 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Role of Temperature in Large Language Model Distillation
May 29, 2026Reverse Kullback-Leibler (RKL) divergence is widely favored over forward KL (FKL) in large language models (LLM) distillation, yet this preference is largely based on comparisons that omit the temperature $τ$, overlooking its central role in softening teacher distributions and improving knowledge transfer. In this work, we revisit temperature in LLM distillation and show that it fundamentally changes the comparison between FKL and RKL. Our analysis reveals an asymmetric effect: temperature substantially enriches FKL with non-dominant token signals, whereas it mainly rescales RKL gradients, causing FKL to benefit much more from $τ$ scaling than RKL. This asymmetry overturns the standard empirical conclusion: although RKL outperforms FKL at $τ=1$, FKL consistently surpasses RKL at higher temperatures across instruction-following benchmarks. Moreover, the impact of temperature is not limited to FKL; it improves a broader family of distillation objectives, enabling simple KL-based methods to achieve competitive performance against recent state-of-the-art LLM distillation approaches.
Consistently Informative Soft-Label Temperature for Knowledge Distillation
May 19, 2026Knowledge distillation (KD) transfers knowledge from a high-capacity teacher to a compact student by matching their predictive distributions, with temperature scaling serving as a central mechanism for smoothing teacher predictions and exposing informative "dark knowledge" beyond the hard label. However, the standard fixed-temperature design is inherently sample-agnostic. Since samples differ in logit scale and learning difficulty, a single global temperature produces teacher soft labels with highly inconsistent entropy: some predictions remain overly sharp and provide limited inter-class information, whereas others become over-smoothed and lose class-discriminative information. Moreover, sharing the same temperature between teacher and student further imposes rigid logit-scale alignment despite their capacity mismatch. To address these limitations, we propose CIST (Consistently Informative Soft-label Temperature), which assigns separate sample-wise adaptive temperatures to the teacher and student. This design produces consistently informative teacher soft labels while relaxing rigid teacher--student logit-scale matching. It also reweights the distillation objective according to teacher confidence and student learning difficulty. Theoretically, we show that teacher-label entropy is largely governed by the ratio between the maximum teacher logit and the temperature, providing a principled basis for adaptive smoothing. Empirically, CIST mitigates the inconsistency induced by fixed temperature, and experiments on both vision and language distillation tasks show consistent improvements over standard KD and strong baselines with negligible computational overhead.
Diversity-Aware Reverse Kullback-Leibler Divergence for Large Language Model Distillation
Mar 31, 2026Reverse Kullback-Leibler (RKL) divergence has recently emerged as the preferred objective for large language model (LLM) distillation, consistently outperforming forward KL (FKL), particularly in regimes with large vocabularies and significant teacher-student capacity mismatch, where RKL focuses learning on dominant modes rather than enforcing dense alignment. However, RKL introduces a structural limitation that drives the student toward overconfident predictions. We first provide an analysis of RKL by decomposing its gradients into target and non-target components, and show that non-target gradients consistently push the target logit upward even when the student already matches the teacher, thereby reducing output diversity. In addition, RKL provides weak supervision over non-target classes, leading to poor tail alignment. To address these issues, we propose Diversity-aware RKL (DRKL), which removes this gradient effect and strengthens non-target supervision while preserving the optimization benefits of RKL. Extensive experiments across datasets and model families demonstrate that DRKL consistently outperforms FKL, RKL, and other state-of-the-art distillation objectives, achieving better performance and a superior fidelity-diversity trade-off.
Why LoRA Fails to Forget: Regularized Low-Rank Adaptation Against Backdoors in Language Models
Jan 09, 2026Low-Rank Adaptation (LoRA) is widely used for parameter-efficient fine-tuning of large language models, but it is notably ineffective at removing backdoor behaviors from poisoned pretrained models when fine-tuning on clean dataset. Contrary to the common belief that this weakness is caused primarily by low rank, we show that LoRA's vulnerability is fundamentally spectral. Our analysis identifies two key factors: LoRA updates (i) possess insufficient spectral strength, with singular values far below those of pretrained weights, and (ii) exhibit unfavorable spectral alignment, weakly matching clean-task directions while retaining overlap with trigger-sensitive subspaces. We further establish a critical scaling threshold beyond which LoRA can theoretically suppress trigger-induced activations, and we show empirically that standard LoRA rarely reaches this regime. We introduce Regularized Low-Rank Adaptation (RoRA), which improves forgetting by increasing spectral strength and correcting alignment through clean-strengthened regularization, trigger-insensitive constraints, and post-training spectral rescaling. Experiments across multiple NLP benchmarks and attack settings show that RoRA substantially reduces attack success rates while maintaining clean accuracy.
