 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Function of Neurons in KANs
Jul 30, 2024The neurons of Kolmogorov-Arnold Networks (KANs) perform a simple summation motivated by the Kolmogorov-Arnold representation theorem, which asserts that sum is the only fundamental multivariate function. In this work, we investigate the potential for identifying an alternative multivariate function for KAN neurons that may offer increased practical utility. Our empirical research involves testing various multivariate functions in KAN neurons across a range of benchmark Machine Learning tasks. Our findings indicate that substituting the sum with the average function in KAN neurons results in significant performance enhancements compared to traditional KANs. Our study demonstrates that this minor modification contributes to the stability of training by confining the input to the spline within the effective range of the activation function. Our implementation and experiments are available at: \url{https://github.com/Ghaith81/dropkan}
DropKAN: Regularizing KANs by masking post-activations
Jul 17, 2024



We propose DropKAN (Drop Kolmogorov-Arnold Networks) a regularization method that prevents co-adaptation of activation function weights in Kolmogorov-Arnold Networks (KANs). DropKAN operates by randomly masking some of the post-activations within the KANs computation graph, while scaling-up the retained post-activations. We show that this simple procedure that require minimal coding effort has a regularizing effect and consistently lead to better generalization of KANs. We analyze the adaptation of the standard Dropout with KANs and demonstrate that Dropout applied to KANs' neurons can lead to unpredictable performance in the feedforward pass. We carry an empirical study with real world Machine Learning datasets to validate our findings. Our results suggest that DropKAN is consistently a better alternative to Dropout, and improves the generalization performance of KANs.
Rolling the dice for better deep learning performance: A study of randomness techniques in deep neural networks
Apr 05, 2024



This paper investigates how various randomization techniques impact Deep Neural Networks (DNNs). Randomization, like weight noise and dropout, aids in reducing overfitting and enhancing generalization, but their interactions are poorly understood. The study categorizes randomness techniques into four types and proposes new methods: adding noise to the loss function and random masking of gradient updates. Using Particle Swarm Optimizer (PSO) for hyperparameter optimization, it explores optimal configurations across MNIST, FASHION-MNIST, CIFAR10, and CIFAR100 datasets. Over 30,000 configurations are evaluated, revealing data augmentation and weight initialization randomness as main performance contributors. Correlation analysis shows different optimizers prefer distinct randomization types. The complete implementation and dataset are available on GitHub.
Fast Genetic Algorithm for feature selection -- A qualitative approximation approach
Apr 05, 2024Evolutionary Algorithms (EAs) are often challenging to apply in real-world settings since evolutionary computations involve a large number of evaluations of a typically expensive fitness function. For example, an evaluation could involve training a new machine learning model. An approximation (also known as meta-model or a surrogate) of the true function can be used in such applications to alleviate the computation cost. In this paper, we propose a two-stage surrogate-assisted evolutionary approach to address the computational issues arising from using Genetic Algorithm (GA) for feature selection in a wrapper setting for large datasets. We define 'Approximation Usefulness' to capture the necessary conditions to ensure correctness of the EA computations when an approximation is used. Based on this definition, we propose a procedure to construct a lightweight qualitative meta-model by the active selection of data instances. We then use a meta-model to carry out the feature selection task. We apply this procedure to the GA-based algorithm CHC (Cross generational elitist selection, Heterogeneous recombination and Cataclysmic mutation) to create a Qualitative approXimations variant, CHCQX. We show that CHCQX converges faster to feature subset solutions of significantly higher accuracy (as compared to CHC), particularly for large datasets with over 100K instances. We also demonstrate the applicability of the thinking behind our approach more broadly to Swarm Intelligence (SI), another branch of the Evolutionary Computation (EC) paradigm with results of PSOQX, a qualitative approximation adaptation of the Particle Swarm Optimization (PSO) method. A GitHub repository with the complete implementation is available.
