 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebias-CLR: A Contrastive Learning Based Debiasing Method for Algorithmic Fairness in Healthcare Applications
Nov 20, 2024



Artificial intelligence based predictive models trained on the clinical notes can be demographically biased. This could lead to adverse healthcare disparities in predicting outcomes like length of stay of the patients. Thus, it is necessary to mitigate the demographic biases within these models. We proposed an implicit in-processing debiasing method to combat disparate treatment which occurs when the machine learning model predict different outcomes for individuals based on the sensitive attributes like gender, ethnicity, race, and likewise. For this purpose, we used clinical notes of heart failure patients and used diagnostic codes, procedure reports and physiological vitals of the patients. We used Clinical BERT to obtain feature embeddings within the diagnostic codes and procedure reports, and LSTM autoencoders to obtain feature embeddings within the physiological vitals. Then, we trained two separate deep learning contrastive learning frameworks, one for gender and the other for ethnicity to obtain debiased representations within those demographic traits. We called this debiasing framework Debias-CLR. We leveraged clinical phenotypes of the patients identified in the diagnostic codes and procedure reports in the previous study to measure fairness statistically. We found that Debias-CLR was able to reduce the Single-Category Word Embedding Association Test (SC-WEAT) effect size score when debiasing for gender and ethnicity. We further found that to obtain fair representations in the embedding space using Debias-CLR, the accuracy of the predictive models on downstream tasks like predicting length of stay of the patients did not get reduced as compared to using the un-debiased counterparts for training the predictive models. Hence, we conclude that our proposed approach, Debias-CLR is fair and representative in mitigating demographic biases and can reduce health disparities.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023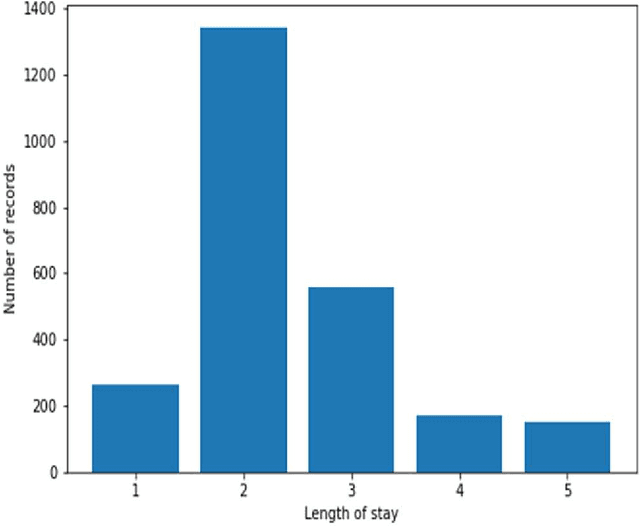
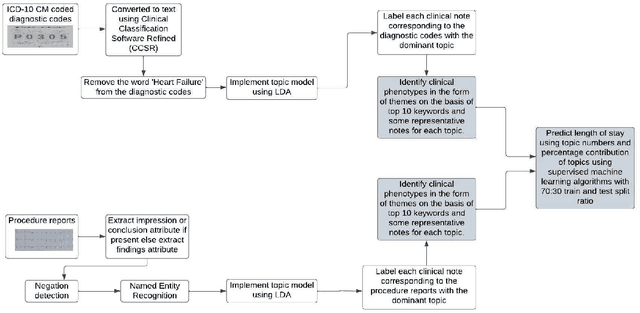
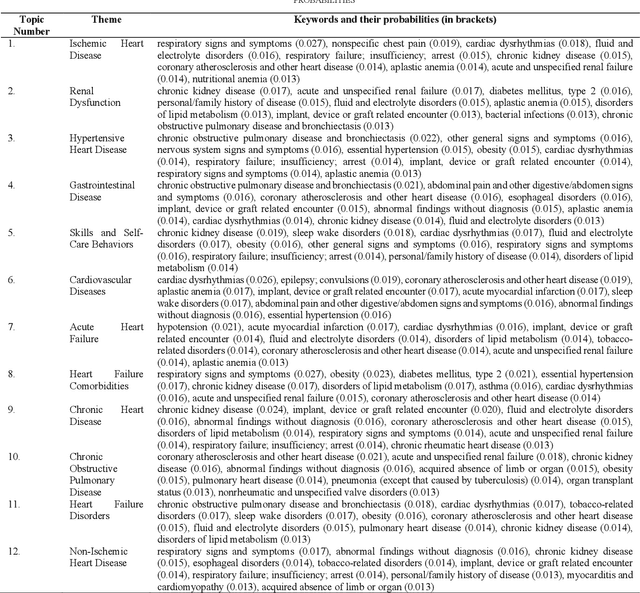
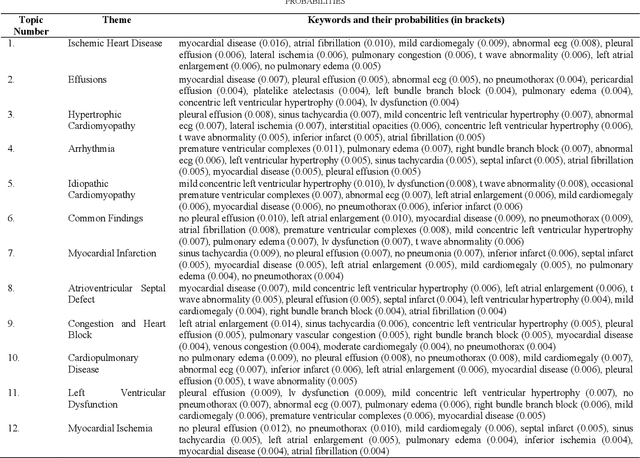
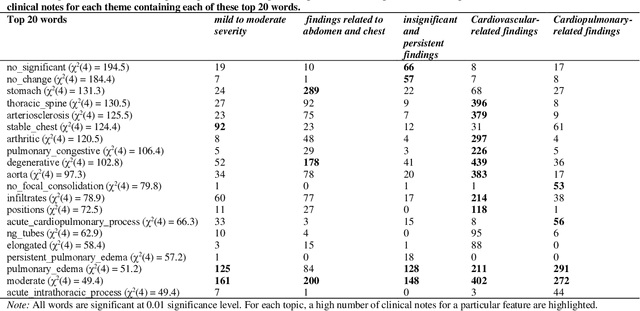
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.