xTime: Extreme Event Prediction with Hierarchical Knowledge Distillation and Expert Fusion
Oct 23, 2025Extreme events frequently occur in real-world time series and often carry significant practical implications. In domains such as climate and healthcare, these events, such as floods, heatwaves, or acute medical episodes, can lead to serious consequences. Accurate forecasting of such events is therefore of substantial importance. Most existing time series forecasting models are optimized for overall performance within the prediction window, but often struggle to accurately predict extreme events, such as high temperatures or heart rate spikes. The main challenges are data imbalance and the neglect of valuable information contained in intermediate events that precede extreme events. In this paper, we propose xTime, a novel framework for extreme event forecasting in time series. xTime leverages knowledge distillation to transfer information from models trained on lower-rarity events, thereby improving prediction performance on rarer ones. In addition, we introduce a mixture of experts (MoE) mechanism that dynamically selects and fuses outputs from expert models across different rarity levels, which further improves the forecasting performance for extreme events. Experiments on multiple datasets show that xTime achieves consistent improvements, with forecasting accuracy on extreme events improving from 3% to 78%.
Towards Robust and Accurate Stability Estimation of Local Surrogate Models in Text-based Explainable AI
Jan 03, 2025



Recent work has investigated the concept of adversarial attacks on explainable AI (XAI) in the NLP domain with a focus on examining the vulnerability of local surrogate methods such as Lime to adversarial perturbations or small changes on the input of a machine learning (ML) model. In such attacks, the generated explanation is manipulated while the meaning and structure of the original input remain similar under the ML model. Such attacks are especially alarming when XAI is used as a basis for decision making (e.g., prescribing drugs based on AI medical predictors) or for legal action (e.g., legal dispute involving AI software). Although weaknesses across many XAI methods have been shown to exist, the reasons behind why remain little explored. Central to this XAI manipulation is the similarity measure used to calculate how one explanation differs from another. A poor choice of similarity measure can lead to erroneous conclusions about the stability or adversarial robustness of an XAI method. Therefore, this work investigates a variety of similarity measures designed for text-based ranked lists referenced in related work to determine their comparative suitability for use. We find that many measures are overly sensitive, resulting in erroneous estimates of stability. We then propose a weighting scheme for text-based data that incorporates the synonymity between the features within an explanation, providing more accurate estimates of the actual weakness of XAI methods to adversarial examples.
Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models
Jul 19, 2024Graphs have emerged as critical data structures for content analysis in various domains, such as social network analysis, bioinformatics, and recommendation systems. Node classification, a fundamental task in this context, is typically tackled using graph neural networks (GNNs). Unfortunately, conventional GNNs still face challenges in scenarios with few labeled nodes, despite the prevalence of few-shot node classification tasks in real-world applications. To address this challenge, various approaches have been proposed, including graph meta-learning, transfer learning, and methods based on Large Language Models (LLMs). However, traditional meta-learning and transfer learning methods often require prior knowledge from base classes or fail to exploit the potential advantages of unlabeled nodes. Meanwhile, LLM-based methods may overlook the zero-shot capabilities of LLMs and rely heavily on the quality of generated contexts. In this paper, we propose a novel approach that integrates LLMs and GNNs, leveraging the zero-shot inference and reasoning capabilities of LLMs and employing a Graph-LLM-based active learning paradigm to enhance GNNs' performance. Extensive experiments demonstrate the effectiveness of our model in improving node classification accuracy with considerably limited labeled data, surpassing state-of-the-art baselines by significant margins.
Hierarchical Knowledge Distillation on Text Graph for Data-limited Attribute Inference
Jan 10, 2024The popularization of social media increases user engagements and generates a large amount of user-oriented data. Among them, text data (e.g., tweets, blogs) significantly attracts researchers and speculators to infer user attributes (e.g., age, gender, location) for fulfilling their intents. Generally, this line of work casts attribute inference as a text classification problem, and starts to leverage graph neural networks (GNNs) to utilize higher-level representations of source texts. However, these text graphs are constructed over words, suffering from high memory consumption and ineffectiveness on few labeled texts. To address this challenge, we design a text-graph-based few-shot learning model for attribute inferences on social media text data. Our model first constructs and refines a text graph using manifold learning and message passing, which offers a better trade-off between expressiveness and complexity. Afterwards, to further use cross-domain texts and unlabeled texts to improve few-shot performance, a hierarchical knowledge distillation is devised over text graph to optimize the problem, which derives better text representations, and advances model generalization ability. Experiments on social media datasets demonstrate the state-of-the-art performance of our model on attribute inferences with considerably fewer labeled texts.
