 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous computing platform for real-time robotics
Jan 13, 2026After Industry 4.0 has embraced tight integration between machinery (OT), software (IT), and the Internet, creating a web of sensors, data, and algorithms in service of efficient and reliable production, a new concept of Society 5.0 is emerging, in which infrastructure of a city will be instrumented to increase reliability, efficiency, and safety. Robotics will play a pivotal role in enabling this vision that is pioneered by the NEOM initiative - a smart city, co-inhabited by humans and robots. In this paper we explore the computing platform that will be required to enable this vision. We show how we can combine neuromorphic computing hardware, exemplified by the Loihi2 processor used in conjunction with event-based cameras, for sensing and real-time perception and interaction with a local AI compute cluster (GPUs) for high-level language processing, cognition, and task planning. We demonstrate the use of this hybrid computing architecture in an interactive task, in which a humanoid robot plays a musical instrument with a human. Central to our design is the efficient and seamless integration of disparate components, ensuring that the synergy between software and hardware maximizes overall performance and responsiveness. Our proposed system architecture underscores the potential of heterogeneous computing architectures in advancing robotic autonomy and interactive intelligence, pointing toward a future where such integrated systems become the norm in complex, real-time applications.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Unleashing the Potential of Spiking Neural Networks by Dynamic Confidence
