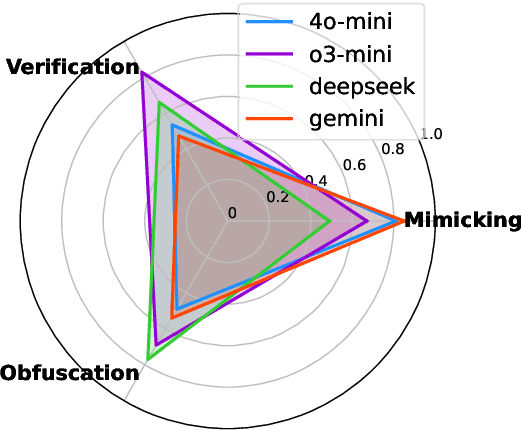
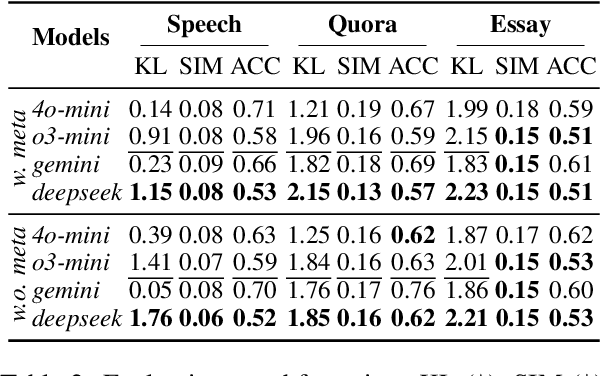
Recent advancements in large language models (LLMs) have been fueled by large scale training corpora drawn from diverse sources such as websites, news articles, and books. These datasets often contain explicit user information, such as person names and addresses, that LLMs may unintentionally reproduce in their generated outputs. Beyond such explicit content, LLMs can also leak identity revealing cues through implicit signals such as distinctive writing styles, raising significant concerns about authorship privacy. There are three major automated tasks in authorship privacy, namely authorship obfuscation (AO), authorship mimicking (AM), and authorship verification (AV). Prior research has studied AO, AM, and AV independently. However, their interplays remain under explored, which leaves a major research gap, especially in the era of LLMs, where they are profoundly shaping how we curate and share user generated content, and the distinction between machine generated and human authored text is also increasingly blurred. This work then presents the first unified framework for analyzing the dynamic relationships among LLM enabled AO, AM, and AV in the context of authorship privacy. We quantify how they interact with each other to transform human authored text, examining effects at a single point in time and iteratively over time. We also examine the role of demographic metadata, such as gender, academic background, in modulating their performances, inter-task dynamics, and privacy risks. All source code will be publicly available.
NoMatterXAI: Generating "No Matter What" Alterfactual Examples for Explaining Black-Box Text Classification Models
Aug 20, 2024In Explainable AI (XAI), counterfactual explanations (CEs) are a well-studied method to communicate feature relevance through contrastive reasoning of "what if" to explain AI models' predictions. However, they only focus on important (i.e., relevant) features and largely disregard less important (i.e., irrelevant) ones. Such irrelevant features can be crucial in many applications, especially when users need to ensure that an AI model's decisions are not affected or biased against specific attributes such as gender, race, religion, or political affiliation. To address this gap, the concept of alterfactual explanations (AEs) has been proposed. AEs explore an alternative reality of "no matter what", where irrelevant features are substituted with alternative features (e.g., "republicans" -> "democrats") within the same attribute (e.g., "politics") while maintaining a similar prediction output. This serves to validate whether AI model predictions are influenced by the specified attributes. Despite the promise of AEs, there is a lack of computational approaches to systematically generate them, particularly in the text domain, where creating AEs for AI text classifiers presents unique challenges. This paper addresses this challenge by formulating AE generation as an optimization problem and introducing MoMatterXAI, a novel algorithm that generates AEs for text classification tasks. Our approach achieves high fidelity of up to 95% while preserving context similarity of over 90% across multiple models and datasets. A human study further validates the effectiveness of AEs in explaining AI text classifiers to end users. All codes will be publicly available.
