 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectures for Building Agentic AI
Dec 10, 2025

This chapter argues that the reliability of agentic and generative AI is chiefly an architectural property. We define agentic systems as goal-directed, tool-using decision makers operating in closed loops, and show how reliability emerges from principled componentisation (goal manager, planner, tool-router, executor, memory, verifiers, safety monitor, telemetry), disciplined interfaces (schema-constrained, validated, least-privilege tool calls), and explicit control and assurance loops. Building on classical foundations, we propose a practical taxonomy-tool-using agents, memory-augmented agents, planning and self-improvement agents, multi-agent systems, and embodied or web agents - and analyse how each pattern reshapes the reliability envelope and failure modes. We distil design guidance on typed schemas, idempotency, permissioning, transactional semantics, memory provenance and hygiene, runtime governance (budgets, termination conditions), and simulate-before-actuate safeguards.
Volvo Discovery Challenge at ECML-PKDD 2024
Sep 17, 2024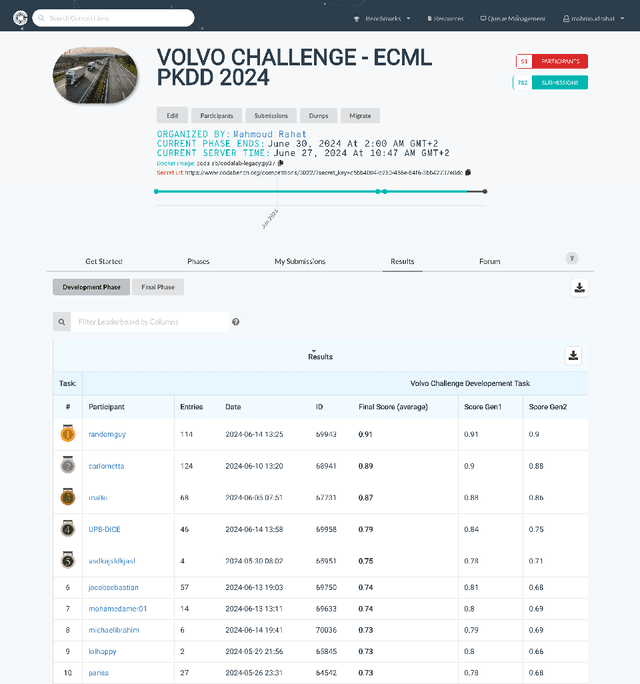


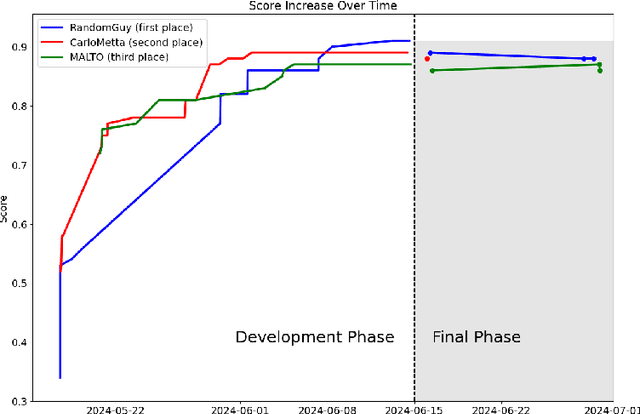
This paper presents an overview of the Volvo Discovery Challenge, held during the ECML-PKDD 2024 conference. The challenge's goal was to predict the failure risk of an anonymized component in Volvo trucks using a newly published dataset. The test data included observations from two generations (gen1 and gen2) of the component, while the training data was provided only for gen1. The challenge attracted 52 data scientists from around the world who submitted a total of 791 entries. We provide a brief description of the problem definition, challenge setup, and statistics about the submissions. In the section on winning methodologies, the first, second, and third-place winners of the competition briefly describe their proposed methods and provide GitHub links to their implemented code. The shared code can be interesting as an advanced methodology for researchers in the predictive maintenance domain. The competition was hosted on the Codabench platform.
