 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deployment of Spiking Neural Networks on SpiNNaker2 for DVS Gesture Recognition Using Neuromorphic Intermediate Representation
Apr 09, 2025Spiking Neural Networks (SNNs) are highly energy-efficient during inference, making them particularly suitable for deployment on neuromorphic hardware. Their ability to process event-driven inputs, such as data from dynamic vision sensors (DVS), further enhances their applicability to edge computing tasks. However, the resource constraints of edge hardware necessitate techniques like weight quantization, which reduce the memory footprint of SNNs while preserving accuracy. Despite its importance, existing quantization methods typically focus on synaptic weights quantization without taking account of other critical parameters, such as scaling neuron firing thresholds. To address this limitation, we present the first benchmark for the DVS gesture recognition task using SNNs optimized for the many-core neuromorphic chip SpiNNaker2. Our study evaluates two quantization pipelines for fixed-point computations. The first approach employs post training quantization (PTQ) with percentile-based threshold scaling, while the second uses quantization aware training (QAT) with adaptive threshold scaling. Both methods achieve accurate 8-bit on-chip inference, closely approximating 32-bit floating-point performance. Additionally, our baseline SNNs perform competitively against previously reported results without specialized techniques. These models are deployed on SpiNNaker2 using the neuromorphic intermediate representation (NIR). Ultimately, we achieve 94.13% classification accuracy on-chip, demonstrating the SpiNNaker2's potential for efficient, low-energy neuromorphic computing.
* 8 pages, 3 figures, 8 tables, Conference-2025 Neuro Inspired Computational Elements (NICE)
STREAM: A Universal State-Space Model for Sparse Geometric Data
Nov 19, 2024Handling sparse and unstructured geometric data, such as point clouds or event-based vision, is a pressing challenge in the field of machine vision. Recently, sequence models such as Transformers and state-space models entered the domain of geometric data. These methods require specialized preprocessing to create a sequential view of a set of points. Furthermore, prior works involving sequence models iterate geometric data with either uniform or learned step sizes, implicitly relying on the model to infer the underlying geometric structure. In this work, we propose to encode geometric structure explicitly into the parameterization of a state-space model. State-space models are based on linear dynamics governed by a one-dimensional variable such as time or a spatial coordinate. We exploit this dynamic variable to inject relative differences of coordinates into the step size of the state-space model. The resulting geometric operation computes interactions between all pairs of N points in O(N) steps. Our model deploys the Mamba selective state-space model with a modified CUDA kernel to efficiently map sparse geometric data to modern hardware. The resulting sequence model, which we call STREAM, achieves competitive results on a range of benchmarks from point-cloud classification to event-based vision and audio classification. STREAM demonstrates a powerful inductive bias for sparse geometric data by improving the PointMamba baseline when trained from scratch on the ModelNet40 and ScanObjectNN point cloud analysis datasets. It further achieves, for the first time, 100% test accuracy on all 11 classes of the DVS128 Gestures dataset.
68-Channel Highly-Integrated Neural Signal Processing PSoC with On-Chip Feature Extraction, Compression, and Hardware Accelerators for Neuroprosthetics in 22nm FDSOI
Jul 12, 2024



Multi-channel electrophysiology systems for recording of neuronal activity face significant data throughput limitations, hampering real-time, data-informed experiments. These limitations impact both experimental neurobiology research and next-generation neuroprosthetics. We present a novel solution that leverages the high integration density of 22nm FDSOI CMOS technology to address these challenges. The proposed highly integrated programmable System-on-Chip comprises 68-channel 0.41 \textmu W/Ch recording frontends, spike detectors, 16-channel 0.87-4.39 \textmu W/Ch action potential and 8-channel 0.32 \textmu W/Ch local field potential codecs, as well as a MAC-assisted power-efficient processor operating at 25 MHz (5.19 \textmu W/MHz). The system supports on-chip training processes for compression, training and inference for neural spike sorting. The spike sorting achieves an average accuracy of 91.48% or 94.12% depending on the utilized features. The proposed PSoC is optimized for reduced area (9 mm2) and power. On-chip processing and compression capabilities free up the data bottlenecks in data transmission (up to 91% space saving ratio), and moreover enable a fully autonomous yet flexible processor-driven operation. Combined, these design considerations overcome data-bottlenecks by allowing on-chip feature extraction and subsequent compression.
