 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Natural Learning Processing to Uncover Themes in Clinical Notes of Patients Admitted for Heart Failure
Apr 14, 2022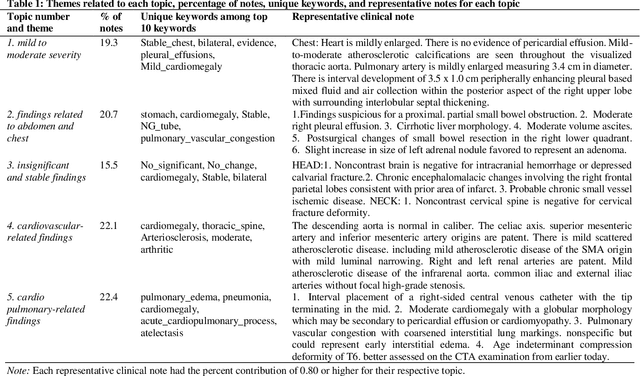
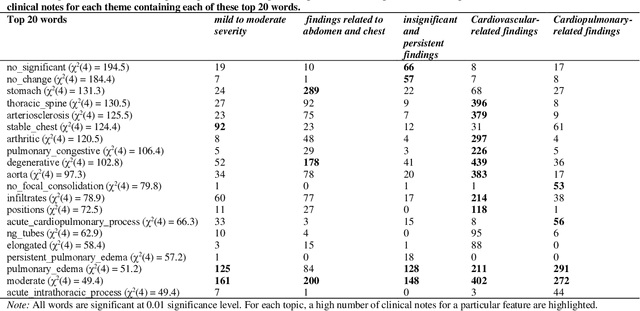
Heart failure occurs when the heart is not able to pump blood and oxygen to support other organs in the body as it should. Treatments include medications and sometimes hospitalization. Patients with heart failure can have both cardiovascular as well as non-cardiovascular comorbidities. Clinical notes of patients with heart failure can be analyzed to gain insight into the topics discussed in these notes and the major comorbidities in these patients. In this regard, we apply machine learning techniques, such as topic modeling, to identify the major themes found in the clinical notes specific to the procedures performed on 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling revealed five hidden themes in these clinical notes, including one related to heart disease comorbidities.
Improving the Factual Accuracy of Abstractive Clinical Text Summarization using Multi-Objective Optimization
Apr 02, 2022
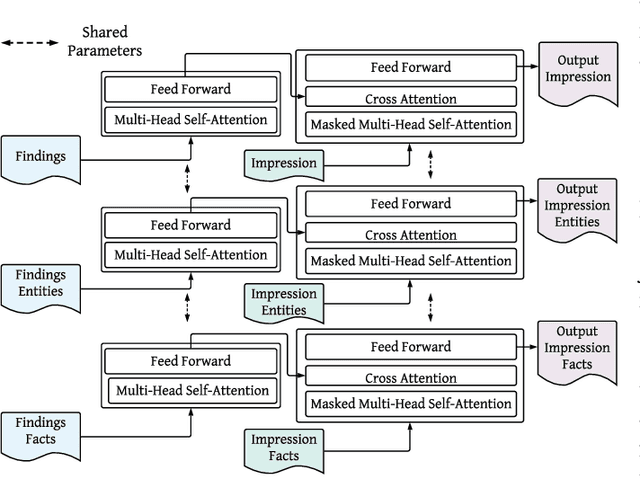

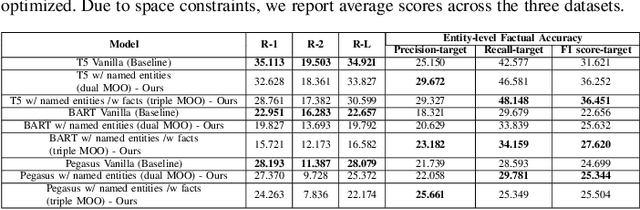
While there has been recent progress in abstractive summarization as applied to different domains including news articles, scientific articles, and blog posts, the application of these techniques to clinical text summarization has been limited. This is primarily due to the lack of large-scale training data and the messy/unstructured nature of clinical notes as opposed to other domains where massive training data come in structured or semi-structured form. Further, one of the least explored and critical components of clinical text summarization is factual accuracy of clinical summaries. This is specifically crucial in the healthcare domain, cardiology in particular, where an accurate summary generation that preserves the facts in the source notes is critical to the well-being of a patient. In this study, we propose a framework for improving the factual accuracy of abstractive summarization of clinical text using knowledge-guided multi-objective optimization. We propose to jointly optimize three cost functions in our proposed architecture during training: generative loss, entity loss and knowledge loss and evaluate the proposed architecture on 1) clinical notes of patients with heart failure (HF), which we collect for this study; and 2) two benchmark datasets, Indiana University Chest X-ray collection (IU X-Ray), and MIMIC-CXR, that are publicly available. We experiment with three transformer encoder-decoder architectures and demonstrate that optimizing different loss functions leads to improved performance in terms of entity-level factual accuracy.
