 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAMBench2: Multi-Objective Head-to-Head Benchmarking for Visual SLAM
Aug 21, 2018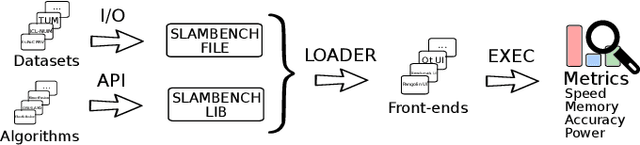


SLAM is becoming a key component of robotics and augmented reality (AR) systems. While a large number of SLAM algorithms have been presented, there has been little effort to unify the interface of such algorithms, or to perform a holistic comparison of their capabilities. This is a problem since different SLAM applications can have different functional and non-functional requirements. For example, a mobile phonebased AR application has a tight energy budget, while a UAV navigation system usually requires high accuracy. SLAMBench2 is a benchmarking framework to evaluate existing and future SLAM systems, both open and close source, over an extensible list of datasets, while using a comparable and clearly specified list of performance metrics. A wide variety of existing SLAM algorithms and datasets is supported, e.g. ElasticFusion, InfiniTAM, ORB-SLAM2, OKVIS, and integrating new ones is straightforward and clearly specified by the framework. SLAMBench2 is a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs across SLAM systems.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018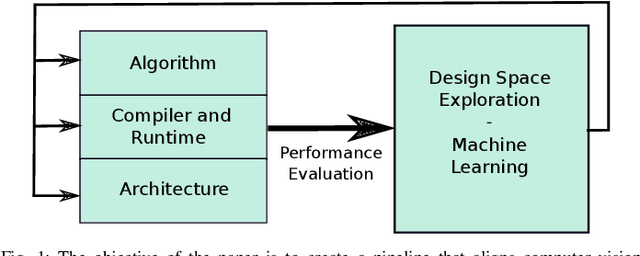

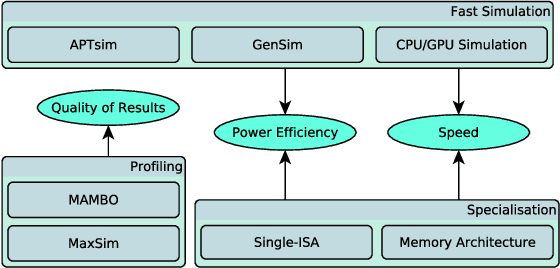
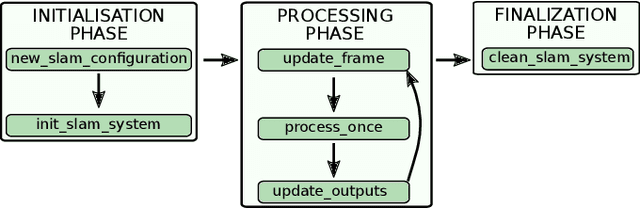
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.
Algorithmic Performance-Accuracy Trade-off in 3D Vision Applications Using HyperMapper