ON-OFF Neuromorphic ISING Machines using Fowler-Nordheim Annealers
Jun 07, 2024We introduce NeuroSA, a neuromorphic architecture specifically designed to ensure asymptotic convergence to the ground state of an Ising problem using an annealing process that is governed by the physics of quantum mechanical tunneling using Fowler-Nordheim (FN). The core component of NeuroSA consists of a pair of asynchronous ON-OFF neurons, which effectively map classical simulated annealing (SA) dynamics onto a network of integrate-and-fire (IF) neurons. The threshold of each ON-OFF neuron pair is adaptively adjusted by an FN annealer which replicates the optimal escape mechanism and convergence of SA, particularly at low temperatures. To validate the effectiveness of our neuromorphic Ising machine, we systematically solved various benchmark MAX-CUT combinatorial optimization problems. Across multiple runs, NeuroSA consistently generates solutions that approach the state-of-the-art level with high accuracy (greater than 99%), and without any graph-specific hyperparameter tuning. For practical illustration, we present results from an implementation of NeuroSA on the SpiNNaker2 platform, highlighting the feasibility of mapping our proposed architecture onto a standard neuromorphic accelerator platform.
Weight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
May 01, 2024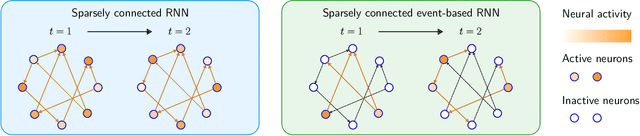
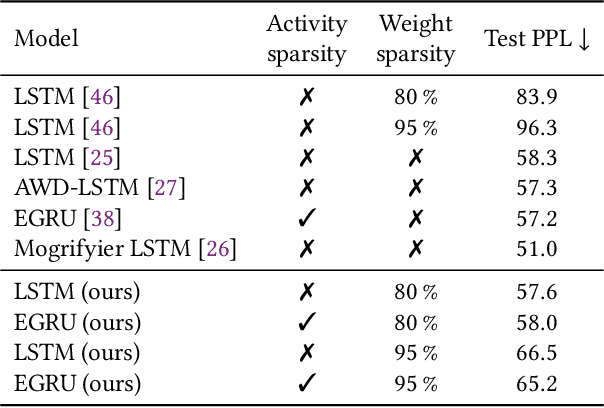
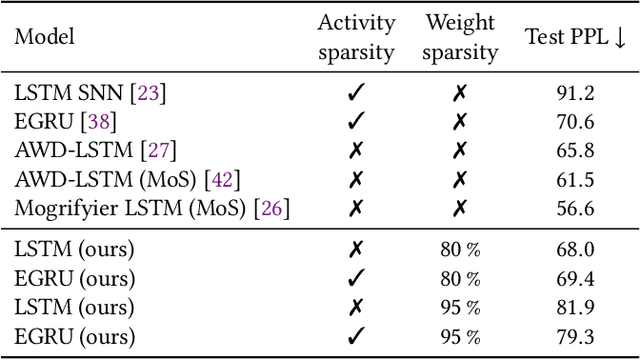
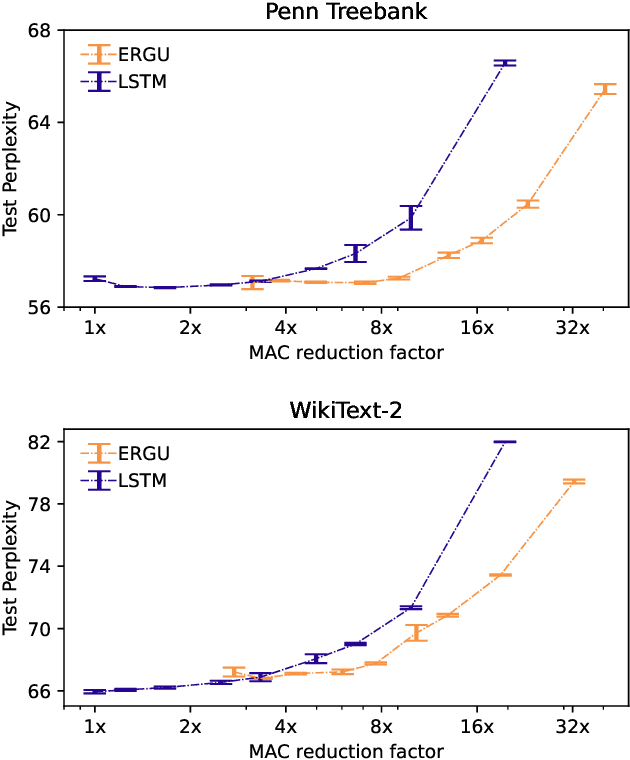
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.
Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models
Apr 29, 2024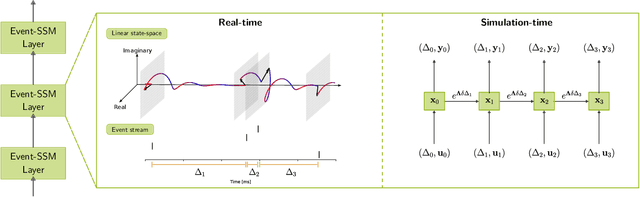
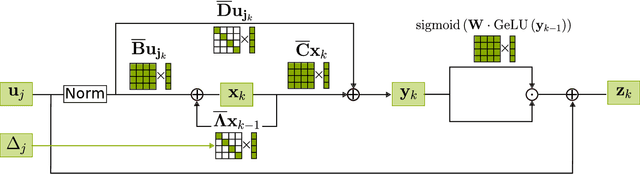

Event-based sensors are well suited for real-time processing due to their fast response times and encoding of the sensory data as successive temporal differences. These and other valuable properties, such as a high dynamic range, are suppressed when the data is converted to a frame-based format. However, most current methods either collapse events into frames or cannot scale up when processing the event data directly event-by-event. In this work, we address the key challenges of scaling up event-by-event modeling of the long event streams emitted by such sensors, which is a particularly relevant problem for neuromorphic computing. While prior methods can process up to a few thousand time steps, our model, based on modern recurrent deep state-space models, scales to event streams of millions of events for both training and inference.We leverage their stable parameterization for learning long-range dependencies, parallelizability along the sequence dimension, and their ability to integrate asynchronous events effectively to scale them up to long event streams.We further augment these with novel event-centric techniques enabling our model to match or beat the state-of-the-art performance on several event stream benchmarks. In the Spiking Speech Commands task, we improve state-of-the-art by a large margin of 6.6% to 87.1%. On the DVS128-Gestures dataset, we achieve competitive results without using frames or convolutional neural networks. Our work demonstrates, for the first time, that it is possible to use fully event-based processing with purely recurrent networks to achieve state-of-the-art task performance in several event-based benchmarks.
Neuromorphic hardware for sustainable AI data centers
Feb 04, 2024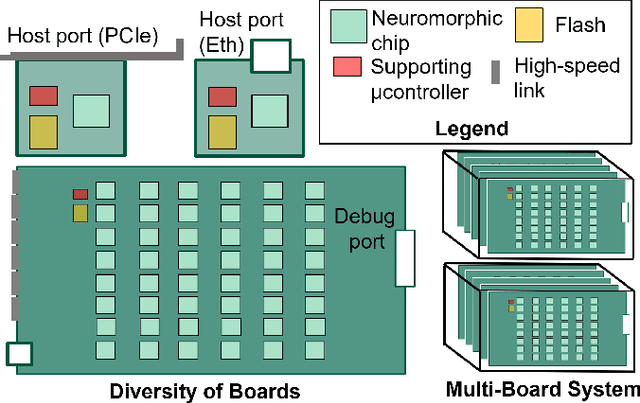
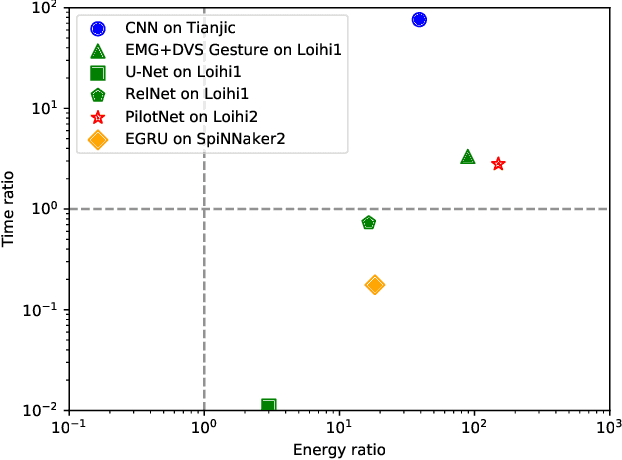
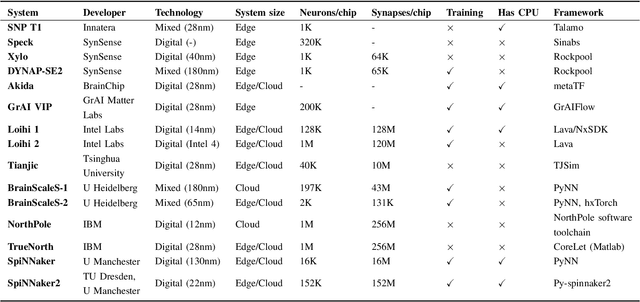

As humans advance toward a higher level of artificial intelligence, it is always at the cost of escalating computational resource consumption, which requires developing novel solutions to meet the exponential growth of AI computing demand. Neuromorphic hardware takes inspiration from how the brain processes information and promises energy-efficient computing of AI workloads. Despite its potential, neuromorphic hardware has not found its way into commercial AI data centers. In this article, we try to analyze the underlying reasons for this and derive requirements and guidelines to promote neuromorphic systems for efficient and sustainable cloud computing: We first review currently available neuromorphic hardware systems and collect examples where neuromorphic solutions excel conventional AI processing on CPUs and GPUs. Next, we identify applications, models and algorithms which are commonly deployed in AI data centers as further directions for neuromorphic algorithms research. Last, we derive requirements and best practices for the hardware and software integration of neuromorphic systems into data centers. With this article, we hope to increase awareness of the challenges of integrating neuromorphic hardware into data centers and to guide the community to enable sustainable and energy-efficient AI at scale.
