 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRolling the dice for better deep learning performance: A study of randomness techniques in deep neural networks
Apr 05, 2024This paper investigates how various randomization techniques impact Deep Neural Networks (DNNs). Randomization, like weight noise and dropout, aids in reducing overfitting and enhancing generalization, but their interactions are poorly understood. The study categorizes randomness techniques into four types and proposes new methods: adding noise to the loss function and random masking of gradient updates. Using Particle Swarm Optimizer (PSO) for hyperparameter optimization, it explores optimal configurations across MNIST, FASHION-MNIST, CIFAR10, and CIFAR100 datasets. Over 30,000 configurations are evaluated, revealing data augmentation and weight initialization randomness as main performance contributors. Correlation analysis shows different optimizers prefer distinct randomization types. The complete implementation and dataset are available on GitHub.
Graph Reinforcement Learning for Operator Selection in the ALNS Metaheuristic
Feb 28, 2023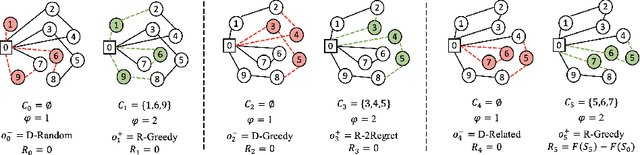
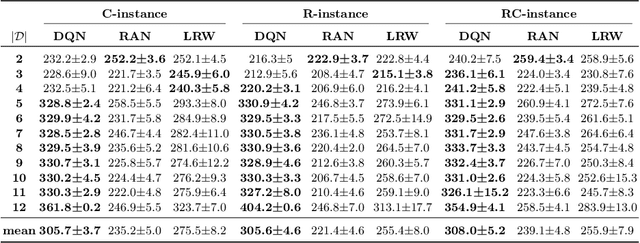
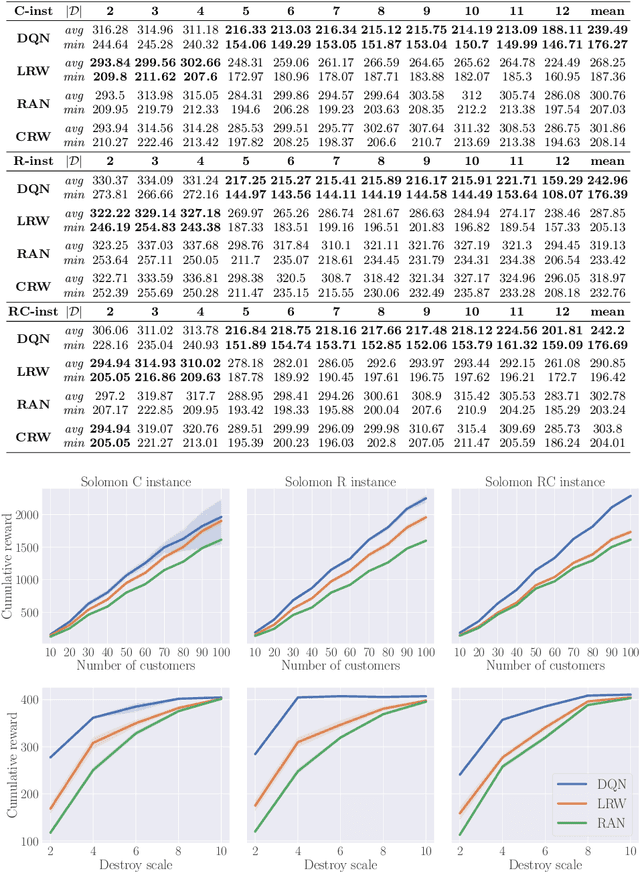
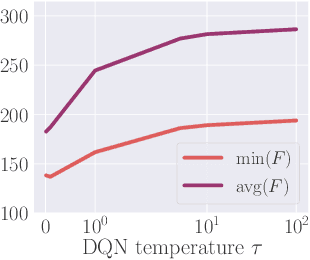
ALNS is a popular metaheuristic with renowned efficiency in solving combinatorial optimisation problems. However, despite 16 years of intensive research into ALNS, whether the embedded adaptive layer can efficiently select operators to improve the incumbent remains an open question. In this work, we formulate the choice of operators as a Markov Decision Process, and propose a practical approach based on Deep Reinforcement Learning and Graph Neural Networks. The results show that our proposed method achieves better performance than the classic ALNS adaptive layer due to the choice of operator being conditioned on the current solution. We also discuss important considerations such as the size of the operator portfolio and the impact of the choice of operator scales. Notably, our approach can also save significant time and labour costs for handcrafting problem-specific operator portfolios.
