 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI in Time-Sensitive Scenarios: Prefetched Offline Explanation Model
Mar 06, 2025As predictive machine learning models become increasingly adopted and advanced, their role has evolved from merely predicting outcomes to actively shaping them. This evolution has underscored the importance of Trustworthy AI, highlighting the necessity to extend our focus beyond mere accuracy and toward a comprehensive understanding of these models' behaviors within the specific contexts of their applications. To further progress in explainability, we introduce Poem, Prefetched Offline Explanation Model, a model-agnostic, local explainability algorithm for image data. The algorithm generates exemplars, counterexemplars and saliency maps to provide quick and effective explanations suitable for time-sensitive scenarios. Leveraging an existing local algorithm, \poem{} infers factual and counterfactual rules from data to create illustrative examples and opposite scenarios with an enhanced stability by design. A novel mechanism then matches incoming test points with an explanation base and produces diverse exemplars, informative saliency maps and believable counterexemplars. Experimental results indicate that Poem outperforms its predecessor Abele in speed and ability to generate more nuanced and varied exemplars alongside more insightful saliency maps and valuable counterexemplars.
Achieving Predictive Precision: Leveraging LSTM and Pseudo Labeling for Volvo's Discovery Challenge at ECML-PKDD 2024
Sep 20, 2024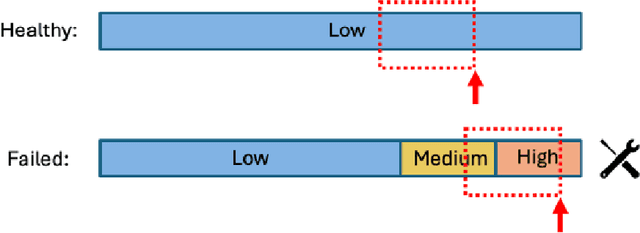
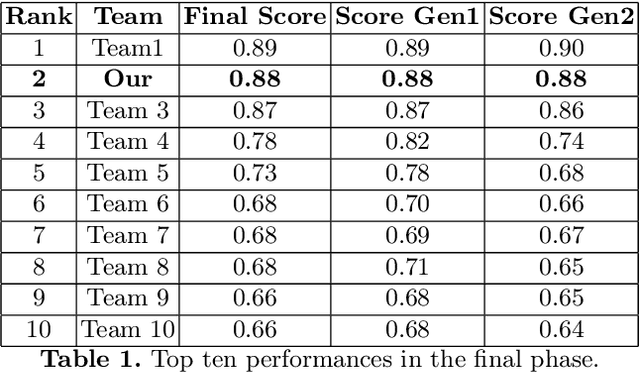
This paper presents the second-place methodology in the Volvo Discovery Challenge at ECML-PKDD 2024, where we used Long Short-Term Memory networks and pseudo-labeling to predict maintenance needs for a component of Volvo trucks. We processed the training data to mirror the test set structure and applied a base LSTM model to label the test data iteratively. This approach refined our model's predictive capabilities and culminated in a macro-average F1-score of 0.879, demonstrating robust performance in predictive maintenance. This work provides valuable insights for applying machine learning techniques effectively in industrial settings.
