 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning of personalized priors from past MRI scans enables fast, quality-enhanced point-of-care MRI with low-cost systems
May 05, 2025Magnetic resonance imaging (MRI) offers superb-quality images, but its accessibility is limited by high costs, posing challenges for patients requiring longitudinal care. Low-field MRI provides affordable imaging with low-cost devices but is hindered by long scans and degraded image quality, including low signal-to-noise ratio (SNR) and tissue contrast. We propose a novel healthcare paradigm: using deep learning to extract personalized features from past standard high-field MRI scans and harnessing them to enable accelerated, enhanced-quality follow-up scans with low-cost systems. To overcome the SNR and contrast differences, we introduce ViT-Fuser, a feature-fusion vision transformer that learns features from past scans, e.g. those stored in standard DICOM CDs. We show that \textit{a single prior scan is sufficient}, and this scan can come from various MRI vendors, field strengths, and pulse sequences. Experiments with four datasets, including glioblastoma data, low-field ($50mT$), and ultra-low-field ($6.5mT$) data, demonstrate that ViT-Fuser outperforms state-of-the-art methods, providing enhanced-quality images from accelerated low-field scans, with robustness to out-of-distribution data. Our freely available framework thus enables rapid, diagnostic-quality, low-cost imaging for wide healthcare applications.
A Unified Theory of Diversity in Ensemble Learning
Jan 10, 2023



We present a theory of ensemble diversity, explaining the nature and effect of diversity for a wide range of supervised learning scenarios. This challenge, of understanding ensemble diversity, has been referred to as the holy grail of ensemble learning, an open question for over 30 years. Our framework reveals that diversity is in fact a