Towards a fairer reimbursement system for burn patients using cost-sensitive classification
Jul 01, 2021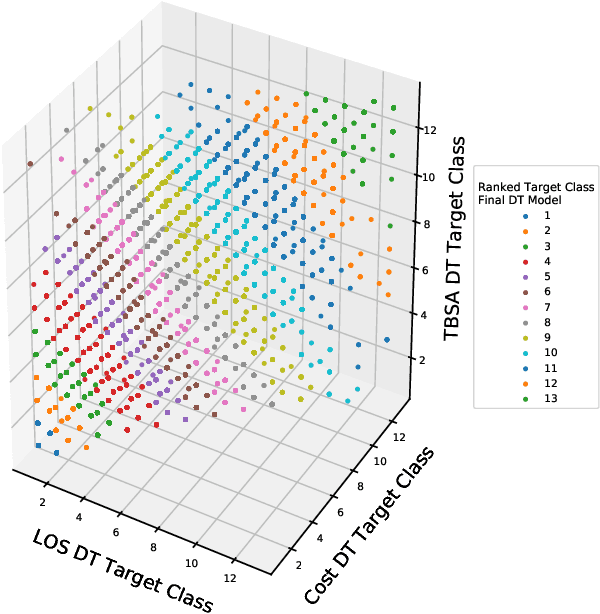
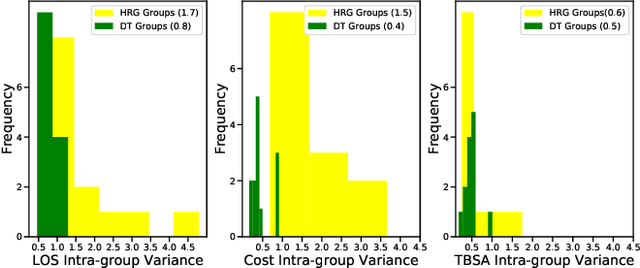
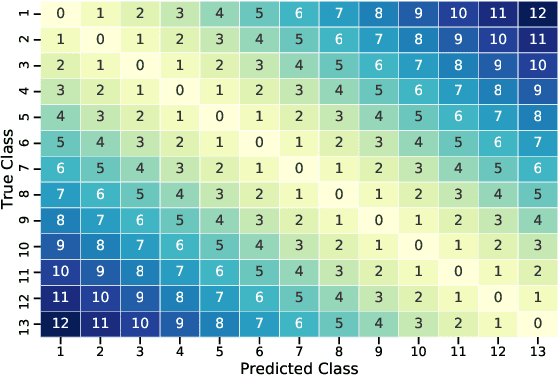
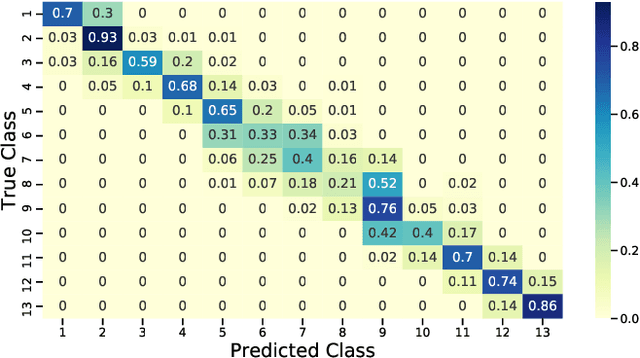
The adoption of the Prospective Payment System (PPS) in the UK National Health Service (NHS) has led to the creation of patient groups called Health Resource Groups (HRG). HRGs aim to identify groups of clinically similar patients that share similar resource usage for reimbursement purposes. These groups are predominantly identified based on expert advice, with homogeneity checked using the length of stay (LOS). However, for complex patients such as those encountered in burn care, LOS is not a perfect proxy of resource usage, leading to incomplete homogeneity checks. To improve homogeneity in resource usage and severity, we propose a data-driven model and the inclusion of patient-level costing. We investigate whether a data-driven approach that considers additional measures of resource usage can lead to a more comprehensive model. In particular, a cost-sensitive decision tree model is adopted to identify features of importance and rules that allow for a focused segmentation on resource usage (LOS and patient-level cost) and clinical similarity (severity of burn). The proposed approach identified groups with increased homogeneity compared to the current HRG groups, allowing for a more equitable reimbursement of hospital care costs if adopted.