Rolling the dice for better deep learning performance: A study of randomness techniques in deep neural networks
Apr 05, 2024This paper investigates how various randomization techniques impact Deep Neural Networks (DNNs). Randomization, like weight noise and dropout, aids in reducing overfitting and enhancing generalization, but their interactions are poorly understood. The study categorizes randomness techniques into four types and proposes new methods: adding noise to the loss function and random masking of gradient updates. Using Particle Swarm Optimizer (PSO) for hyperparameter optimization, it explores optimal configurations across MNIST, FASHION-MNIST, CIFAR10, and CIFAR100 datasets. Over 30,000 configurations are evaluated, revealing data augmentation and weight initialization randomness as main performance contributors. Correlation analysis shows different optimizers prefer distinct randomization types. The complete implementation and dataset are available on GitHub.
Fast Genetic Algorithm for feature selection -- A qualitative approximation approach
Apr 05, 2024Evolutionary Algorithms (EAs) are often challenging to apply in real-world settings since evolutionary computations involve a large number of evaluations of a typically expensive fitness function. For example, an evaluation could involve training a new machine learning model. An approximation (also known as meta-model or a surrogate) of the true function can be used in such applications to alleviate the computation cost. In this paper, we propose a two-stage surrogate-assisted evolutionary approach to address the computational issues arising from using Genetic Algorithm (GA) for feature selection in a wrapper setting for large datasets. We define 'Approximation Usefulness' to capture the necessary conditions to ensure correctness of the EA computations when an approximation is used. Based on this definition, we propose a procedure to construct a lightweight qualitative meta-model by the active selection of data instances. We then use a meta-model to carry out the feature selection task. We apply this procedure to the GA-based algorithm CHC (Cross generational elitist selection, Heterogeneous recombination and Cataclysmic mutation) to create a Qualitative approXimations variant, CHCQX. We show that CHCQX converges faster to feature subset solutions of significantly higher accuracy (as compared to CHC), particularly for large datasets with over 100K instances. We also demonstrate the applicability of the thinking behind our approach more broadly to Swarm Intelligence (SI), another branch of the Evolutionary Computation (EC) paradigm with results of PSOQX, a qualitative approximation adaptation of the Particle Swarm Optimization (PSO) method. A GitHub repository with the complete implementation is available.
Beyond Random Noise: Insights on Anonymization Strategies from a Latent Bandit Study
Sep 30, 2023This paper investigates the issue of privacy in a learning scenario where users share knowledge for a recommendation task. Our study contributes to the growing body of research on privacy-preserving machine learning and underscores the need for tailored privacy techniques that address specific attack patterns rather than relying on one-size-fits-all solutions. We use the latent bandit setting to evaluate the trade-off between privacy and recommender performance by employing various aggregation strategies, such as averaging, nearest neighbor, and clustering combined with noise injection. More specifically, we simulate a linkage attack scenario leveraging publicly available auxiliary information acquired by the adversary. Our results on three open real-world datasets reveal that adding noise using the Laplace mechanism to an individual user's data record is a poor choice. It provides the highest regret for any noise level, relative to de-anonymization probability and the ADS metric. Instead, one should combine noise with appropriate aggregation strategies. For example, using averages from clusters of different sizes provides flexibility not achievable by varying the amount of noise alone. Generally, no single aggregation strategy can consistently achieve the optimum regret for a given desired level of privacy.