hidden dimension in the bias-variance decomposition of an ensemble. In particular, we prove a family of exact bias-variance-diversity decompositions, for both classification and regression losses, e.g., squared, and cross-entropy. The framework provides a methodology to automatically identify the combiner rule enabling such a decomposition, specific to the loss. The formulation of diversity is therefore dependent on just two design choices: the loss, and the combiner. For certain choices (e.g., 0-1 loss with majority voting) the effect of diversity is necessarily dependent on the target label. Experiments illustrate how we can use our framework to understand the diversity-encouraging mechanisms of popular ensemble methods: Bagging, Boosting, and Random Forests.
HAWKS: Evolving Challenging Benchmark Sets for Cluster Analysis
Feb 13, 2021
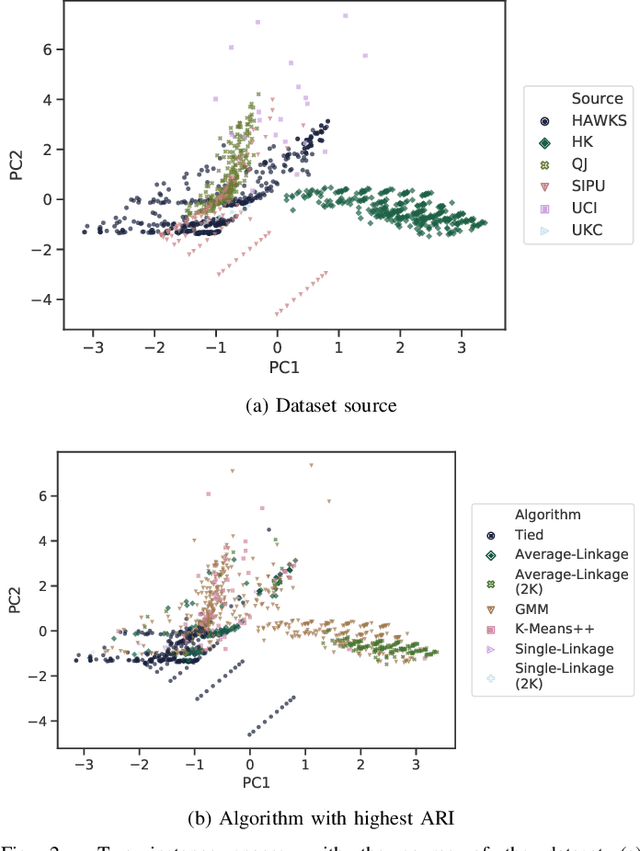
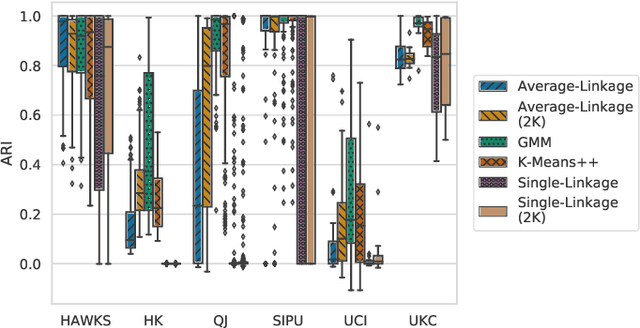

Comprehensive benchmarking of clustering algorithms is rendered difficult by two key factors: (i)~the elusiveness of a unique mathematical definition of this unsupervised learning approach and (ii)~dependencies between the generating models or clustering criteria adopted by some clustering algorithms and indices for internal cluster validation. Consequently, there is no consensus regarding the best practice for rigorous benchmarking, and whether this is possible at all outside the context of a given application. Here, we argue that synthetic datasets must continue to play an important role in the evaluation of clustering algorithms, but that this necessitates constructing benchmarks that appropriately cover the diverse set of properties that impact clustering algorithm performance. Through our framework, HAWKS, we demonstrate the important role evolutionary algorithms play to support flexible generation of such benchmarks, allowing simple modification and extension. We illustrate two