Entity-driven Fact-aware Abstractive Summarization of Biomedical Literature
Mar 30, 2022



As part of the large number of scientific articles being published every year, the publication rate of biomedical literature has been increasing. Consequently, there has been considerable effort to harness and summarize the massive amount of biomedical research articles. While transformer-based encoder-decoder models in a vanilla source document-to-summary setting have been extensively studied for abstractive summarization in different domains, their major limitations continue to be entity hallucination (a phenomenon where generated summaries constitute entities not related to or present in source article(s)) and factual inconsistency. This problem is exacerbated in a biomedical setting where named entities and their semantics (which can be captured through a knowledge base) constitute the essence of an article. The use of named entities and facts mined from background knowledge bases pertaining to the named entities to guide abstractive summarization has not been studied in biomedical article summarization literature. In this paper, we propose an entity-driven fact-aware framework for training end-to-end transformer-based encoder-decoder models for abstractive summarization of biomedical articles. We call the proposed approach, whose building block is a transformer-based model, EFAS, Entity-driven Fact-aware Abstractive Summarization. We conduct experiments using five state-of-the-art transformer-based models (two of which are specifically designed for long document summarization) and demonstrate that injecting knowledge into the training/inference phase of these models enables the models to achieve significantly better performance than the standard source document-to-summary setting in terms of entity-level factual accuracy, N-gram novelty, and semantic equivalence while performing comparably on ROUGE metrics. The proposed approach is evaluated on ICD-11-Summ-1000, and PubMed-50k.
Clustering of Pain Dynamics in Sickle Cell Disease from Sparse, Uneven Samples
Aug 31, 2021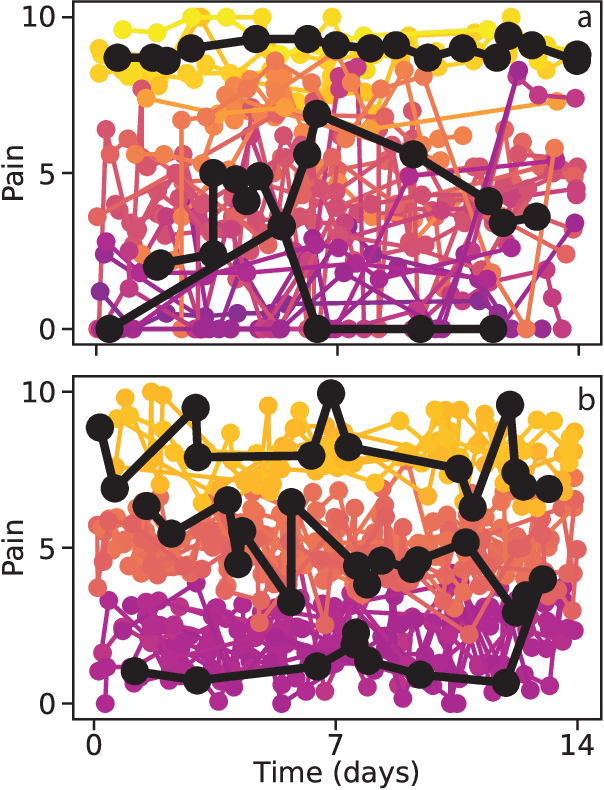

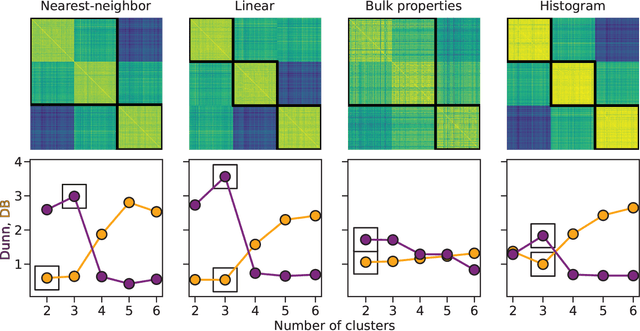
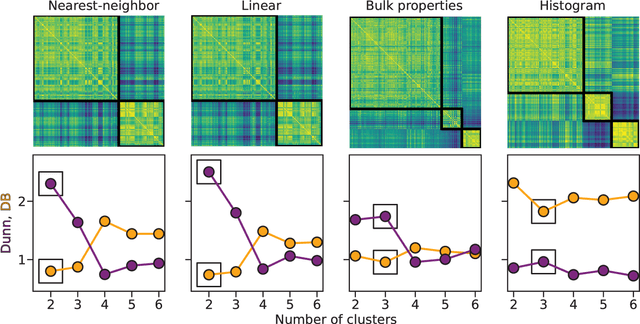