Volvo Discovery Challenge at ECML-PKDD 2024
Sep 17, 2024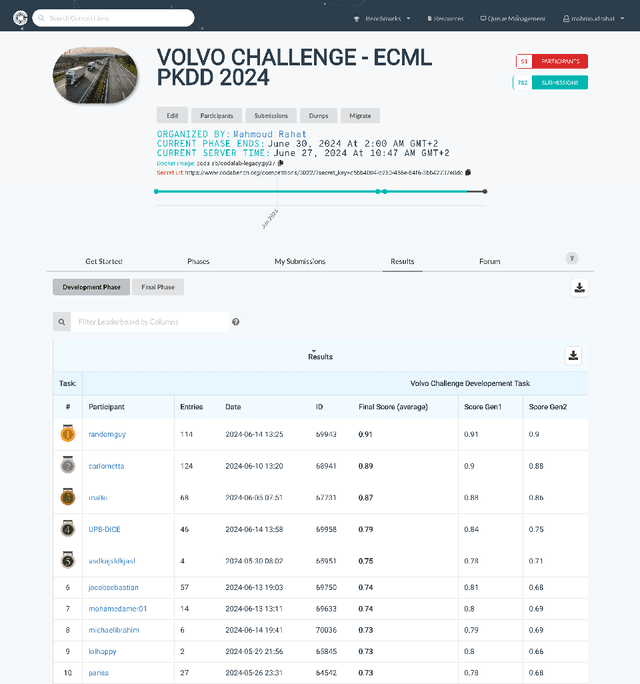


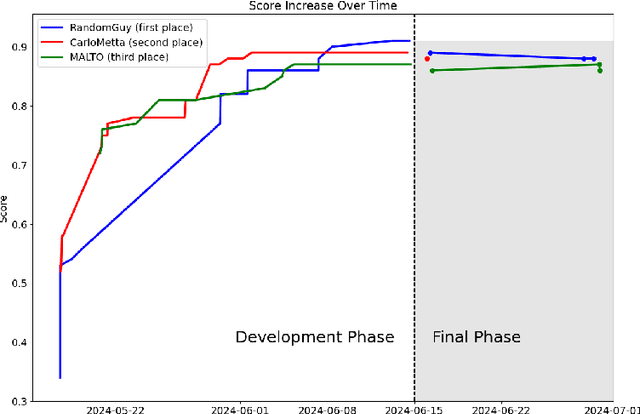
This paper presents an overview of the Volvo Discovery Challenge, held during the ECML-PKDD 2024 conference. The challenge's goal was to predict the failure risk of an anonymized component in Volvo trucks using a newly published dataset. The test data included observations from two generations (gen1 and gen2) of the component, while the training data was provided only for gen1. The challenge attracted 52 data scientists from around the world who submitted a total of 791 entries. We provide a brief description of the problem definition, challenge setup, and statistics about the submissions. In the section on winning methodologies, the first, second, and third-place winners of the competition briefly describe their proposed methods and provide GitHub links to their implemented code. The shared code can be interesting as an advanced methodology for researchers in the predictive maintenance domain. The competition was hosted on the Codabench platform.
A Systematization of the Wagner Framework: Graph Theory Conjectures and Reinforcement Learning
Jun 18, 2024In 2021, Adam Zsolt Wagner proposed an approach to disprove conjectures in graph theory using Reinforcement Learning (RL). Wagner's idea can be framed as follows: consider a conjecture, such as a certain quantity f(G) < 0 for every graph G; one can then play a single-player graph-building game, where at each turn the player decides whether to add an edge or not. The game ends when all edges have been considered, resulting in a certain graph G_T, and f(G_T) is the final score of the game; RL is then used to maximize this score. This brilliant idea is as simple as innovative, and it lends itself to systematic generalization. Several different single-player graph-building games can be employed, along with various RL algorithms. Moreover, RL maximizes the cumulative reward, allowing for step-by-step rewards instead of a single final score, provided the final cumulative reward represents the quantity of interest f(G_T). In this paper, we discuss these and various other choices that can be significant in Wagner's framework. As a contribution to this systematization, we present four distinct single-player graph-building games. Each game employs both a step-by-step reward system and a single final score. We also propose a principled approach to select the most suitable neural network architecture for any given conjecture, and introduce a new dataset of graphs labeled with their Laplacian spectra. Furthermore, we provide a counterexample for a conjecture regarding the sum of the matching number and the spectral radius, which is simpler than the example provided in Wagner's original paper. The games have been implemented as environments in the Gymnasium framework, and along with the dataset, are available as open-source supplementary materials.