possible uses of our framework: (i)~the evolution of benchmark data consistent with a set of hand-derived properties and (ii)~the generation of datasets that tease out performance differences between a given pair of algorithms. Our work has implications for the design of clustering benchmarks that sufficiently challenge a broad range of algorithms, and for furthering insight into the strengths and weaknesses of specific approaches.
Hierarchical stochastic neighbor embedding as a tool for visualizing the encoding capability of magnetic resonance fingerprinting dictionaries
Oct 07, 2019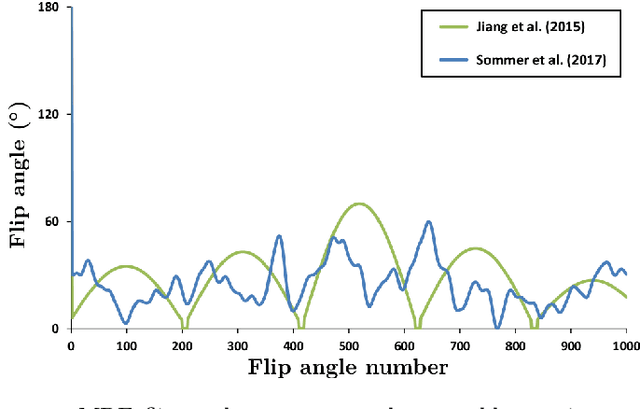
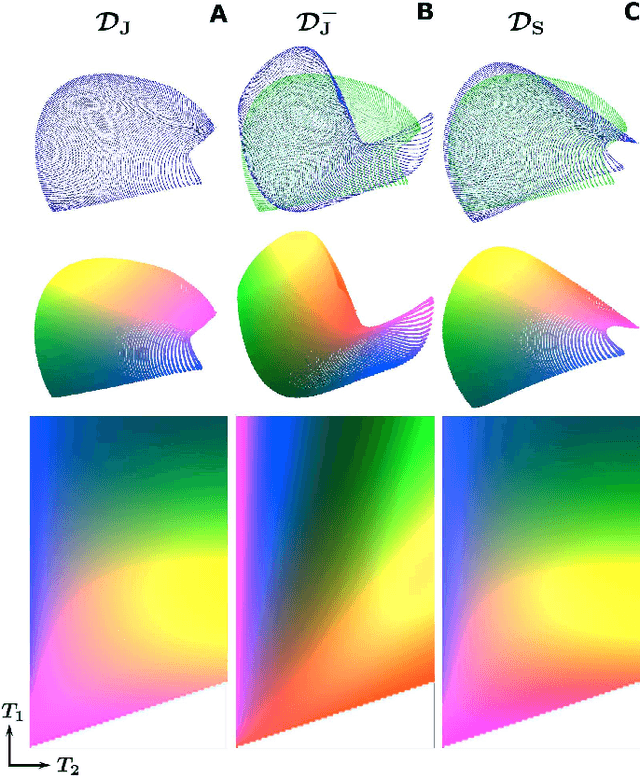
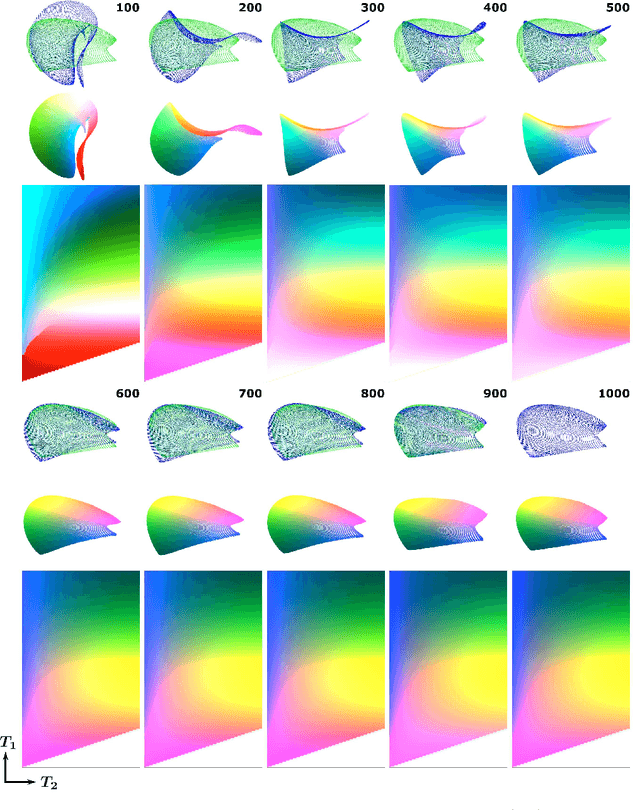
In Magnetic Resonance Fingerprinting (MRF) the quality of the estimated parameter maps depends on the encoding capability of the variable flip angle train. In this work we show how the dimensionality reduction technique Hierarchical Stochastic Neighbor Embedding (HSNE) can be used to obtain insight into the encoding capability of different MRF sequences. Embedding high-dimensional MRF dictionaries into a lower-dimensional space and visualizing them with colors, being a surrogate for location in low-dimensional space, provides a comprehensive overview of particular dictionaries and, in addition, enables comparison of different sequences. Dictionaries for various sequences and sequence lengths were compared to each other, and the effect of transmit field variations on the encoding capability was assessed. Clear differences in encoding capability were observed between different sequences, and HSNE results accurately reflect those obtained from an MRF matching simulation.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018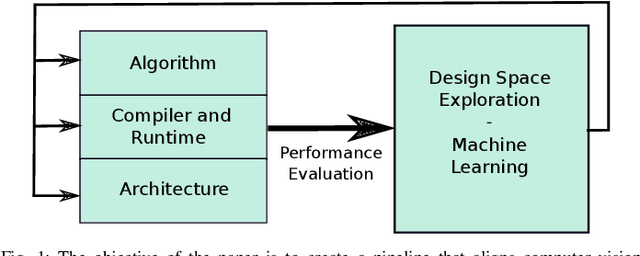

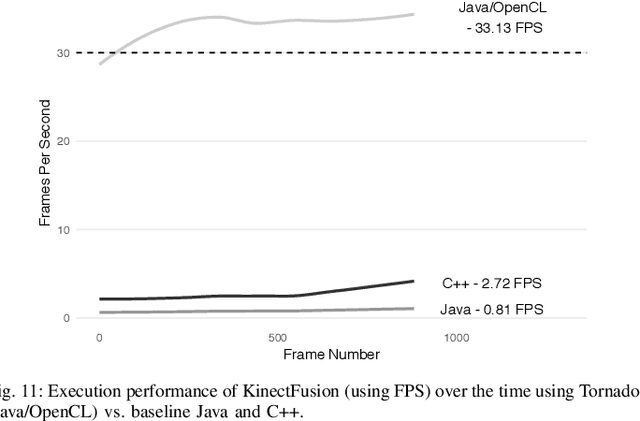
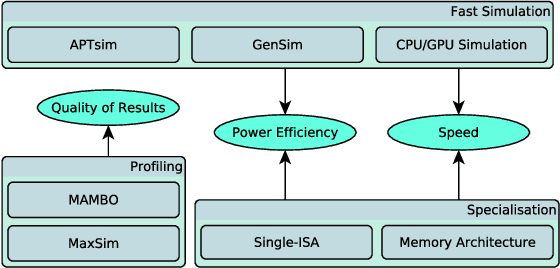
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.