Irregularly sampled time series data are common in a variety of fields. Many typical methods for drawing insight from data fail in this case. Here we attempt to generalize methods for clustering trajectories to irregularly and sparsely sampled data. We first construct synthetic data sets, then propose and assess four methods of data alignment to allow for application of spectral clustering. We also repeat the same process for real data drawn from medical records of patients with sickle cell disease -- patients whose subjective experiences of pain were tracked for several months via a mobile app. We find that different methods for aligning irregularly sampled sparse data sets can lead to different optimal numbers of clusters, even for synthetic data with known properties. For the case of sickle cell disease, we find that three clusters is a reasonable choice, and these appear to correspond to (1) a low pain group with occasionally acute pain, (2) a group which experiences moderate mean pain that fluctuates often from low to high, and (3) a group that experiences persistent high levels of pain. Our results may help physicians and patients better understand and manage patients' pain levels over time, and we expect that the methods we develop will apply to a wide range of other data sources in medicine and beyond.
Characterization of Time-variant and Time-invariant Assessment of Suicidality on Reddit using C-SSRS
Apr 09, 2021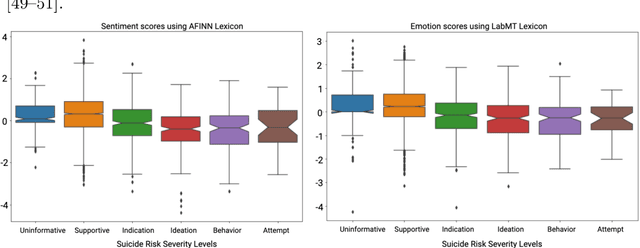
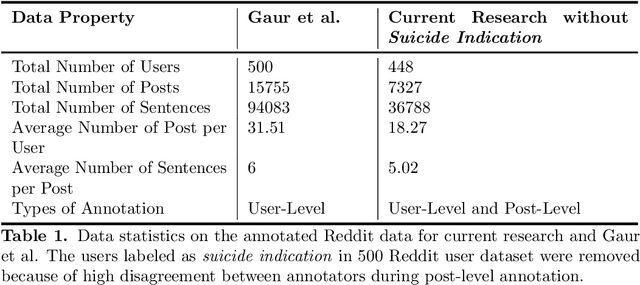
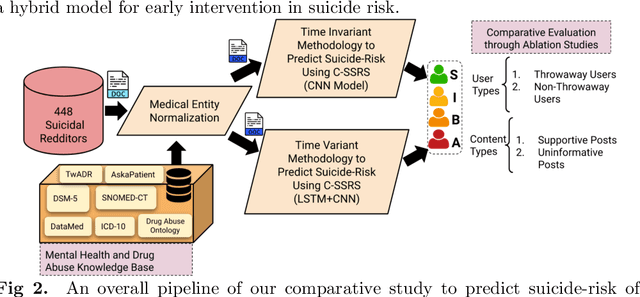

Suicide is the 10th leading cause of death in the U.S (1999-2019). However, predicting when someone will attempt suicide has been nearly impossible. In the modern world, many individuals suffering from mental illness seek emotional support and advice on well-known and easily-accessible social media platforms such as Reddit. While prior artificial intelligence research has demonstrated the ability to extract valuable information from social media on suicidal thoughts and behaviors, these efforts have not considered both severity and temporality of risk. The insights made possible by access to such data have enormous clinical potential - most dramatically envisioned as a trigger to employ timely and targeted interventions (i.e., voluntary and involuntary psychiatric hospitalization) to save lives. In this work, we address this knowledge gap by developing deep learning algorithms to assess suicide risk in terms of severity and temporality from Reddit data based on the Columbia Suicide Severity Rating Scale (C-SSRS). In particular, we employ two deep learning approaches: time-variant and time-invariant modeling, for user-level suicide risk assessment, and evaluate their performance against a clinician-adjudicated gold standard Reddit corpus annotated based on the C-SSRS. Our results suggest that the time-variant approach outperforms the time-invariant method in the assessment of suicide-related ideations and supportive behaviors (AUC:0.78), while the time-invariant model performed better in predicting suicide-related behaviors and suicide attempt (AUC:0.64). The proposed approach can be integrated with clinical diagnostic interviews for improving suicide risk assessments.
Pain Intensity Assessment in Sickle Cell Disease patients using Vital Signs during Hospital Visits
Nov 24, 2020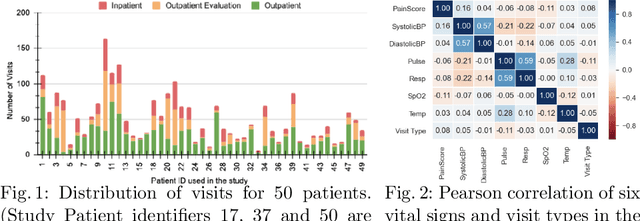
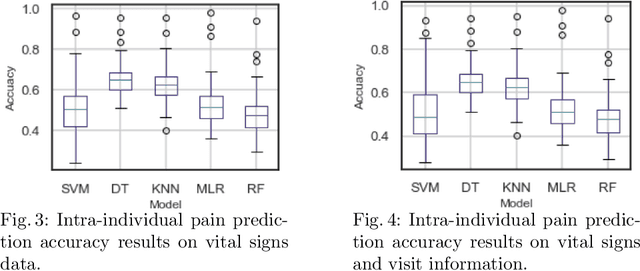
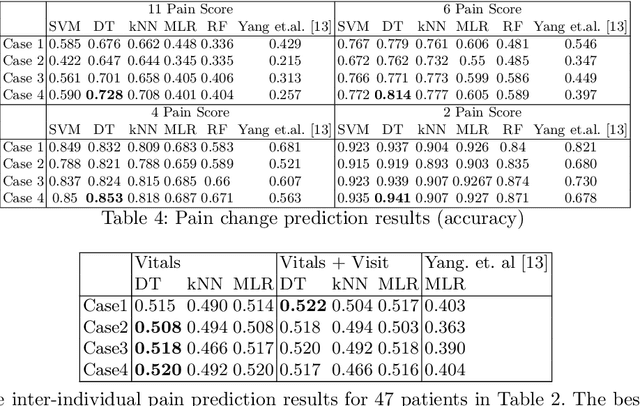
Pain in sickle cell disease (SCD) is often associated with increased morbidity, mortality, and high healthcare costs. The standard method for predicting the absence, presence, and intensity of pain has long been self-report. However, medical providers struggle to manage patients based on subjective pain reports correctly and pain medications often lead to further difficulties in patient communication as they may cause sedation and sleepiness. Recent studies have shown that objective physiological measures can predict subjective self-reported pain scores for inpatient visits using machine learning (ML) techniques. In this study, we evaluate the generalizability of ML techniques to data collected from 50 patients over an extended period across three types of hospital visits (i.e., inpatient, outpatient and outpatient evaluation). We compare five classification algorithms for various pain intensity levels at both intra-individual (within each patient) and inter-individual (between patients) level. While all the tested classifiers perform much better than chance, a Decision Tree (DT) model performs best at predicting pain on an 11-point severity scale (from 0-10) with an accuracy of 0.728 at an inter-individual level and 0.653 at an intra-individual level. The accuracy of DT significantly improves to 0.941 on a 2-point rating scale (i.e., no/mild pain: 0-5, severe pain: 6-10) at an intra-individual level. Our experimental results demonstrate that ML techniques can provide an objective and quantitative evaluation of pain intensity levels for all three types of hospital visits.
