 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Echo Chamber Multi-Turn LLM Jailbreak
Jan 09, 2026The availability of Large Language Models (LLMs) has led to a new generation of powerful chatbots that can be developed at relatively low cost. As companies deploy these tools, security challenges need to be addressed to prevent financial loss and reputational damage. A key security challenge is jailbreaking, the malicious manipulation of prompts and inputs to bypass a chatbot's safety guardrails. Multi-turn attacks are a relatively new form of jailbreaking involving a carefully crafted chain of interactions with a chatbot. We introduce Echo Chamber, a new multi-turn attack using a gradual escalation method. We describe this attack in detail, compare it to other multi-turn attacks, and demonstrate its performance against multiple state-of-the-art models through extensive evaluation.
Synthetic CVs To Build and Test Fairness-Aware Hiring Tools
Aug 28, 2025Algorithmic hiring has become increasingly necessary in some sectors as it promises to deal with hundreds or even thousands of applicants. At the heart of these systems are algorithms designed to retrieve and rank candidate profiles, which are usually represented by Curricula Vitae (CVs). Research has shown, however, that such technologies can inadvertently introduce bias, leading to discrimination based on factors such as candidates' age, gender, or national origin. Developing methods to measure, mitigate, and explain bias in algorithmic hiring, as well as to evaluate and compare fairness techniques before deployment, requires sets of CVs that reflect the characteristics of people from diverse backgrounds. However, datasets of these characteristics that can be used to conduct this research do not exist. To address this limitation, this paper introduces an approach for building a synthetic dataset of CVs with features modeled on real materials collected through a data donation campaign. Additionally, the resulting dataset of 1,730 CVs is presented, which we envision as a potential benchmarking standard for research on algorithmic hiring discrimination.
Disparate Model Performance and Stability in Machine Learning Clinical Support for Diabetes and Heart Diseases
Dec 27, 2024



Machine Learning (ML) algorithms are vital for supporting clinical decision-making in biomedical informatics. However, their predictive performance can vary across demographic groups, often due to the underrepresentation of historically marginalized populations in training datasets. The investigation reveals widespread sex- and age-related inequities in chronic disease datasets and their derived ML models. Thus, a novel analytical framework is introduced, combining systematic arbitrariness with traditional metrics like accuracy and data complexity. The analysis of data from over 25,000 individuals with chronic diseases revealed mild sex-related disparities, favoring predictive accuracy for males, and significant age-related differences, with better accuracy for younger patients. Notably, older patients showed inconsistent predictive accuracy across seven datasets, linked to higher data complexity and lower model performance. This highlights that representativeness in training data alone does not guarantee equitable outcomes, and model arbitrariness must be addressed before deploying models in clinical settings.
Understanding and Addressing Gender Bias in Expert Finding Task
Jul 07, 2024



The Expert Finding (EF) task is critical in community Question&Answer (CQ&A) platforms, significantly enhancing user engagement by improving answer quality and reducing response times. However, biases, especially gender biases, have been identified in these platforms. This study investigates gender bias in state-of-the-art EF models and explores methods to mitigate it. Utilizing a comprehensive dataset from StackOverflow, the largest community in the StackExchange network, we conduct extensive experiments to analyze how EF models' candidate identification processes influence gender representation. Our findings reveal that models relying on reputation metrics and activity levels disproportionately favor male users, who are more active on the platform. This bias results in the underrepresentation of female experts in the ranking process. We propose adjustments to EF models that incorporate a more balanced preprocessing strategy and leverage content-based and social network-based information, with the aim to provide a fairer representation of genders among identified experts. Our analysis shows that integrating these methods can significantly enhance gender balance without compromising model accuracy. To the best of our knowledge, this study is the first to focus on detecting and mitigating gender bias in EF methods.
Responsible AI Research Needs Impact Statements Too
Nov 20, 2023All types of research, development, and policy work can have unintended, adverse consequences - work in responsible artificial intelligence (RAI), ethical AI, or ethics in AI is no exception.
Disparity, Inequality, and Accuracy Tradeoffs in Graph Neural Networks for Node Classification
Aug 18, 2023



Graph neural networks (GNNs) are increasingly used in critical human applications for predicting node labels in attributed graphs. Their ability to aggregate features from nodes' neighbors for accurate classification also has the capacity to exacerbate existing biases in data or to introduce new ones towards members from protected demographic groups. Thus, it is imperative to quantify how GNNs may be biased and to what extent their harmful effects may be mitigated. To this end, we propose two new GNN-agnostic interventions namely, (i) PFR-AX which decreases the separability between nodes in protected and non-protected groups, and (ii) PostProcess which updates model predictions based on a blackbox policy to minimize differences between error rates across demographic groups. Through a large set of experiments on four datasets, we frame the efficacies of our approaches (and three variants) in terms of their algorithmic fairness-accuracy tradeoff and benchmark our results against three strong baseline interventions on three state-of-the-art GNN models. Our results show that no single intervention offers a universally optimal tradeoff, but PFR-AX and PostProcess provide granular control and improve model confidence when correctly predicting positive outcomes for nodes in protected groups.
Fairness and Diversity in Information Access Systems
May 16, 2023Among the seven key requirements to achieve trustworthy AI proposed by the High-Level Expert Group on Artificial Intelligence (AI-HLEG) established by the European Commission (EC), the fifth requirement ("Diversity, non-discrimination and fairness") declares: "In order to achieve Trustworthy AI, we must enable inclusion and diversity throughout the entire AI system's life cycle. [...] This requirement is closely linked with the principle of fairness". In this paper, we try to shed light on how closely these two distinct concepts, diversity and fairness, may be treated by focusing on information access systems and ranking literature. These concepts should not be used interchangeably because they do represent two different values, but what we argue is that they also cannot be considered totally unrelated or divergent. Having diversity does not imply fairness, but fostering diversity can effectively lead to fair outcomes, an intuition behind several methods proposed to mitigate the disparate impact of information access systems, i.e. recommender systems and search engines.
Assessing the Impact of Music Recommendation Diversity on Listeners: A Longitudinal Study
Dec 01, 2022