Mar 26, 2023This paper presents a new methodology to alleviate the fundamental trade-off between accuracy and latency in spiking neural networks (SNNs). The approach involves decoding confidence information over time from the SNN outputs and using it to develop a decision-making agent that can dynamically determine when to terminate each inference. The proposed method, Dynamic Confidence, provides several significant benefits to SNNs. 1. It can effectively optimize latency dynamically at runtime, setting it apart from many existing low-latency SNN algorithms. Our experiments on CIFAR-10 and ImageNet datasets have demonstrated an average 40% speedup across eight different settings after applying Dynamic Confidence. 2. The decision-making agent in Dynamic Confidence is straightforward to construct and highly robust in parameter space, making it extremely easy to implement. 3. The proposed method enables visualizing the potential of any given SNN, which sets a target for current SNNs to approach. For instance, if an SNN can terminate at the most appropriate time point for each input sample, a ResNet-50 SNN can achieve an accuracy as high as 82.47% on ImageNet within just 4.71 time steps on average. Unlocking the potential of SNNs needs a highly-reliable decision-making agent to be constructed and fed with a high-quality estimation of ground truth. In this regard, Dynamic Confidence represents a meaningful step toward realizing the potential of SNNs.
An FPGA Implementation of Convolutional Spiking Neural Networks for Radioisotope Identification
Feb 24, 2021
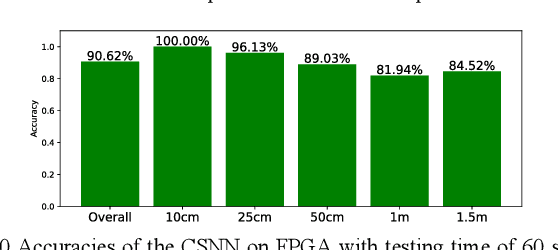
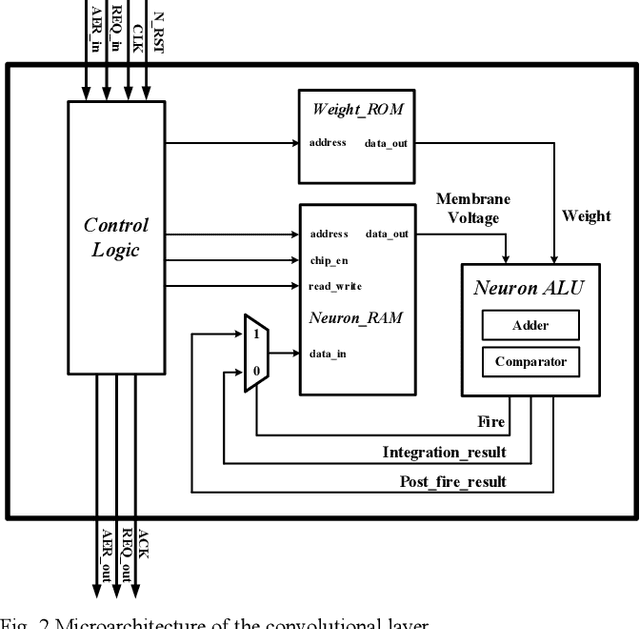
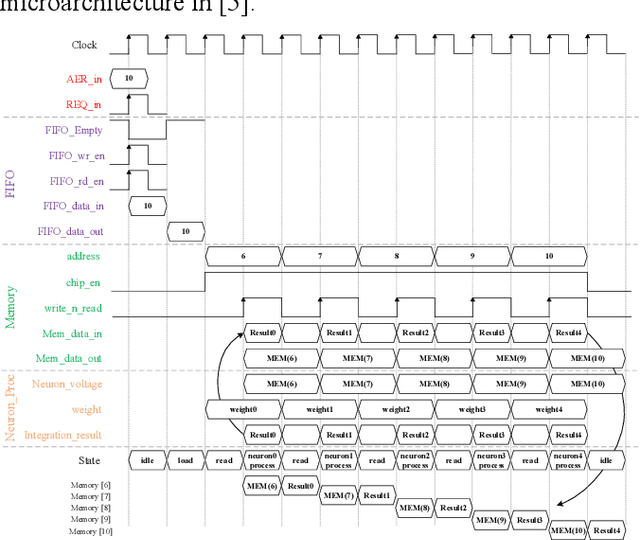
This paper details the FPGA implementation methodology for Convolutional Spiking Neural Networks (CSNN) and applies this methodology to low-power radioisotope identification using high-resolution data. Power consumption of 75 mW has been achieved on an FPGA implementation of a CSNN, with an inference accuracy of 90.62% on a synthetic dataset. The chip validation method is presented. Prototyping was accelerated by evaluating SNN parameters using SpiNNaker neuromorphic platform.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020
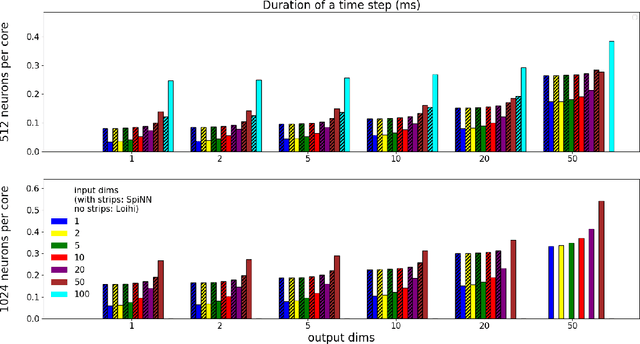
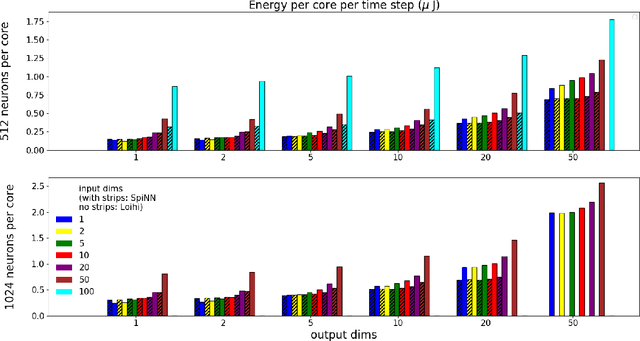
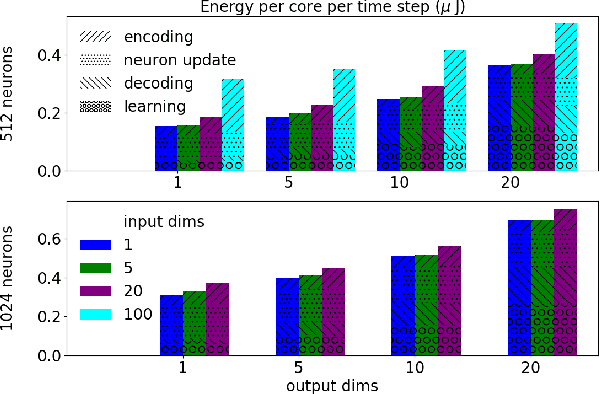
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
ATIS + SpiNNaker: a Fully Event-based Visual Tracking Demonstration
Dec 03, 2019
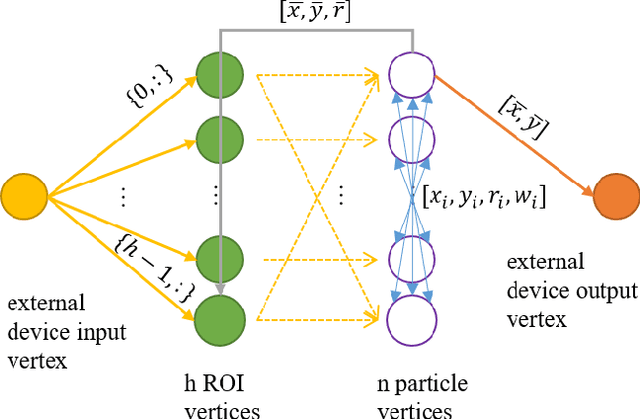
The Asynchronous Time-based Image Sensor (ATIS) and the Spiking Neural Network Architecture (SpiNNaker) are both neuromorphic technologies that "unconventionally" use binary spikes to represent information. The ATIS produces spikes to represent the change in light falling on the sensor, and the SpiNNaker is a massively parallel computing platform that asynchronously sends spikes between cores for processing. In this demonstration we show these two hardware used together to perform a visual tracking task. We aim to show