Dynamic Causal Explanation Based Diffusion-Variational Graph Neural Network for Spatio-temporal Forecasting
May 16, 2023



Graph neural networks (GNNs), especially dynamic GNNs, have become a research hotspot in spatio-temporal forecasting problems. While many dynamic graph construction methods have been developed, relatively few of them explore the causal relationship between neighbour nodes. Thus, the resulting models lack strong explainability for the causal relationship between the neighbour nodes of the dynamically generated graphs, which can easily lead to a risk in subsequent decisions. Moreover, few of them consider the uncertainty and noise of dynamic graphs based on the time series datasets, which are ubiquitous in real-world graph structure networks. In this paper, we propose a novel Dynamic Diffusion-Variational Graph Neural Network (DVGNN) for spatio-temporal forecasting. For dynamic graph construction, an unsupervised generative model is devised. Two layers of graph convolutional network (GCN) are applied to calculate the posterior distribution of the latent node embeddings in the encoder stage. Then, a diffusion model is used to infer the dynamic link probability and reconstruct causal graphs in the decoder stage adaptively. The new loss function is derived theoretically, and the reparameterization trick is adopted in estimating the probability distribution of the dynamic graphs by Evidence Lower Bound during the backpropagation period. After obtaining the generated graphs, dynamic GCN and temporal attention are applied to predict future states. Experiments are conducted on four real-world datasets of different graph structures in different domains. The results demonstrate that the proposed DVGNN model outperforms state-of-the-art approaches and achieves outstanding Root Mean Squared Error result while exhibiting higher robustness. Also, by F1-score and probability distribution analysis, we demonstrate that DVGNN better reflects the causal relationship and uncertainty of dynamic graphs.
Surrogate-Assisted Genetic Algorithm for Wrapper Feature Selection
Nov 17, 2021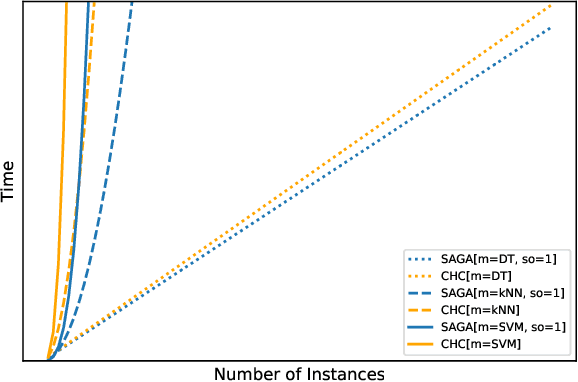
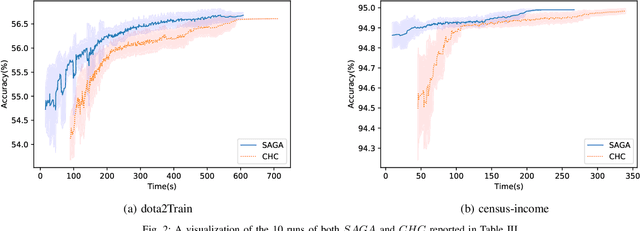
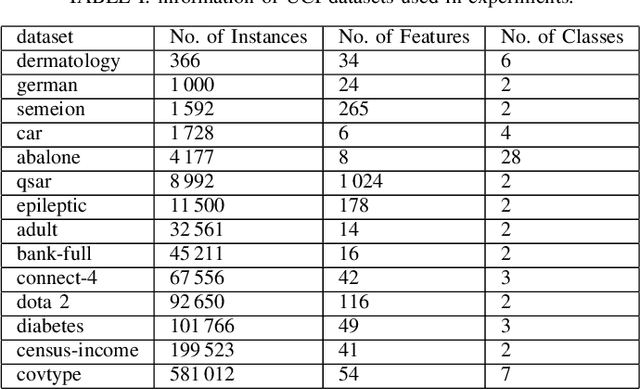
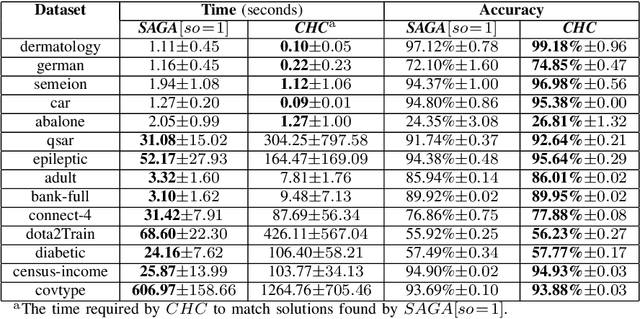
Feature selection is an intractable problem, therefore practical algorithms often trade off the solution accuracy against the computation time. In this paper, we propose a novel multi-stage feature selection framework utilizing multiple levels of approximations, or surrogates. Such a framework allows for using wrapper approaches in a much more computationally efficient way, significantly increasing the quality of feature selection solutions achievable, especially on large datasets. We design and evaluate a Surrogate-Assisted Genetic Algorithm (SAGA) which utilizes this concept to guide the evolutionary search during the early phase of exploration. SAGA only switches to evaluating the original function at the final exploitation phase. We prove that the run-time upper bound of SAGA surrogate-assisted stage is at worse equal to the wrapper GA, and it scales better for induction algorithms of high order of complexity in number of instances. We demonstrate, using 14 datasets from the UCI ML repository, that in practice SAGA significantly reduces the computation time compared to a baseline wrapper Genetic Algorithm (GA), while converging to solutions of significantly higher accuracy. Our experiments show that SAGA can arrive at near-optimal solutions three times faster than a wrapper GA, on average. We also showcase the importance of evolution control approach designed to prevent surrogates from misleading the evolutionary search towards false optima.
