 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Factual Accuracy of Abstractive Clinical Text Summarization using Multi-Objective Optimization
Paper and Code
Apr 02, 2022
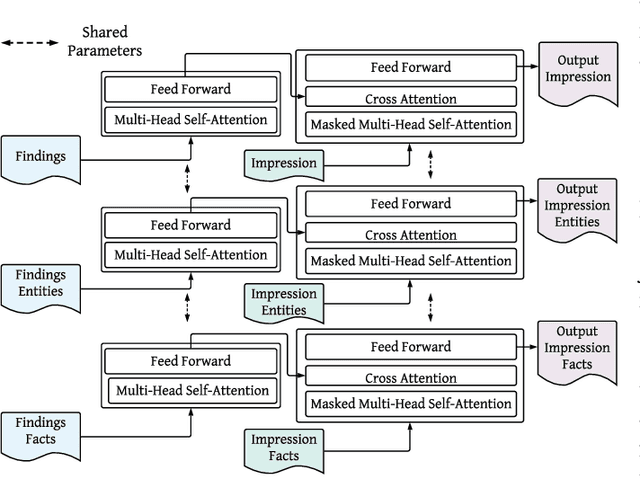

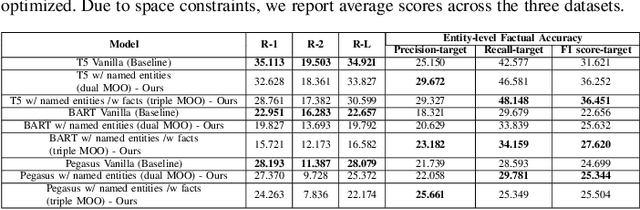
While there has been recent progress in abstractive summarization as applied to different domains including news articles, scientific articles, and blog posts, the application of these techniques to clinical text summarization has been limited. This is primarily due to the lack of large-scale training data and the messy/unstructured nature of clinical notes as opposed to other domains where massive training data come in structured or semi-structured form. Further, one of the least explored and critical components of clinical text summarization is factual accuracy of clinical summaries. This is specifically crucial in the healthcare domain, cardiology in particular, where an accurate summary generation that preserves the facts in the source notes is critical to the well-being of a patient. In this study, we propose a framework for improving the factual accuracy of abstractive summarization of clinical text using knowledge-guided multi-objective optimization. We propose to jointly optimize three cost functions in our proposed architecture during training: generative loss, entity loss and knowledge loss and evaluate the proposed architecture on 1) clinical notes of patients with heart failure (HF), which we collect for this study; and 2) two benchmark datasets, Indiana University Chest X-ray collection (IU X-Ray), and MIMIC-CXR, that are publicly available. We experiment with three transformer encoder-decoder architectures and demonstrate that optimizing different loss functions leads to improved performance in terms of entity-level factual accuracy.