the hardware and software architecture that integrates the ATIS and SpiNNaker together in a robot middle-ware that makes processing agnostic to the platform (CPU or SpiNNaker). We also aim to describe the algorithm, why it is suitable for the "unconventional" sensor and processing platform including the advantages as well as challenges faced.
Dynamic Power Management for Neuromorphic Many-Core Systems
Mar 21, 2019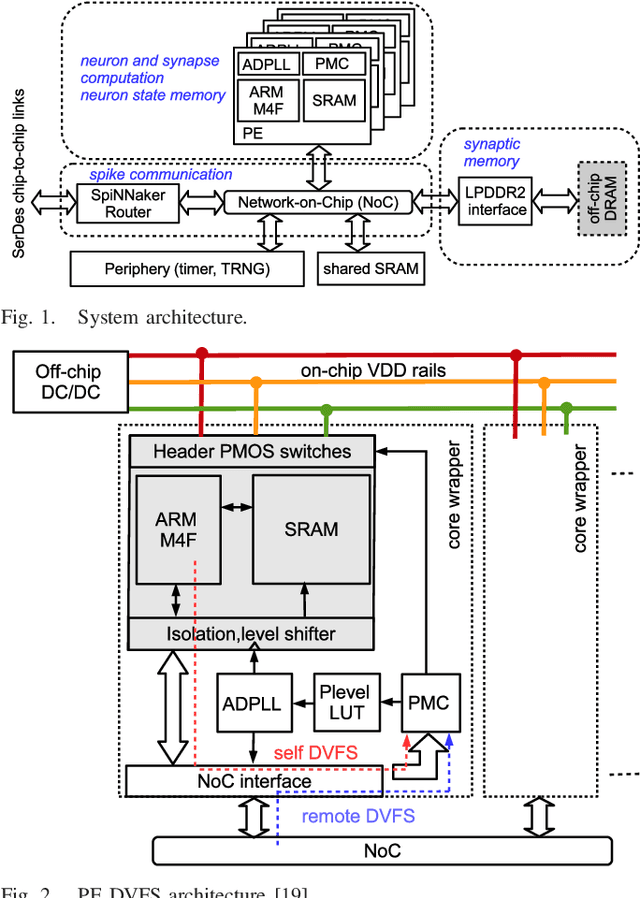

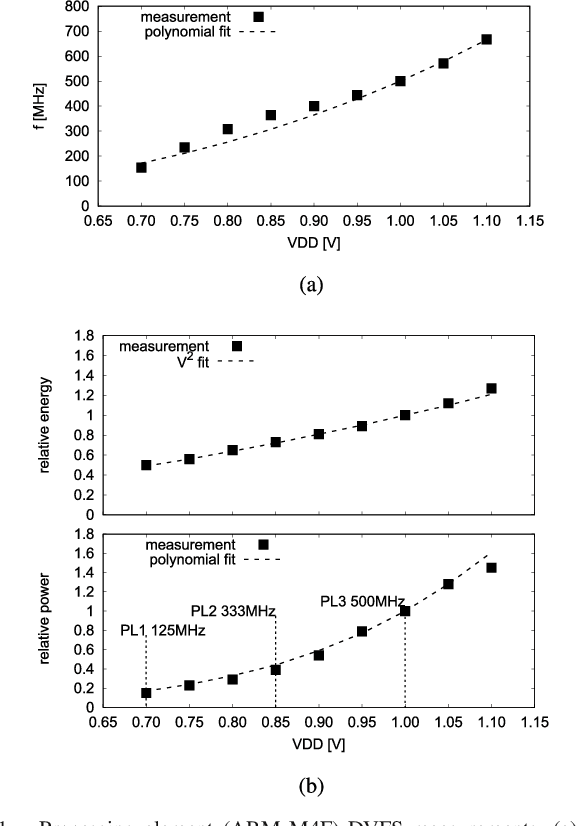
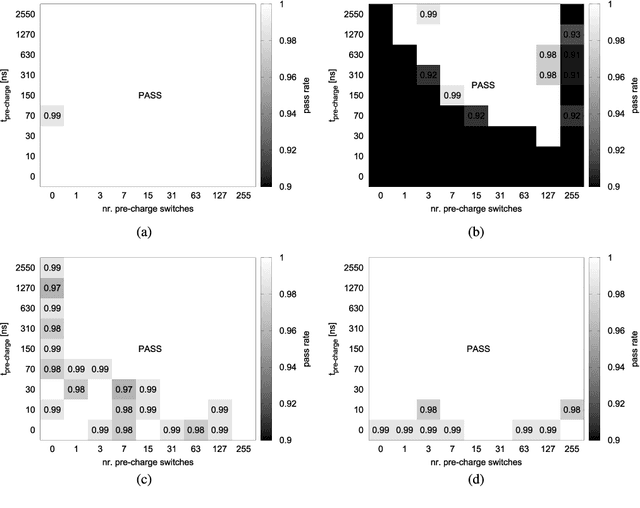
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than 100 ns. This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in 28 nm SLP CMOS technology has been implemented. It includes 4 PEs which can be scaled from 0.7 V to 1.0 V with frequencies from 125 MHz to 500 MHz at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by 75%, with 80% baseline power reduction and a 50% reduction of energy per neuron and synapse computation, all while maintaining temporary peak system performance to achieve biological real-time operation of the system. A numerical model of this power management model is derived which allows DVFS architecture exploration for neuromorphics. The proposed technique is to be used for the second generation SpiNNaker neuromorphic many core system.
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
Mar 20, 2019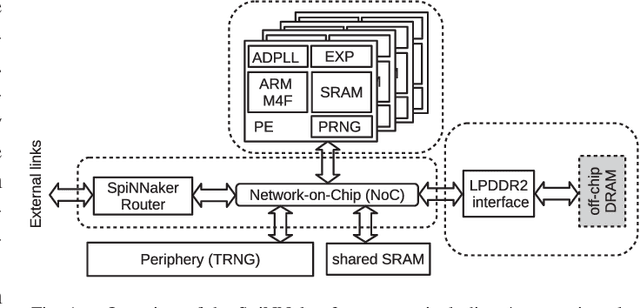
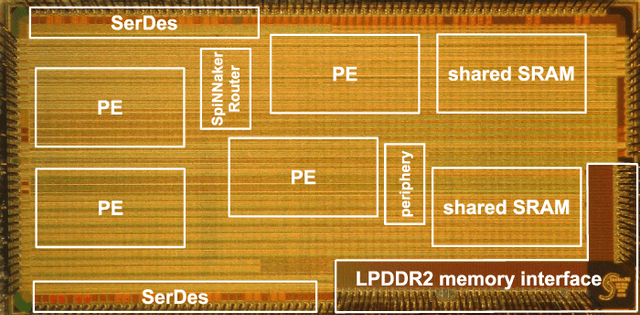
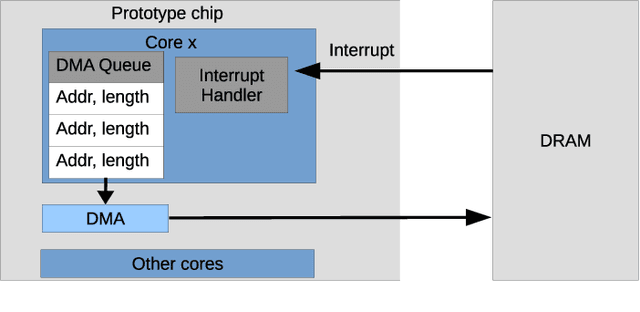
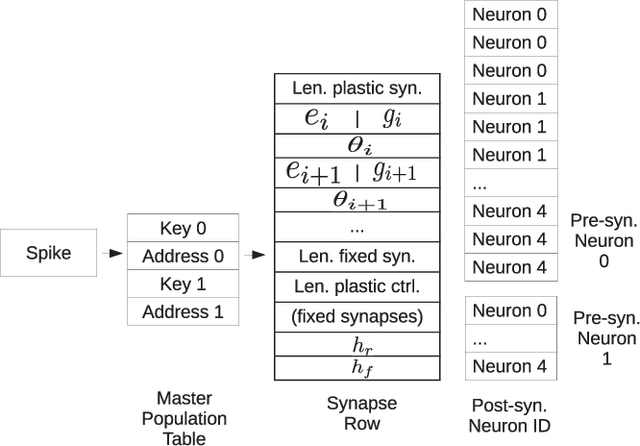
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.