We present the results of a 12-week longitudinal user study wherein the participants, 110 subjects from Southern Europe, received on a daily basis Electronic Music (EM) diversified recommendations. By analyzing their explicit and implicit feedback, we show that exposure to specific levels of music recommendation diversity may be responsible for long-term impacts on listeners' attitudes. In particular, we highlight the function of diversity in increasing the openness in listening to EM, a music genre not particularly known or liked by the participants previous to their participation in the study. Moreover, we demonstrate that recommendations may help listeners in removing positive and negative attachments towards EM, deconstructing pre-existing implicit associations but also stereotypes associated with this music. In addition, our results show the significant clout that recommendation diversity has in generating curiosity in listeners.
Cross-Lingual Query-Based Summarization of Crisis-Related Social Media: An Abstractive Approach Using Transformers
Apr 21, 2022



Relevant and timely information collected from social media during crises can be an invaluable resource for emergency management. However, extracting this information remains a challenging task, particularly when dealing with social media postings in multiple languages. This work proposes a cross-lingual method for retrieving and summarizing crisis-relevant information from social media postings. We describe a uniform way of expressing various information needs through structured queries and a way of creating summaries answering those information needs. The method is based on multilingual transformers embeddings. Queries are written in one of the languages supported by the embeddings, and the extracted sentences can be in any of the other languages supported. Abstractive summaries are created by transformers. The evaluation, done by crowdsourcing evaluators and emergency management experts, and carried out on collections extracted from Twitter during five large-scale disasters spanning ten languages, shows the flexibility of our approach. The generated summaries are regarded as more focused, structured, and coherent than existing state-of-the-art methods, and experts compare them favorably against summaries created by existing, state-of-the-art methods.
Human Response to an AI-Based Decision Support System: A User Study on the Effects of Accuracy and Bias
Mar 24, 2022
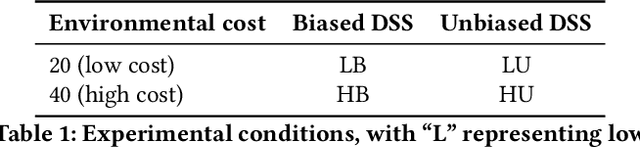
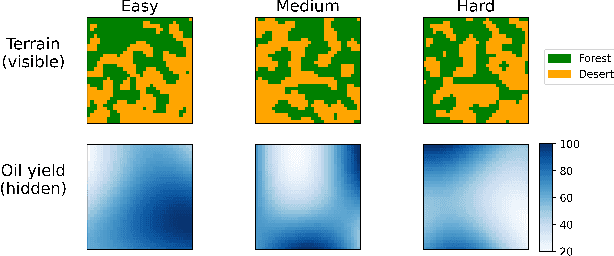
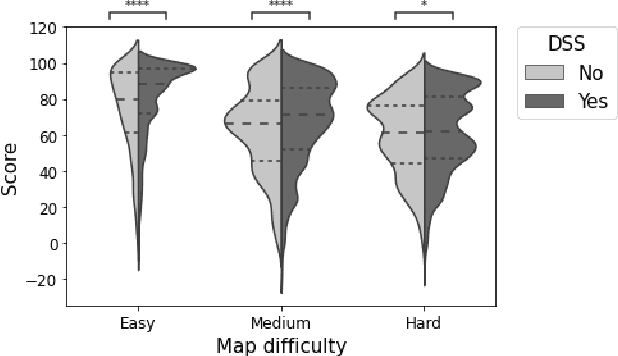
Artificial Intelligence (AI) is increasingly used to build Decision Support Systems (DSS) across many domains. This paper describes a series of experiments designed to observe human response to different characteristics of a DSS such as accuracy and bias, particularly the extent to which participants rely on the DSS, and the performance they achieve. In our experiments, participants play a simple online game inspired by so-called "wildcat" (i.e., exploratory) drilling for oil. The landscape has two layers: a visible layer describing the costs (terrain), and a hidden layer describing the reward (oil yield). Participants in the control group play the game without receiving any assistance, while in treatment groups they are assisted by a DSS suggesting places to drill. For certain treatments, the DSS does not consider costs, but only rewards, which introduces a bias that is observable by users. Between subjects, we vary the accuracy and bias of the DSS, and observe the participants' total score, time to completion, the extent to which they follow or ignore suggestions. We also measure the acceptability of the DSS in an exit survey. Our results show that participants tend to score better with the DSS, that the score increase is due to users following the DSS advice, and related to the difficulty of the game and the accuracy of the DSS. We observe that this setting elicits mostly rational behavior from participants, who place a moderate amount of trust in the DSS and show neither algorithmic aversion (under-reliance) nor automation bias (over-reliance).However, their stated willingness to accept the DSS in the exit survey seems less sensitive to the accuracy of the DSS than their behavior, suggesting that users are only partially aware of the (lack of) accuracy of the DSS.