Mar 21, 2017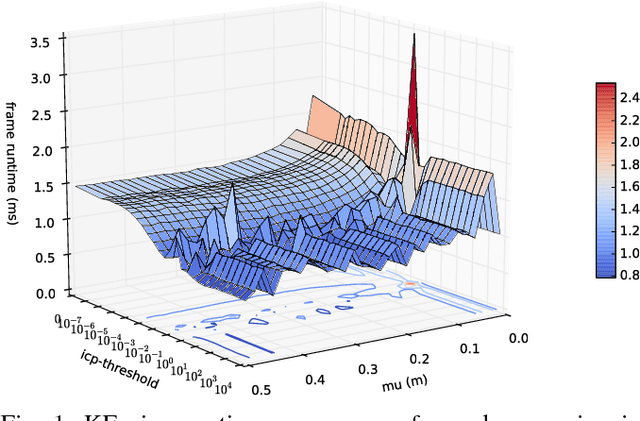
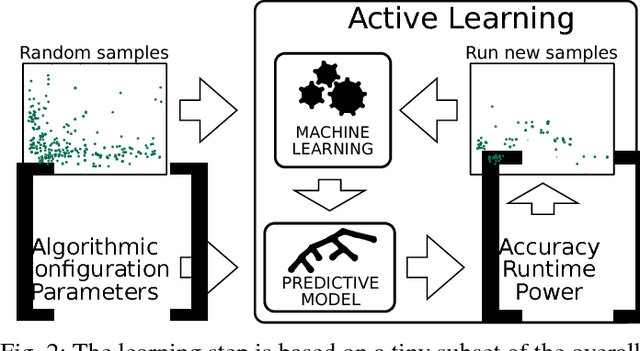
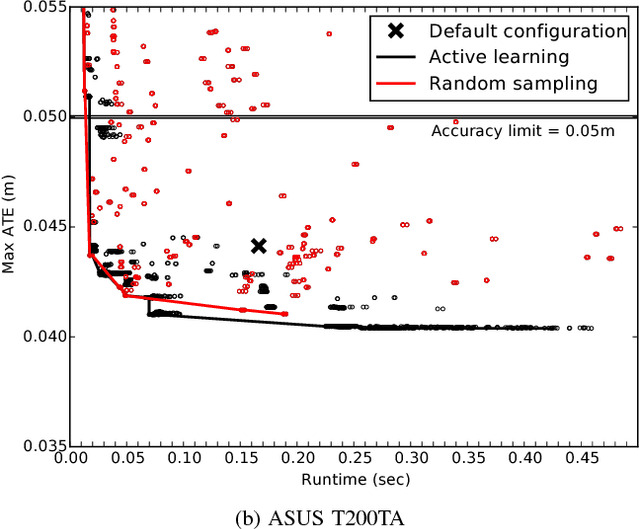
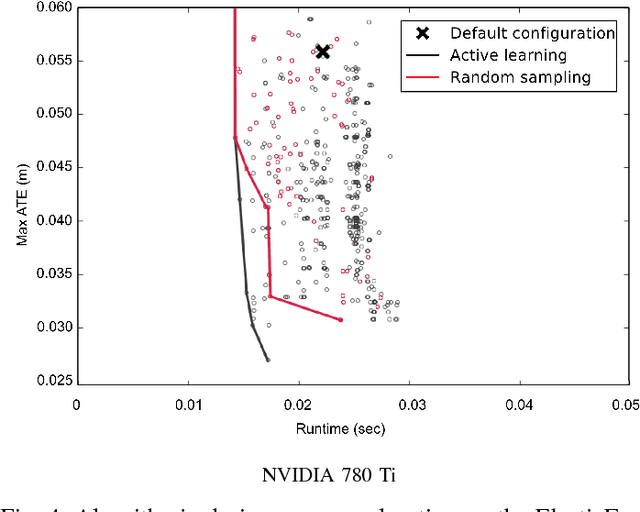
In this paper we investigate an emerging application, 3D scene understanding, likely to be significant in the mobile space in the near future. The goal of this exploration is to reduce execution time while meeting our quality of result objectives. In previous work we showed for the first time that it is possible to map this application to power constrained embedded systems, highlighting that decision choices made at the algorithmic design-level have the most impact. As the algorithmic design space is too large to be exhaustively evaluated, we use a previously introduced multi-objective Random Forest Active Learning prediction framework dubbed HyperMapper, to find good algorithmic designs. We show that HyperMapper generalizes on a recent cutting edge 3D scene understanding algorithm and on a modern GPU-based computer architecture. HyperMapper is able to beat an expert human hand-tuning the algorithmic parameters of the class of Computer Vision applications taken under consideration in this paper automatically. In addition, we use crowd-sourcing using a 3D scene understanding Android app to show that the Pareto front obtained on an embedded system can be used to accelerate the same application on all the 83 smart-phones and tablets crowd-sourced with speedups ranging from 2 to over 12.