GloNets: Globally Connected Neural Networks
Nov 27, 2023Deep learning architectures suffer from depth-related performance degradation, limiting the effective depth of neural networks. Approaches like ResNet are able to mitigate this, but they do not completely eliminate the problem. We introduce Globally Connected Neural Networks (GloNet), a novel architecture overcoming depth-related issues, designed to be superimposed on any model, enhancing its depth without increasing complexity or reducing performance. With GloNet, the network's head uniformly receives information from all parts of the network, regardless of their level of abstraction. This enables GloNet to self-regulate information flow during training, reducing the influence of less effective deeper layers, and allowing for stable training irrespective of network depth. This paper details GloNet's design, its theoretical basis, and a comparison with existing similar architectures. Experiments show GloNet's self-regulation ability and resilience to depth-related learning challenges, like performance degradation. Our findings suggest GloNet as a strong alternative to traditional architectures like ResNets.
Improving Performance in Neural Networks by Dendrites-Activated Connections
Jan 03, 2023Computational units in artificial neural networks follow a simplified model of biological neurons. In the biological model, the output signal of a neuron runs down the axon, splits following the many branches at its end, and passes identically to all the downward neurons of the network. Each of the downward neurons will use their copy of this signal as one of many inputs dendrites, integrate them all and fire an output, if above some threshold. In the artificial neural network, this translates to the fact that the nonlinear filtering of the signal is performed in the upward neuron, meaning that in practice the same activation is shared between all the downward neurons that use that signal as their input. Dendrites thus play a passive role. We propose a slightly more complex model for the biological neuron, where dendrites play an active role: the activation in the output of the upward neuron becomes optional, and instead the signals going through each dendrite undergo independent nonlinear filterings, before the linear combination. We implement this new model into a ReLU computational unit and discuss its biological plausibility. We compare this new computational unit with the standard one and describe it from a geometrical point of view. We provide a Keras implementation of this unit into fully connected and convolutional layers and estimate their FLOPs and weights change. We then use these layers in ResNet architectures on CIFAR-10, CIFAR-100, Imagenette, and Imagewoof, obtaining performance improvements over standard ResNets up to 1.73%. Finally, we prove a universal representation theorem for continuous functions on compact sets and show that this new unit has more representational power than its standard counterpart.
Artificial intelligence and renegotiation of commercial lease contracts affected by pandemic-related contingencies from Covid-19. The project A.I.A.Co
Oct 14, 2022
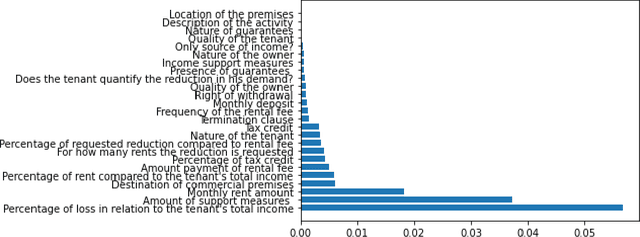
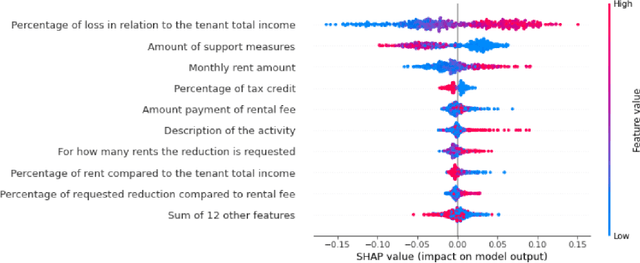
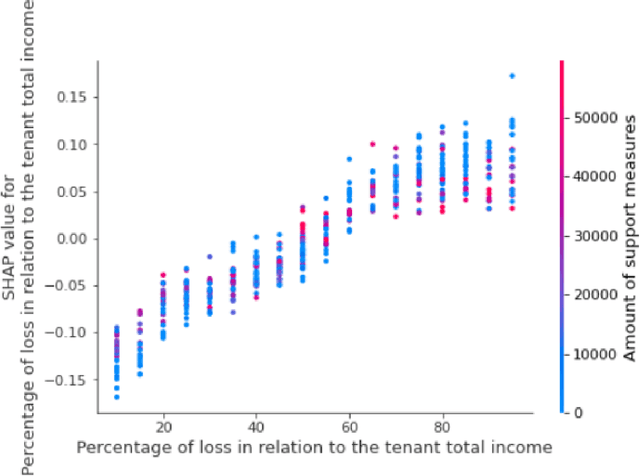
This paper aims to investigate the possibility of using artificial intelligence (AI) to resolve the legal issues raised by the Covid-19 emergency about the fate of continuing execution contracts, or those with deferred or periodic execution, as well as, more generally, to deal with exceptional events and contingencies. We first study whether the Italian legal system allows for ''maintenance'' remedies to cope with contingencies and to avoid the termination of the contract, while ensuring effective protection of the interests of both parties. We then give a complete and technical description of an AI-based predictive framework, aimed at assisting both the Magistrate (in the course of litigation) and the parties themselves (in out-of-court proceedings) in the redetermination of the rent of commercial lease contracts. This framework, called A.I.A.Co. for Artificial Intelligence for contract law Against Covid-19, has been developed under the Italian grant ''Fondo Integrativo Speciale per la Ricerca''.