SLAMBench2: Multi-Objective Head-to-Head Benchmarking for Visual SLAM
Aug 21, 2018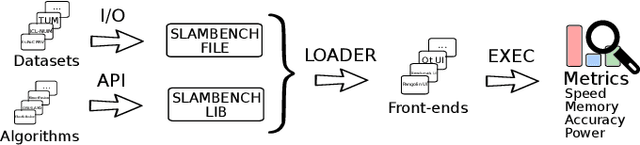


SLAM is becoming a key component of robotics and augmented reality (AR) systems. While a large number of SLAM algorithms have been presented, there has been little effort to unify the interface of such algorithms, or to perform a holistic comparison of their capabilities. This is a problem since different SLAM applications can have different functional and non-functional requirements. For example, a mobile phonebased AR application has a tight energy budget, while a UAV navigation system usually requires high accuracy. SLAMBench2 is a benchmarking framework to evaluate existing and future SLAM systems, both open and close source, over an extensible list of datasets, while using a comparable and clearly specified list of performance metrics. A wide variety of existing SLAM algorithms and datasets is supported, e.g. ElasticFusion, InfiniTAM, ORB-SLAM2, OKVIS, and integrating new ones is straightforward and clearly specified by the framework. SLAMBench2 is a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs across SLAM systems.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018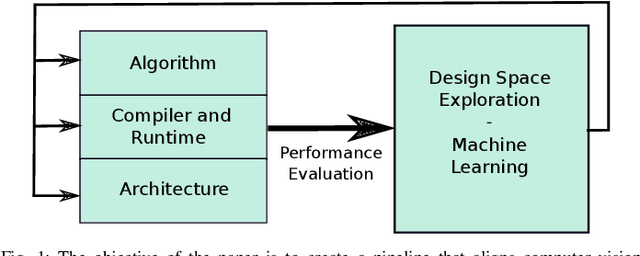

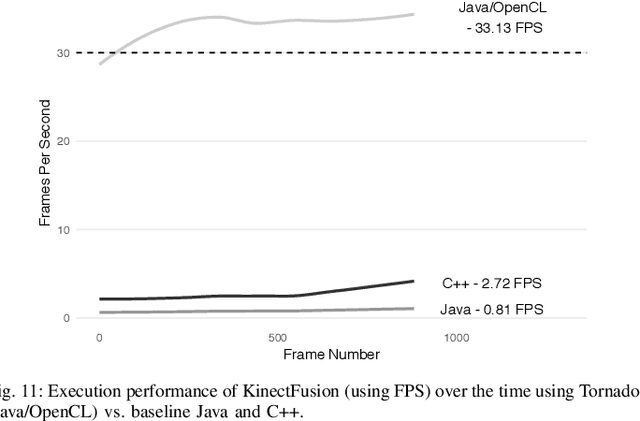
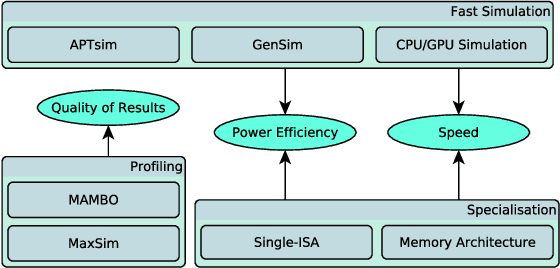
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.