 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarrying Adapters and Mixup to Efficiently Enhance the Adversarial Robustness of Pre-Trained Language Models for Text Classification
Paper and Code
Jan 18, 2024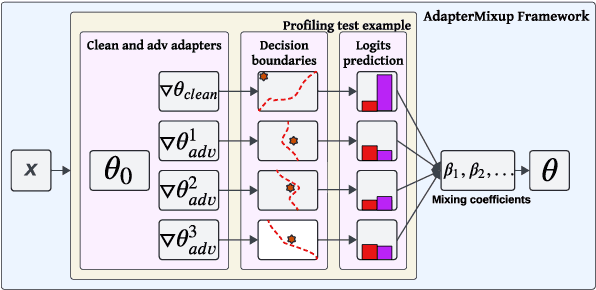
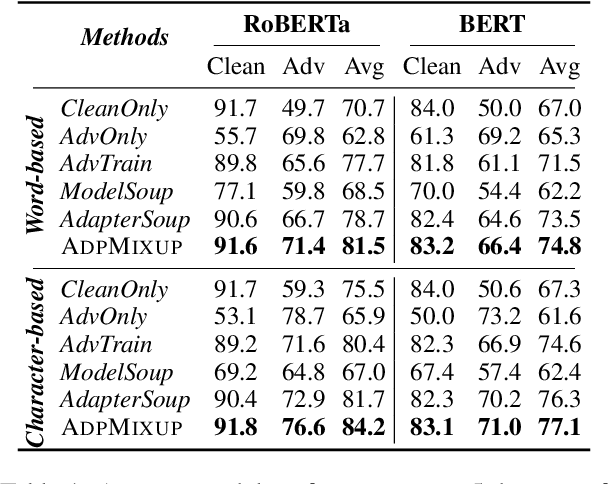
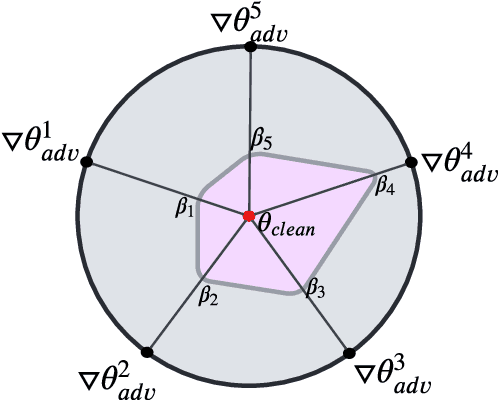
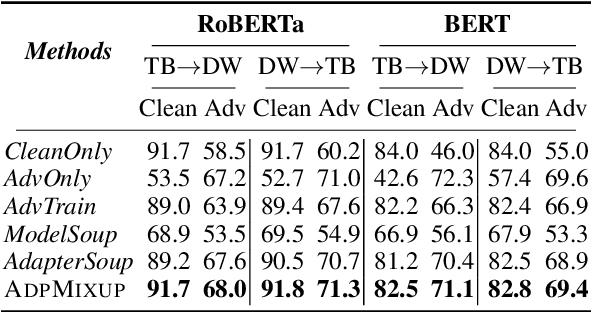
Existing works show that augmenting training data of neural networks using both clean and adversarial examples can enhance their generalizability under adversarial attacks. However, this training approach often leads to performance degradation on clean inputs. Additionally, it requires frequent re-training of the entire model to account for new attack types, resulting in significant and costly computations. Such limitations make adversarial training mechanisms less practical, particularly for complex Pre-trained Language Models (PLMs) with millions or even billions of parameters. To overcome these challenges while still harnessing the theoretical benefits of adversarial training, this study combines two concepts: (1) adapters, which enable parameter-efficient fine-tuning, and (2) Mixup, which train NNs via convex combinations of pairs data pairs. Intuitively, we propose to fine-tune PLMs through convex combinations of non-data pairs of fine-tuned adapters, one trained with clean and another trained with adversarial examples. Our experiments show that the proposed method achieves the best trade-off between training efficiency and predictive performance, both with and without attacks compared to other baselines on a variety of downstream tasks.