COVID-19 and Mental Health/Substance Use Disorders on Reddit: A Longitudinal Study
Nov 20, 2020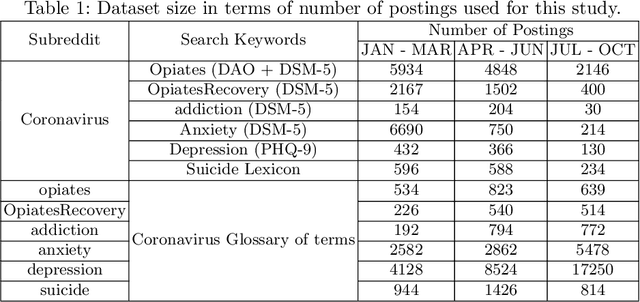
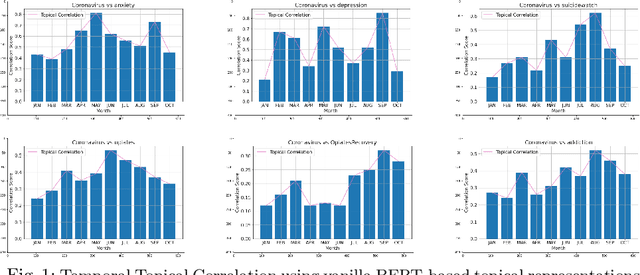
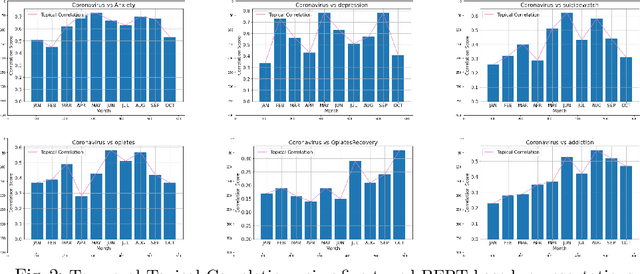

COVID-19 pandemic has adversely and disproportionately impacted people suffering from mental health issues and substance use problems. This has been exacerbated by social isolation during the pandemic and the social stigma associated with mental health and substance use disorders, making people reluctant to share their struggles and seek help. Due to the anonymity and privacy they provide, social media emerged as a convenient medium for people to share their experiences about their day to day struggles. Reddit is a well-recognized social media platform that provides focused and structured forums called subreddits, that users subscribe to and discuss their experiences with others. Temporal assessment of the topical correlation between social media postings about mental health/substance use and postings about Coronavirus is crucial to better understand public sentiment on the pandemic and its evolving impact, especially related to vulnerable populations. In this study, we conduct a longitudinal topical analysis of postings between subreddits r/depression, r/Anxiety, r/SuicideWatch, and r/Coronavirus, and postings between subreddits r/opiates, r/OpiatesRecovery, r/addiction, and r/Coronavirus from January 2020 - October 2020. Our results show a high topical correlation between postings in r/depression and r/Coronavirus in September 2020. Further, the topical correlation between postings on substance use disorders and Coronavirus fluctuates, showing the highest correlation in August 2020. By monitoring these trends from platforms such as Reddit, epidemiologists, and mental health professionals can gain insights into the challenges faced by communities for targeted interventions.
Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles
Nov 03, 2020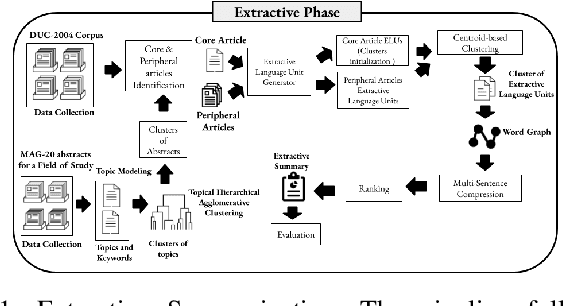


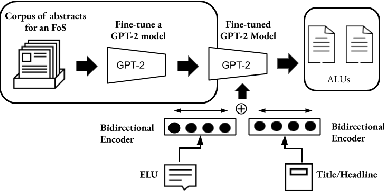
Recent advances in natural language processing have enabled automation of a wide range of tasks, including machine translation, named entity recognition, and sentiment analysis. Automated summarization of documents, or groups of documents, however, has remained elusive, with many efforts limited to extraction of keywords, key phrases, or key sentences. Accurate abstractive summarization has yet to be achieved due to the inherent difficulty of the problem, and limited availability of training data. In this paper, we propose a topic-centric unsupervised multi-document summarization framework to generate extractive and abstractive summaries for groups of scientific articles across 20 Fields of Study (FoS) in Microsoft Academic Graph (MAG) and news articles from DUC-2004 Task 2. The proposed algorithm generates an abstractive summary by developing salient language unit selection and text generation techniques. Our approach matches the state-of-the-art when evaluated on automated extractive evaluation metrics and performs better for abstractive summarization on five human evaluation metrics (entailment, coherence, conciseness, readability, and grammar). We achieve a kappa score of 0.68 between two co-author linguists who evaluated our results. We plan to publicly share MAG-20, a human-validated gold standard dataset of topic-clustered research articles and their summaries to promote research in abstractive summarization.
Measuring Pain in Sickle Cell Disease using Clinical Text
Aug 05, 2020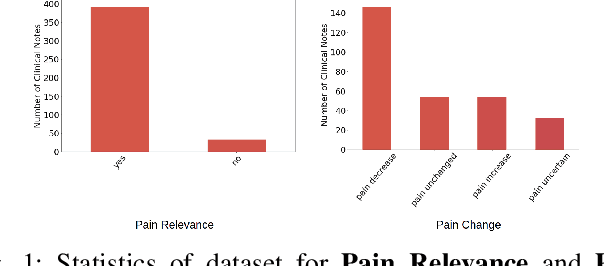
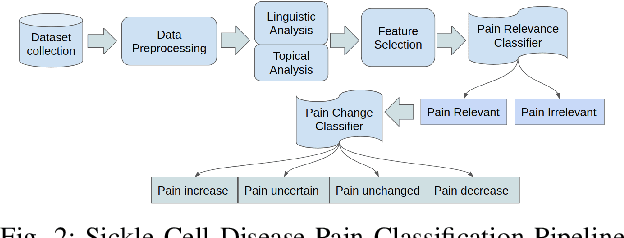
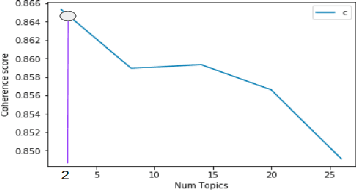
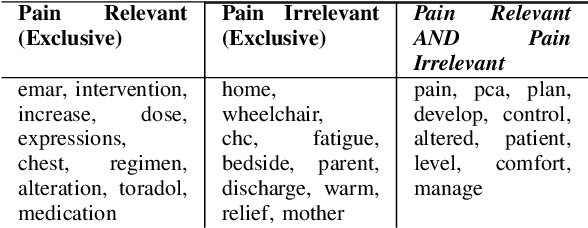
Sickle Cell Disease (SCD) is a hereditary disorder of red blood cells in humans. Complications such as pain, stroke, and organ failure occur in SCD as malformed, sickled red blood cells passing through small blood vessels get trapped. Particularly, acute pain is known to be the primary symptom of SCD. The insidious and subjective nature of SCD pain leads to challenges in pain assessment among Medical Practitioners (MPs). Thus, accurate identification of markers of pain in patients with SCD is crucial for pain management. Classifying clinical notes of patients with SCD based on their pain level enables MPs to give appropriate treatment. We propose a binary classification model to predict pain relevance of clinical notes and a multiclass classification model to predict pain level. While our four binary machine learning (ML) classifiers are comparable in their performance, Decision Trees had the best performance for the multiclass classification task achieving 0.70 in F-measure. Our results show the potential clinical text analysis and machine learning offer to pain management in sickle cell patients.