Leela Zero Score: a Study of a Score-based AlphaGo Zero
Jan 31, 2022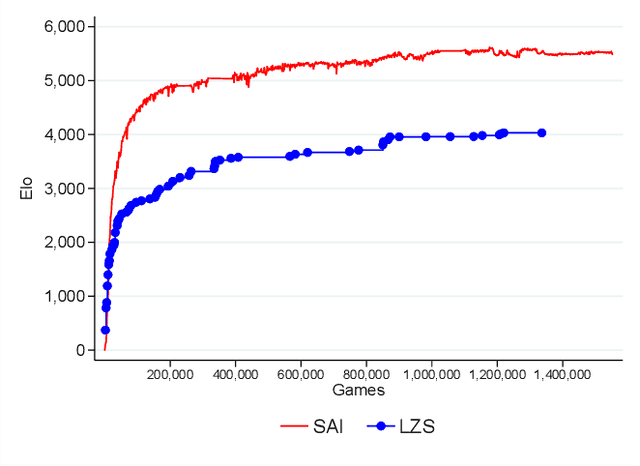
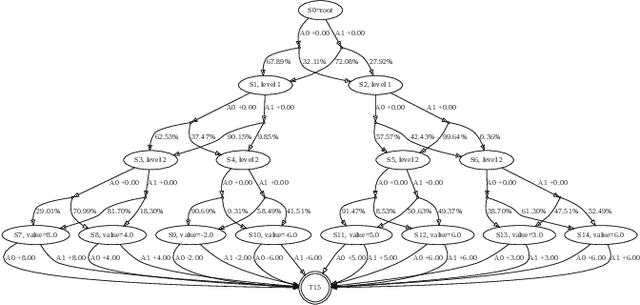
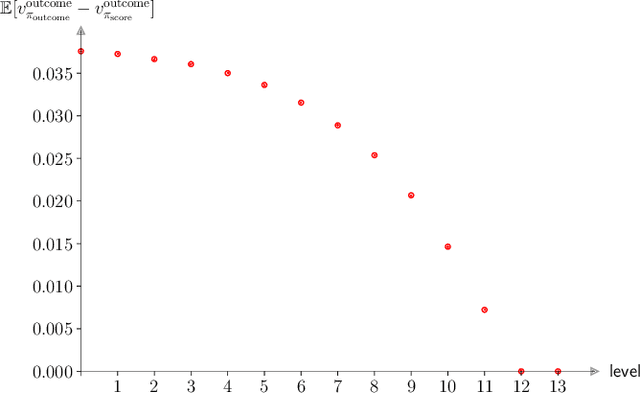
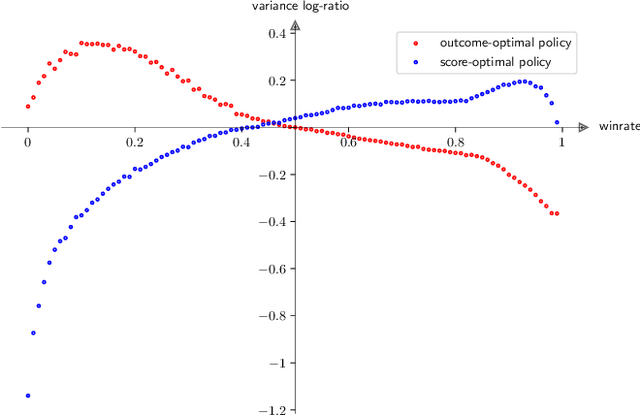
AlphaGo, AlphaGo Zero, and all of their derivatives can play with superhuman strength because they are able to predict the win-lose outcome with great accuracy. However, Go as a game is decided by a final score difference, and in final positions AlphaGo plays suboptimal moves: this is not surprising, since AlphaGo is completely unaware of the final score difference, all winning final positions being equivalent from the winrate perspective. This can be an issue, for instance when trying to learn the "best" move or to play with an initial handicap. Moreover, there is the theoretical quest of the "perfect game", that is, the minimax solution. Thus, a natural question arises: is it possible to train a successful Reinforcement Learning agent to predict score differences instead of winrates? No empirical or theoretical evidence can be found in the literature to support the folklore statement that "this does not work". In this paper we present Leela Zero Score, a software designed to support or disprove the "does not work" statement. Leela Zero Score is designed on the open-source solution known as Leela Zero, and is trained on a 9x9 board to predict score differences instead of winrates. We find that the training produces a rational player, and we analyze its style against a strong amateur human player, to find that it is prone to some mistakes when the outcome is close. We compare its strength against SAI, an AlphaGo Zero-like software working on the 9x9 board, and find that the training of Leela Zero Score has reached a premature convergence to a player weaker than SAI.