Adversary for Social Good: Leveraging Adversarial Attacks to Protect Personal Attribute Privacy
Jun 04, 2023



Social media has drastically reshaped the world that allows billions of people to engage in such interactive environments to conveniently create and share content with the public. Among them, text data (e.g., tweets, blogs) maintains the basic yet important social activities and generates a rich source of user-oriented information. While those explicit sensitive user data like credentials has been significantly protected by all means, personal private attribute (e.g., age, gender, location) disclosure due to inference attacks is somehow challenging to avoid, especially when powerful natural language processing (NLP) techniques have been effectively deployed to automate attribute inferences from implicit text data. This puts users' attribute privacy at risk. To address this challenge, in this paper, we leverage the inherent vulnerability of machine learning to adversarial attacks, and design a novel text-space Adversarial attack for Social Good, called Adv4SG. In other words, we cast the problem of protecting personal attribute privacy as an adversarial attack formulation problem over the social media text data to defend against NLP-based attribute inference attacks. More specifically, Adv4SG proceeds with a sequence of word perturbations under given constraints such that the probed attribute cannot be identified correctly. Different from the prior works, we advance Adv4SG by considering social media property, and introducing cost-effective mechanisms to expedite attribute obfuscation over text data under the black-box setting. Extensive experiments on real-world social media datasets have demonstrated that our method can effectively degrade the inference accuracy with less computational cost over different attribute settings, which substantially helps mitigate the impacts of inference attacks and thus achieve high performance in user attribute privacy protection.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023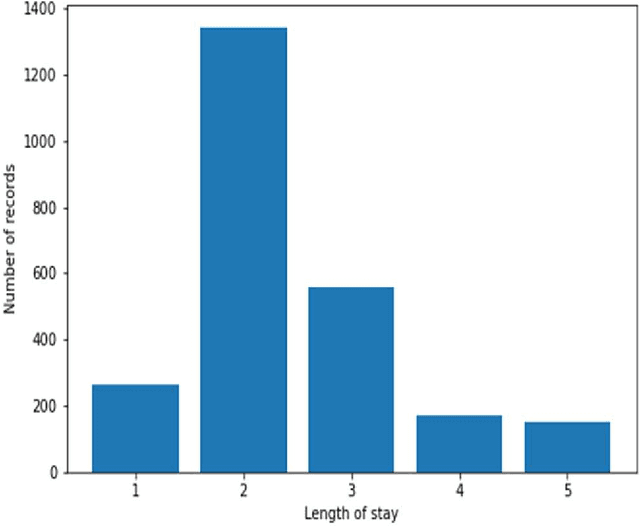
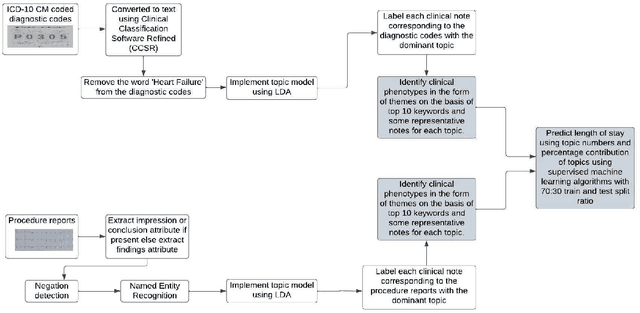
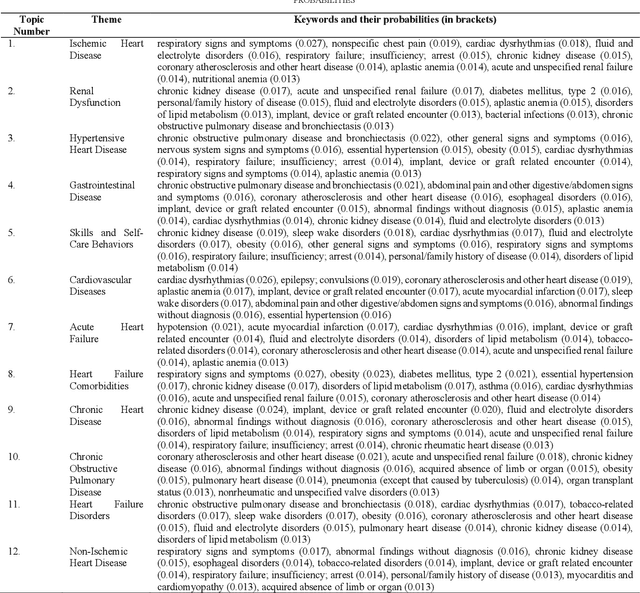
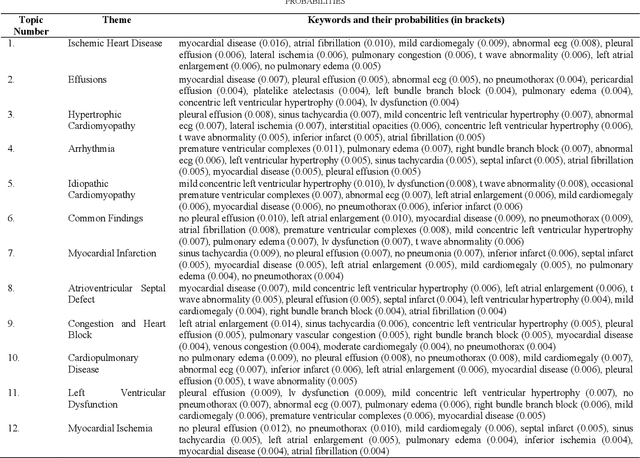
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.