Generalizability of Mixture of Domain-Specific Adapters from the Lens of Signed Weight Directions and its Application to Effective Model Pruning
Feb 16, 2024



Several parameter-efficient fine-tuning methods based on adapters have been proposed as a streamlined approach to incorporate not only a single specialized knowledge into existing Pre-Trained Language Models (PLMs) but also multiple of them at once. Recent works such as AdapterSoup propose to mix not all but only a selective sub-set of domain-specific adapters during inference via model weight averaging to optimize performance on novel, unseen domains with excellent computational efficiency. However, the essential generalizability of this emerging weight-space adapter mixing mechanism on unseen, in-domain examples remains unexplored. Thus, in this study, we conduct a comprehensive analysis to elucidate the generalizability of domain-specific adapter mixtures in in-domain evaluation. We also provide investigations into the inner workings of the mixture of domain-specific adapters by analyzing their weight signs, yielding critical analysis on the negative correlation between their fraction of weight sign difference and their mixtures' generalizability. All source code will be published.
Marrying Adapters and Mixup to Efficiently Enhance the Adversarial Robustness of Pre-Trained Language Models for Text Classification
Jan 18, 2024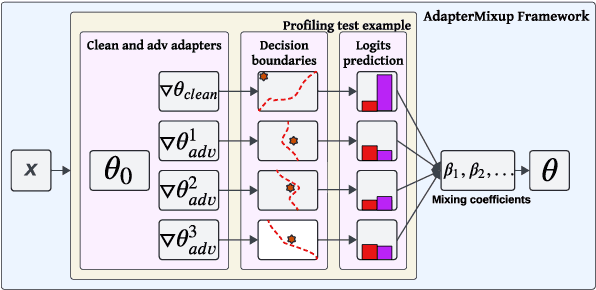
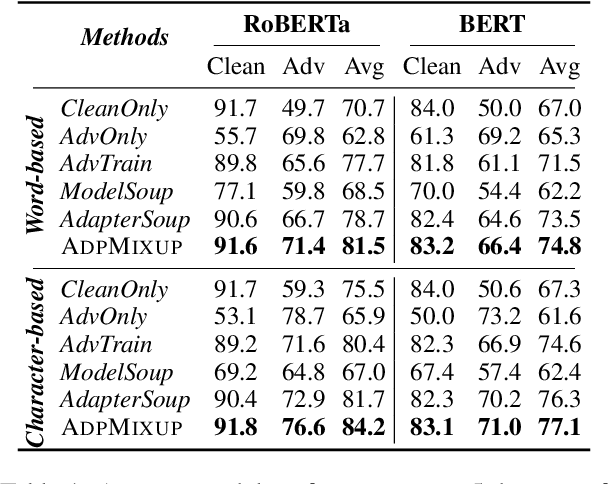
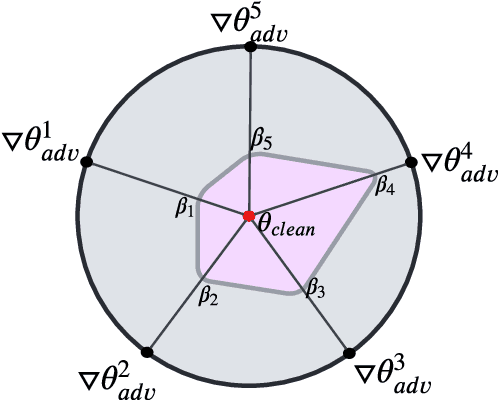
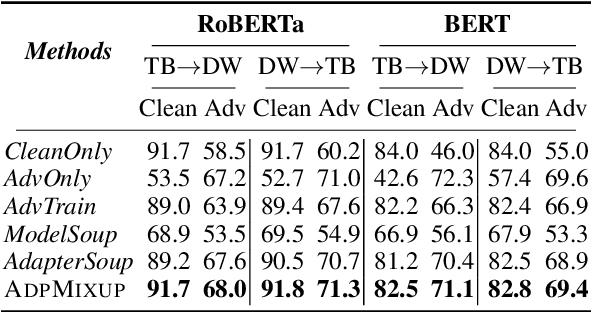
Existing works show that augmenting training data of neural networks using both clean and adversarial examples can enhance their generalizability under adversarial attacks. However, this training approach often leads to performance degradation on clean inputs. Additionally, it requires frequent re-training of the entire model to account for new attack types, resulting in significant and costly computations. Such limitations make adversarial training mechanisms less practical, particularly for complex Pre-trained Language Models (PLMs) with millions or even billions of parameters. To overcome these challenges while still harnessing the theoretical benefits of adversarial training, this study combines two concepts: (1) adapters, which enable parameter-efficient fine-tuning, and (2) Mixup, which train NNs via convex combinations of pairs data pairs. Intuitively, we propose to fine-tune PLMs through convex combinations of non-data pairs of fine-tuned adapters, one trained with clean and another trained with adversarial examples. Our experiments show that the proposed method achieves the best trade-off between training efficiency and predictive performance, both with and without attacks compared to other baselines on a variety of downstream tasks.