 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe explanation dialogues: an expert focus study to understand requirements towards explanations within the GDPR
Jan 09, 2025



Explainable AI (XAI) provides methods to understand non-interpretable machine learning models. However, we have little knowledge about what legal experts expect from these explanations, including their legal compliance with, and value against European Union legislation. To close this gap, we present the Explanation Dialogues, an expert focus study to uncover the expectations, reasoning, and understanding of legal experts and practitioners towards XAI, with a specific focus on the European General Data Protection Regulation. The study consists of an online questionnaire and follow-up interviews, and is centered around a use-case in the credit domain. We extract both a set of hierarchical and interconnected codes using grounded theory, and present the standpoints of the participating experts towards XAI. We find that the presented explanations are hard to understand and lack information, and discuss issues that can arise from the different interests of the data controller and subject. Finally, we present a set of recommendations for developers of XAI methods, and indications of legal areas of discussion. Among others, recommendations address the presentation, choice, and content of an explanation, technical risks as well as the end-user, while we provide legal pointers to the contestability of explanations, transparency thresholds, intellectual property rights as well as the relationship between involved parties.
Human Response to an AI-Based Decision Support System: A User Study on the Effects of Accuracy and Bias
Mar 24, 2022
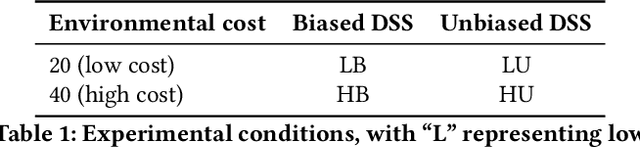
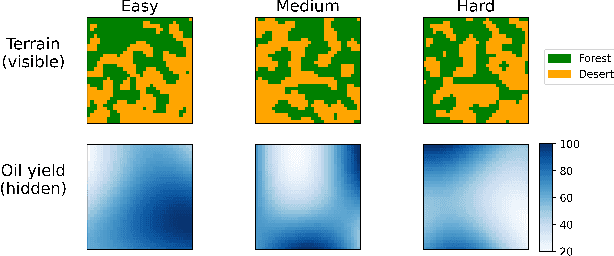
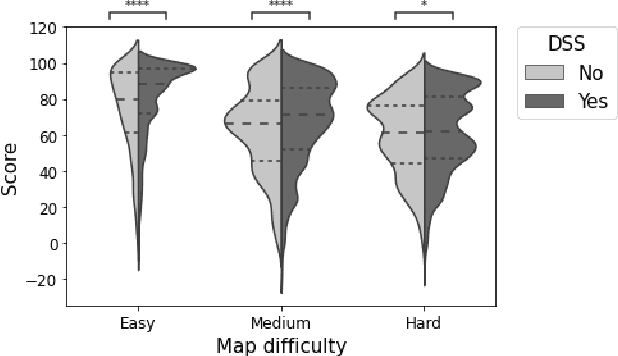
Artificial Intelligence (AI) is increasingly used to build Decision Support Systems (DSS) across many domains. This paper describes a series of experiments designed to observe human response to different characteristics of a DSS such as accuracy and bias, particularly the extent to which participants rely on the DSS, and the performance they achieve. In our experiments, participants play a simple online game inspired by so-called "wildcat" (i.e., exploratory) drilling for oil. The landscape has two layers: a visible layer describing the costs (terrain), and a hidden layer describing the reward (oil yield). Participants in the control group play the game without receiving any assistance, while in treatment groups they are assisted by a DSS suggesting places to drill. For certain treatments, the DSS does not consider costs, but only rewards, which introduces a bias that is observable by users. Between subjects, we vary the accuracy and bias of the DSS, and observe the participants' total score, time to completion, the extent to which they follow or ignore suggestions. We also measure the acceptability of the DSS in an exit survey. Our results show that participants tend to score better with the DSS, that the score increase is due to users following the DSS advice, and related to the difficulty of the game and the accuracy of the DSS. We observe that this setting elicits mostly rational behavior from participants, who place a moderate amount of trust in the DSS and show neither algorithmic aversion (under-reliance) nor automation bias (over-reliance).However, their stated willingness to accept the DSS in the exit survey seems less sensitive to the accuracy of the DSS than their behavior, suggesting that users are only partially aware of the (lack of) accuracy of the DSS.