* 10 pages, Keywords: design space exploration, machine learning, computer vision, SLAM, embedded systems, GPU, crowd-sourcing
Comparative Design Space Exploration of Dense and Semi-Dense SLAM
Mar 03, 2016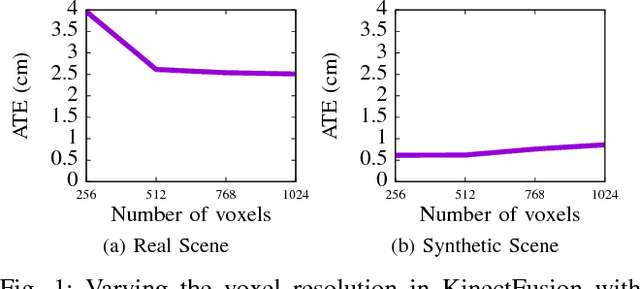
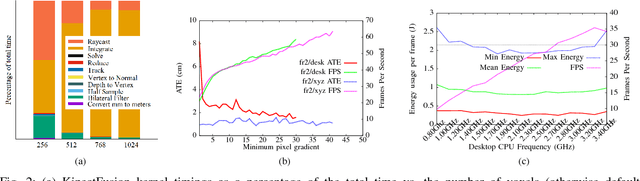
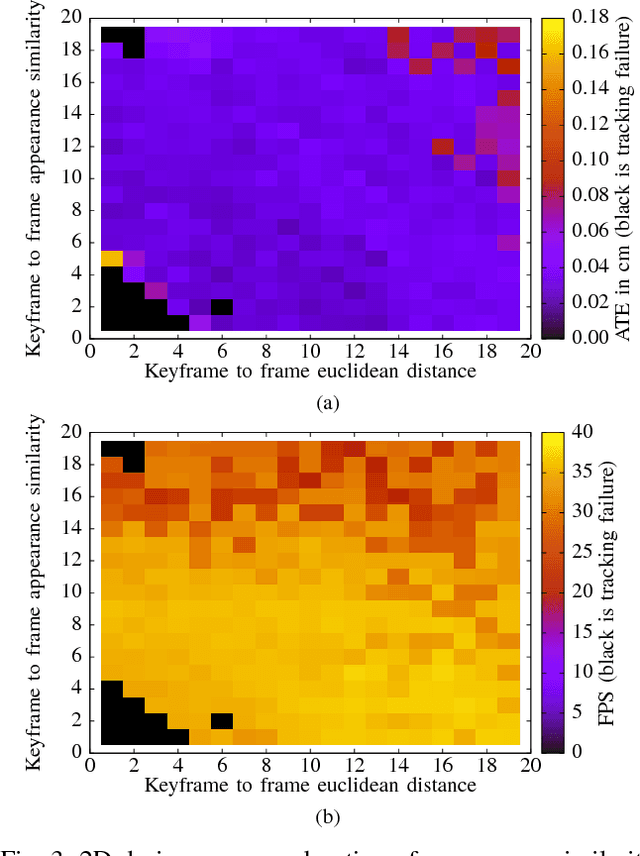
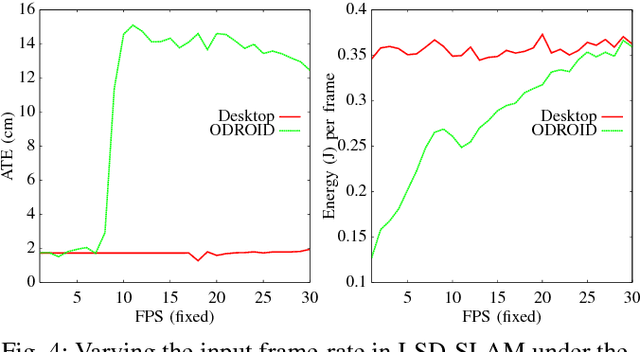
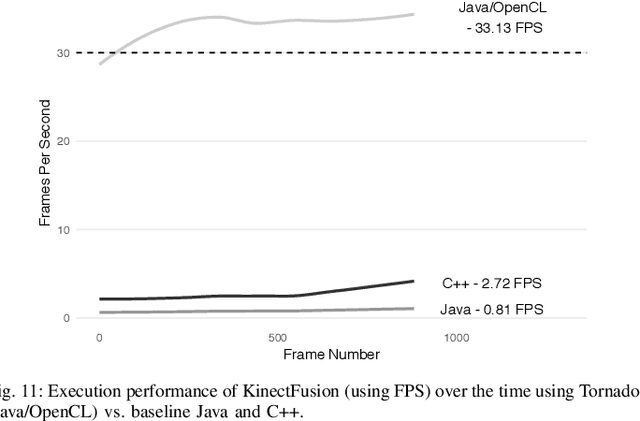
SLAM has matured significantly over the past few years, and is beginning to appear in serious commercial products. While new SLAM systems are being proposed at every conference, evaluation is often restricted to qualitative visualizations or accuracy estimation against a ground truth. This is due to the lack of benchmarking methodologies which can holistically and quantitatively evaluate these systems. Further investigation at the level of individual kernels and parameter spaces of SLAM pipelines is non-existent, which is absolutely essential for systems research and integration. We extend the recently introduced SLAMBench framework to allow comparing two state-of-the-art SLAM pipelines, namely KinectFusion and LSD-SLAM, along the metrics of accuracy, energy consumption, and processing frame rate on two different hardware platforms, namely a desktop and an embedded device. We also analyze the pipelines at the level of individual kernels and explore their algorithmic and hardware design spaces for the first time, yielding valuable insights.