HAWKS: Evolving Challenging Benchmark Sets for Cluster Analysis
Feb 13, 2021
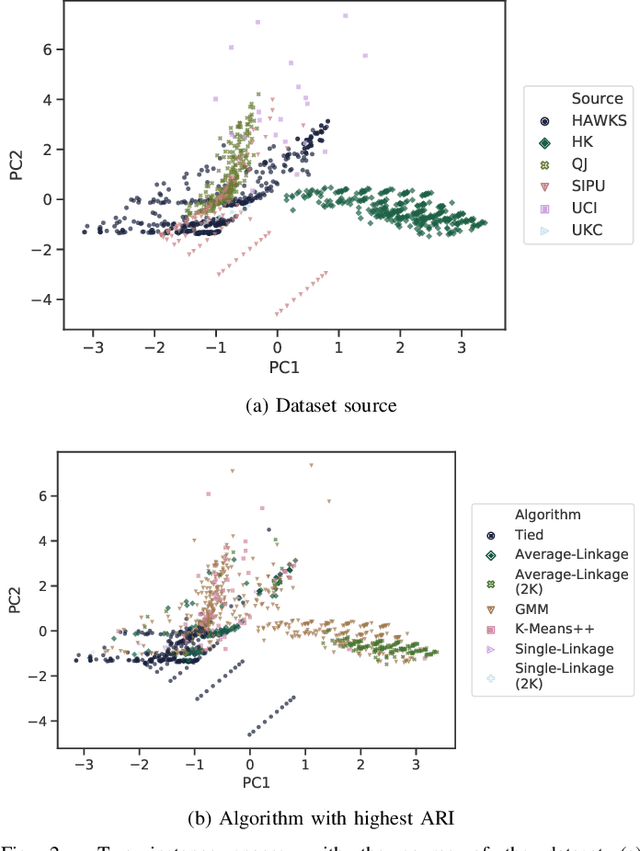
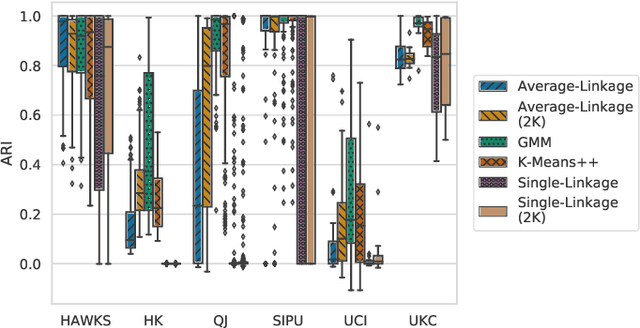

Comprehensive benchmarking of clustering algorithms is rendered difficult by two key factors: (i)~the elusiveness of a unique mathematical definition of this unsupervised learning approach and (ii)~dependencies between the generating models or clustering criteria adopted by some clustering algorithms and indices for internal cluster validation. Consequently, there is no consensus regarding the best practice for rigorous benchmarking, and whether this is possible at all outside the context of a given application. Here, we argue that synthetic datasets must continue to play an important role in the evaluation of clustering algorithms, but that this necessitates constructing benchmarks that appropriately cover the diverse set of properties that impact clustering algorithm performance. Through our framework, HAWKS, we demonstrate the important role evolutionary algorithms play to support flexible generation of such benchmarks, allowing simple modification and extension. We illustrate two possible uses of our framework: (i)~the evolution of benchmark data consistent with a set of hand-derived properties and (ii)~the generation of datasets that tease out performance differences between a given pair of algorithms. Our work has implications for the design of clustering benchmarks that sufficiently challenge a broad range of algorithms, and for furthering insight into the strengths and weaknesses of specific approaches.