Explainable Deep Image Classifiers for Skin Lesion Diagnosis
Nov 22, 2021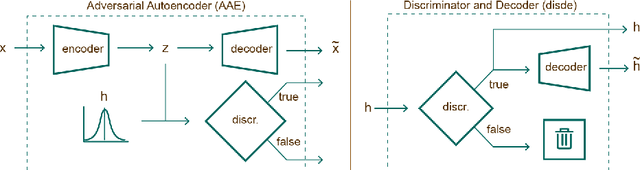
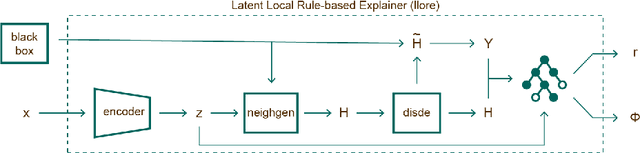
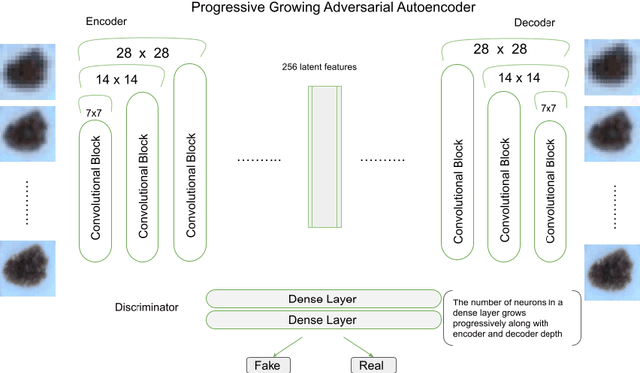
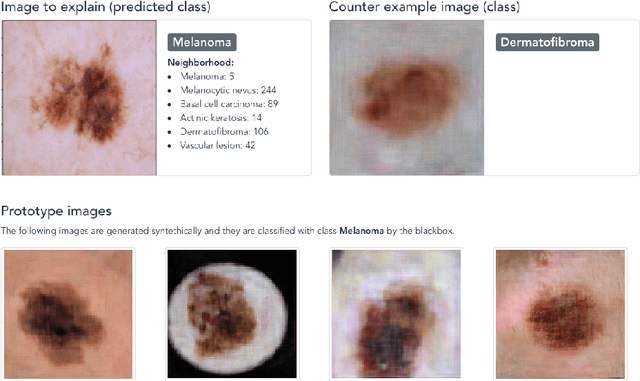
A key issue in critical contexts such as medical diagnosis is the interpretability of the deep learning models adopted in decision-making systems. Research in eXplainable Artificial Intelligence (XAI) is trying to solve this issue. However, often XAI approaches are only tested on generalist classifier and do not represent realistic problems such as those of medical diagnosis. In this paper, we analyze a case study on skin lesion images where we customize an existing XAI approach for explaining a deep learning model able to recognize different types of skin lesions. The explanation is formed by synthetic exemplar and counter-exemplar images of skin lesion and offers the practitioner a way to highlight the crucial traits responsible for the classification decision. A survey conducted with domain experts, beginners and unskilled people proof that the usage of explanations increases the trust and confidence in the automatic decision system. Also, an analysis of the latent space adopted by the explainer unveils that some of the most frequent skin lesion classes are distinctly separated. This phenomenon could derive from the intrinsic characteristics of each class and, hopefully, can provide support in the resolution of the most frequent misclassifications by human experts.