Introducing SLAMBench, a performance and accuracy benchmarking methodology for SLAM
Feb 26, 2015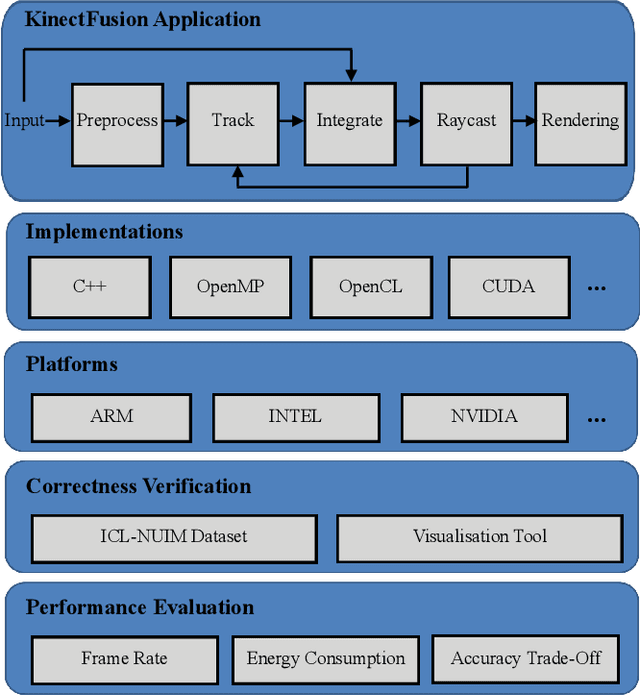

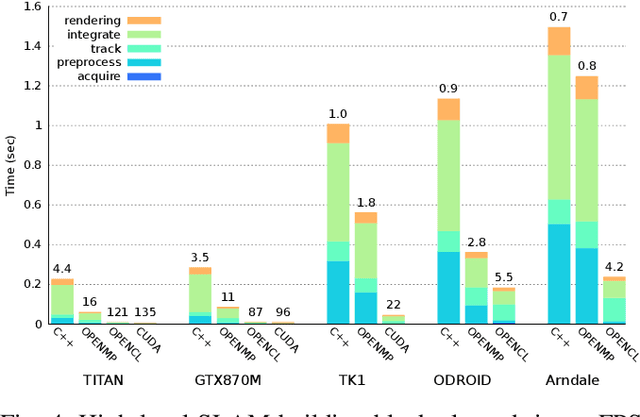
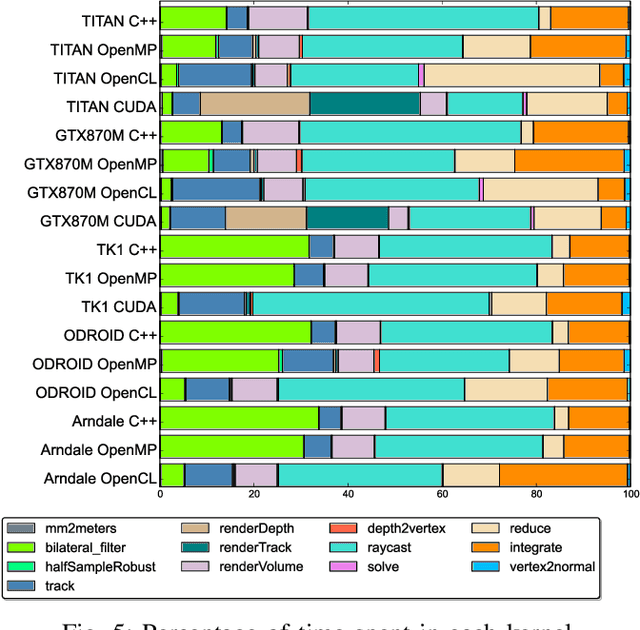
Real-time dense computer vision and SLAM offer great potential for a new level of scene modelling, tracking and real environmental interaction for many types of robot, but their high computational requirements mean that use on mass market embedded platforms is challenging. Meanwhile, trends in low-cost, low-power processing are towards massive parallelism and heterogeneity, making it difficult for robotics and vision researchers to implement their algorithms in a performance-portable way. In this paper we introduce SLAMBench, a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs in performance, accuracy and energy consumption of a dense RGB-D SLAM system. SLAMBench provides a KinectFusion implementation in C++, OpenMP, OpenCL and CUDA, and harnesses the ICL-NUIM dataset of synthetic RGB-D sequences with trajectory and scene ground truth for reliable accuracy comparison of different implementation and algorithms. We present an analysis and breakdown of the constituent algorithmic elements of KinectFusion, and experimentally investigate their execution time on a variety of multicore and GPUaccelerated platforms. For a popular embedded platform, we also present an analysis of energy efficiency for different configuration alternatives.
* 8 pages, ICRA 2015 conference paper