Transfer learning for Remaining Useful Life Prediction Based on Consensus Self-Organizing Models
Sep 30, 2019
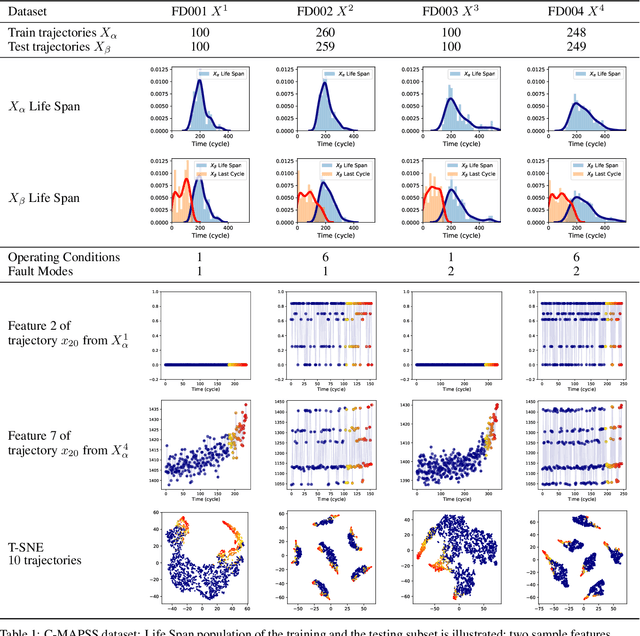
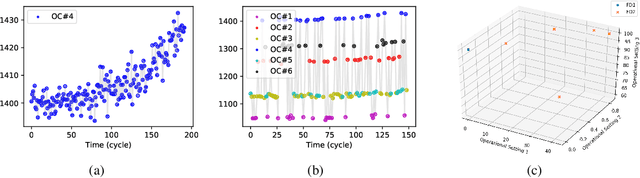

The traditional paradigm for developing machine prognostics usually relies on generalization from data acquired in experiments under controlled conditions prior to deployment of the equipment. Detecting or predicting failures and estimating machine health in this way assumes that future field data will have a very similar distribution to the experiment data. However, many complex machines operate under dynamic environmental conditions and are used in many different ways. This makes collecting comprehensive data very challenging, and the assumption that pre-deployment data and post-deployment data follow very similar distributions is unlikely to hold. Transfer Learning (TL) refers to methods for transferring knowledge learned in one setting (the source domain) to another setting (the target domain). In this work, we present a TL method for predicting Remaining Useful Life (RUL) of equipment, under the assumption that labels are available only for the source domain and not the target domain. This setting corresponds to generalizing from a limited number of run-to-failure experiments performed prior to deployment into making prognostics with data coming from deployed equipment that is being used under multiple new operating conditions and experiencing previously unseen faults. We employ a deviation detection method, Consensus Self-Organizing Models (COSMO), to create transferable features for building the RUL regression model. These features capture how different target equipment is in comparison to its peers. The efficiency of the proposed TL method is demonstrated using the NASA Turbofan Engine Degradation Simulation Data Set. Models using the COSMO transferable features show better performance than other methods on predicting RUL when the target domain is more complex than the source domain.