Surrogate-Assisted Genetic Algorithm for Wrapper Feature Selection
Nov 17, 2021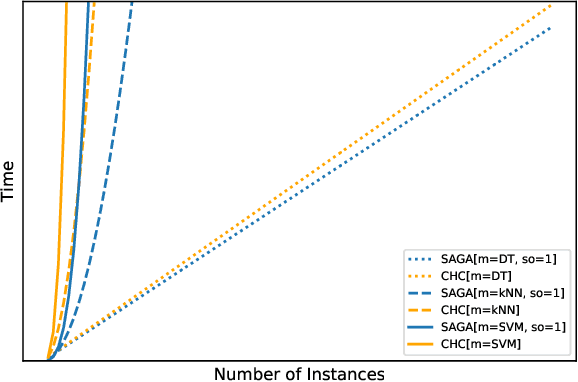
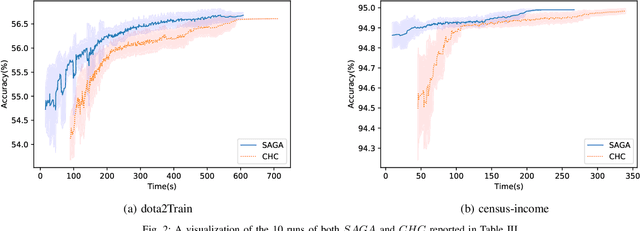
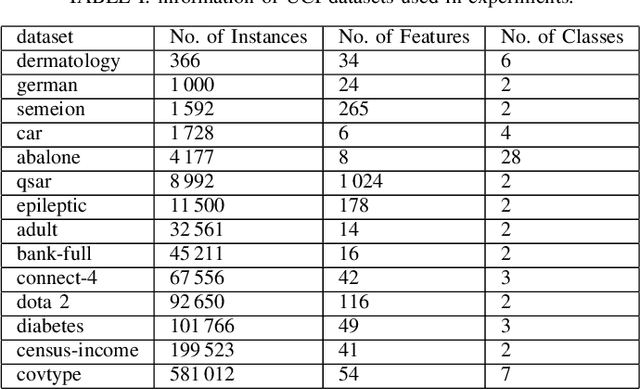
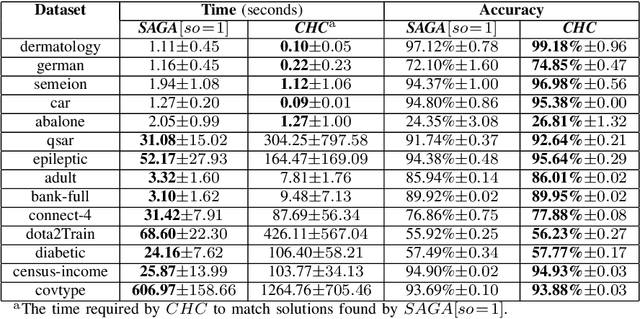
Feature selection is an intractable problem, therefore practical algorithms often trade off the solution accuracy against the computation time. In this paper, we propose a novel multi-stage feature selection framework utilizing multiple levels of approximations, or surrogates. Such a framework allows for using wrapper approaches in a much more computationally efficient way, significantly increasing the quality of feature selection solutions achievable, especially on large datasets. We design and evaluate a Surrogate-Assisted Genetic Algorithm (SAGA) which utilizes this concept to guide the evolutionary search during the early phase of exploration. SAGA only switches to evaluating the original function at the final exploitation phase. We prove that the run-time upper bound of SAGA surrogate-assisted stage is at worse equal to the wrapper GA, and it scales better for induction algorithms of high order of complexity in number of instances. We demonstrate, using 14 datasets from the UCI ML repository, that in practice SAGA significantly reduces the computation time compared to a baseline wrapper Genetic Algorithm (GA), while converging to solutions of significantly higher accuracy. Our experiments show that SAGA can arrive at near-optimal solutions three times faster than a wrapper GA, on average. We also showcase the importance of evolution control approach designed to prevent surrogates from misleading the evolutionary search towards false optima.