Explainable Deep Image Classifiers for Skin Lesion Diagnosis
Nov 22, 2021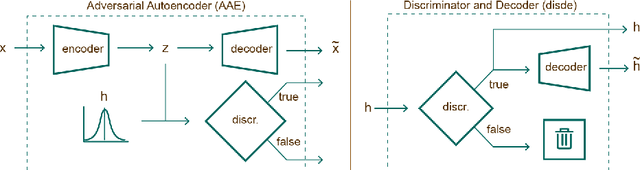
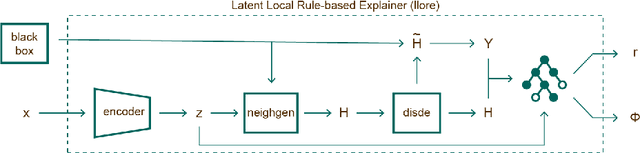
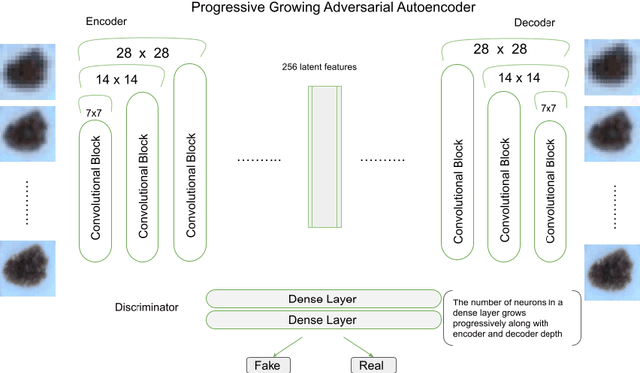
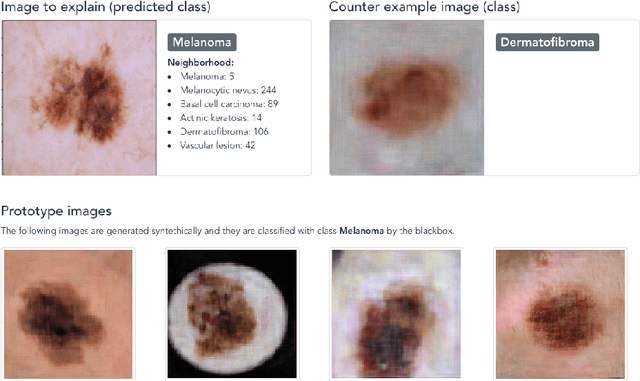
A key issue in critical contexts such as medical diagnosis is the interpretability of the deep learning models adopted in decision-making systems. Research in eXplainable Artificial Intelligence (XAI) is trying to solve this issue. However, often XAI approaches are only tested on generalist classifier and do not represent realistic problems such as those of medical diagnosis. In this paper, we analyze a case study on skin lesion images where we customize an existing XAI approach for explaining a deep learning model able to recognize different types of skin lesions. The explanation is formed by synthetic exemplar and counter-exemplar images of skin lesion and offers the practitioner a way to highlight the crucial traits responsible for the classification decision. A survey conducted with domain experts, beginners and unskilled people proof that the usage of explanations increases the trust and confidence in the automatic decision system. Also, an analysis of the latent space adopted by the explainer unveils that some of the most frequent skin lesion classes are distinctly separated. This phenomenon could derive from the intrinsic characteristics of each class and, hopefully, can provide support in the resolution of the most frequent misclassifications by human experts.