Accelerating CS in Parallel Imaging Reconstructions Using an Efficient and Effective Circulant Preconditioner
Oct 04, 2017
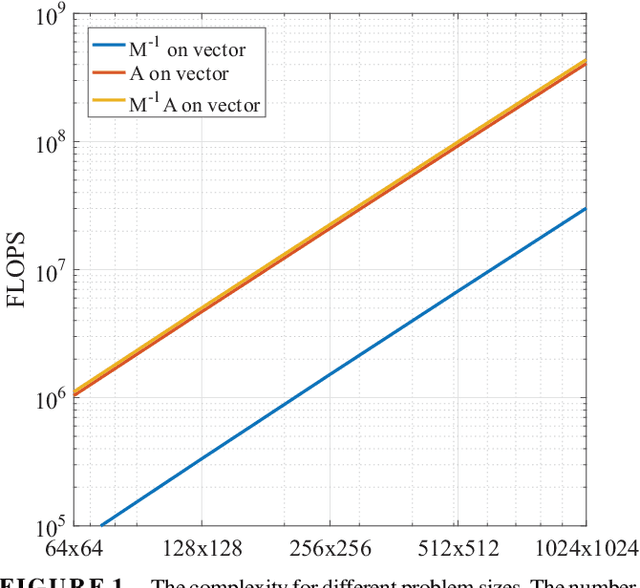
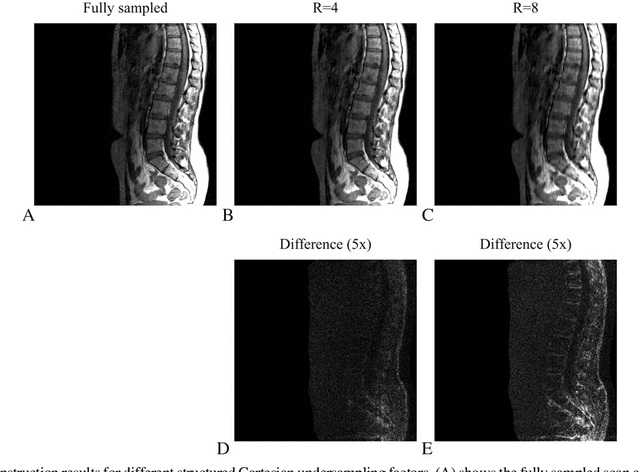

Purpose: Design of a preconditioner for fast and efficient parallel imaging and compressed sensing reconstructions. Theory: Parallel imaging and compressed sensing reconstructions become time consuming when the problem size or the number of coils is large, due to the large linear system of equations that has to be solved in l_1 and l_2-norm based reconstruction algorithms. Such linear systems can be solved efficiently using effective preconditioning techniques. Methods: In this paper we construct such a preconditioner by approximating the system matrix of the linear system, which comprises the data fidelity and includes total variation and wavelet regularization, by a matrix with the assumption that is a block circulant matrix with circulant blocks. Due to its circulant structure, the preconditioner can be constructed quickly and its inverse can be evaluated fast using only two fast Fourier transformations. We test the performance of the preconditioner for the conjugate gradient method as the linear solver, integrated into the Split Bregman algorithm. Results: The designed circulant preconditioner reduces the number of iterations required in the conjugate gradient method by almost a factor of~5. The speed up results in a total acceleration factor of approximately 2.5 for the entire reconstruction algorithm when implemented in MATLAB, while the initialization time of the preconditioner is negligible. Conclusion: The proposed preconditioner reduces the reconstruction time for parallel imaging and compressed sensing in a Split Bregman implementation and can easily handle large systems since it is Fourier-based, allowing for efficient computations. Key words: preconditioning; compressed sensing; Split Bregman; parallel imaging