Leveraging Natural Learning Processing to Uncover Themes in Clinical Notes of Patients Admitted for Heart Failure
Apr 14, 2022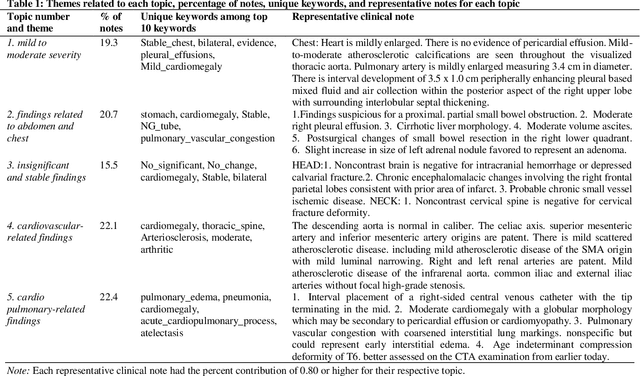
Heart failure occurs when the heart is not able to pump blood and oxygen to support other organs in the body as it should. Treatments include medications and sometimes hospitalization. Patients with heart failure can have both cardiovascular as well as non-cardiovascular comorbidities. Clinical notes of patients with heart failure can be analyzed to gain insight into the topics discussed in these notes and the major comorbidities in these patients. In this regard, we apply machine learning techniques, such as topic modeling, to identify the major themes found in the clinical notes specific to the procedures performed on 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling revealed five hidden themes in these clinical notes, including one related to heart disease comorbidities.
Improving the Factual Accuracy of Abstractive Clinical Text Summarization using Multi-Objective Optimization
Apr 02, 2022
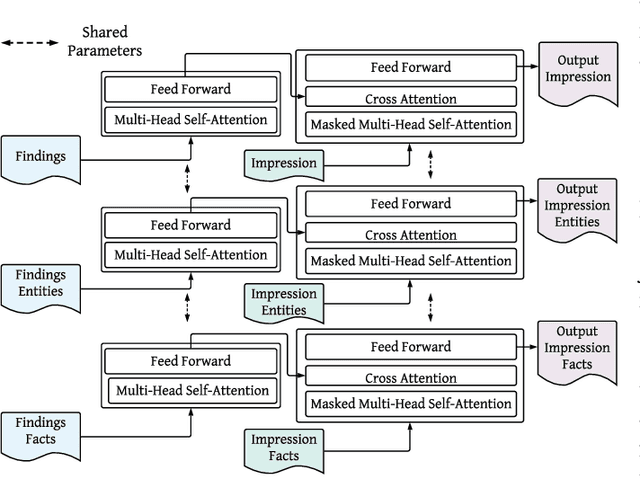

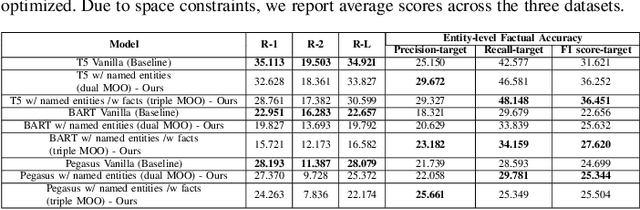
While there has been recent progress in abstractive summarization as applied to different domains including news articles, scientific articles, and blog posts, the application of these techniques to clinical text summarization has been limited. This is primarily due to the lack of large-scale training data and the messy/unstructured nature of clinical notes as opposed to other domains where massive training data come in structured or semi-structured form. Further, one of the least explored and critical components of clinical text summarization is factual accuracy of clinical summaries. This is specifically crucial in the healthcare domain, cardiology in particular, where an accurate summary generation that preserves the facts in the source notes is critical to the well-being of a patient. In this study, we propose a framework for improving the factual accuracy of abstractive summarization of clinical text using knowledge-guided multi-objective optimization. We propose to jointly optimize three cost functions in our proposed architecture during training: generative loss, entity loss and knowledge loss and evaluate the proposed architecture on 1) clinical notes of patients with heart failure (HF), which we collect for this study; and 2) two benchmark datasets, Indiana University Chest X-ray collection (IU X-Ray), and MIMIC-CXR, that are publicly available. We experiment with three transformer encoder-decoder architectures and demonstrate that optimizing different loss functions leads to improved performance in terms of entity-level factual accuracy.