Modeling Islamist Extremist Communications on Social Media using Contextual Dimensions: Religion, Ideology, and Hate
Aug 20, 2019
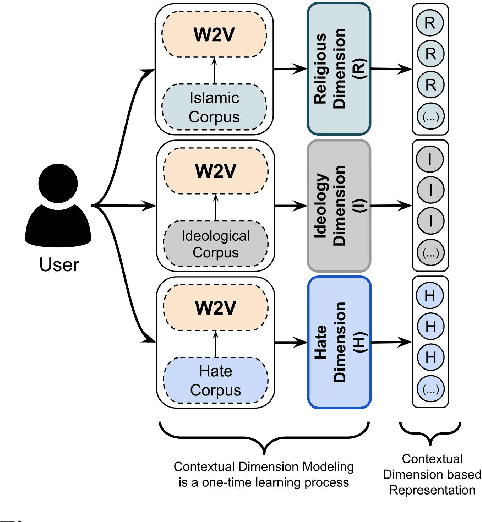
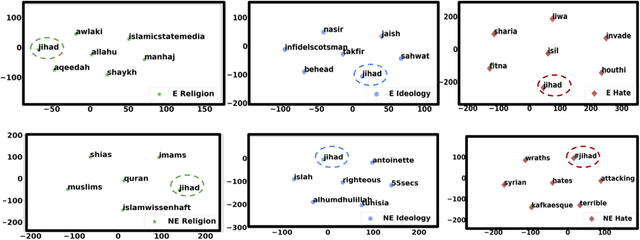
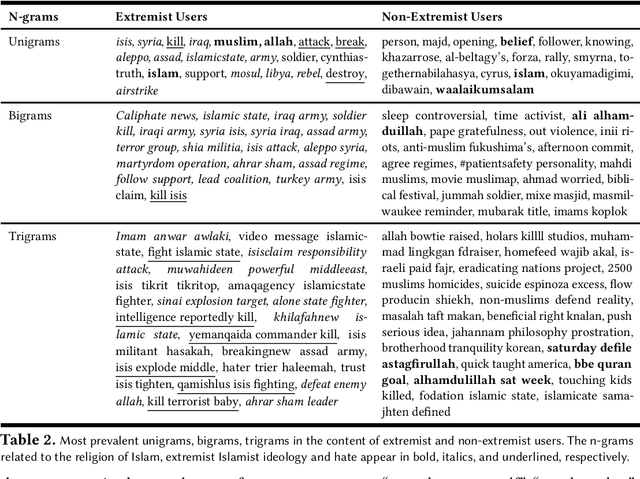
Terror attacks have been linked in part to online extremist content. Although tens of thousands of Islamist extremism supporters consume such content, they are a small fraction relative to peaceful Muslims. The efforts to contain the ever-evolving extremism on social media platforms have remained inadequate and mostly ineffective. Divergent extremist and mainstream contexts challenge machine interpretation, with a particular threat to the precision of classification algorithms. Our context-aware computational approach to the analysis of extremist content on Twitter breaks down this persuasion process into building blocks that acknowledge inherent ambiguity and sparsity that likely challenge both manual and automated classification. We model this process using a combination of three contextual dimensions -- religion, ideology, and hate -- each elucidating a degree of radicalization and highlighting independent features to render them computationally accessible. We utilize domain-specific knowledge resources for each of these contextual dimensions such as Qur'an for religion, the books of extremist ideologues and preachers for political ideology and a social media hate speech corpus for hate. Our study makes three contributions to reliable analysis: (i) Development of a computational approach rooted in the contextual dimensions of religion, ideology, and hate that reflects strategies employed by online Islamist extremist groups, (ii) An in-depth analysis of relevant tweet datasets with respect to these dimensions to exclude likely mislabeled users, and (iii) A framework for understanding online radicalization as a process to assist counter-programming. Given the potentially significant social impact, we evaluate the performance of our algorithms to minimize mislabeling, where our approach outperforms a competitive baseline by 10.2% in precision.