SAI: a Sensible Artificial Intelligence that plays with handicap and targets high scores in 9x9 Go (extended version)
May 26, 2019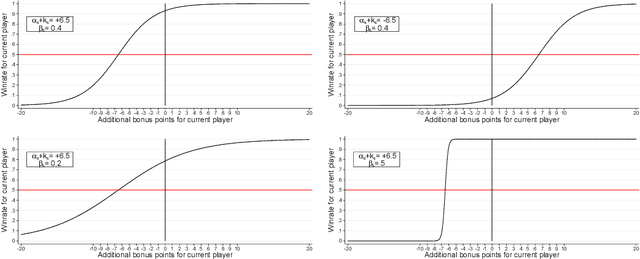
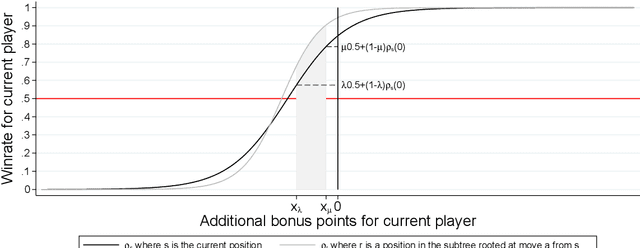
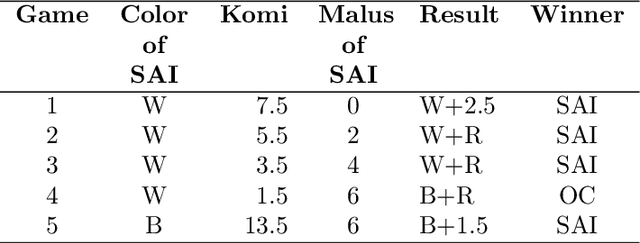
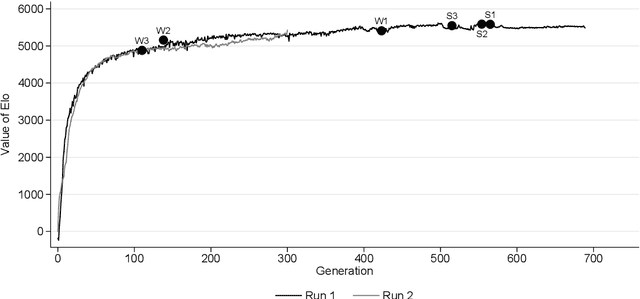
We develop a new model that can be applied to any perfect information two-player zero-sum game to target a high score, and thus a perfect play. We integrate this model into the Monte Carlo tree search-policy iteration learning pipeline introduced by Google DeepMind with AlphaGo. Training this model on 9x9 Go produces a superhuman Go player, thus proving that it is stable and robust. We show that this model can be used to effectively play with both positional and score handicap. We develop a family of agents that can target high scores against any opponent, and recover from very severe disadvantage against weak opponents. To the best of our knowledge, these are the first effective achievements in this direction.