SpiNNaker2: A Large-Scale Neuromorphic System for Event-Based and Asynchronous Machine Learning
Jan 09, 2024The joint progress of artificial neural networks (ANNs) and domain specific hardware accelerators such as GPUs and TPUs took over many domains of machine learning research. This development is accompanied by a rapid growth of the required computational demands for larger models and more data. Concurrently, emerging properties of foundation models such as in-context learning drive new opportunities for machine learning applications. However, the computational cost of such applications is a limiting factor of the technology in data centers, and more importantly in mobile devices and edge systems. To mediate the energy footprint and non-trivial latency of contemporary systems, neuromorphic computing systems deeply integrate computational principles of neurobiological systems by leveraging low-power analog and digital technologies. SpiNNaker2 is a digital neuromorphic chip developed for scalable machine learning. The event-based and asynchronous design of SpiNNaker2 allows the composition of large-scale systems involving thousands of chips. This work features the operating principles of SpiNNaker2 systems, outlining the prototype of novel machine learning applications. These applications range from ANNs over bio-inspired spiking neural networks to generalized event-based neural networks. With the successful development and deployment of SpiNNaker2, we aim to facilitate the advancement of event-based and asynchronous algorithms for future generations of machine learning systems.
Language Modeling on a SpiNNaker 2 Neuromorphic Chip
Dec 14, 2023



As large language models continue to scale in size rapidly, so too does the computational power required to run them. Event-based networks on neuromorphic devices offer a potential way to reduce energy consumption for inference significantly. However, to date, most event-based networks that can run on neuromorphic hardware, including spiking neural networks (SNNs), have not achieved task performance even on par with LSTM models for language modeling. As a result, language modeling on neuromorphic devices has seemed a distant prospect. In this work, we demonstrate the first-ever implementation of a language model on a neuromorphic device - specifically the SpiNNaker 2 chip - based on a recently published event-based architecture called the EGRU. SpiNNaker 2 is a many-core neuromorphic chip designed for large-scale asynchronous processing, while the EGRU is architected to leverage such hardware efficiently while maintaining competitive task performance. This implementation marks the first time a neuromorphic language model matches LSTMs, setting the stage for taking task performance to the level of large language models. We also demonstrate results on a gesture recognition task based on inputs from a DVS camera. Overall, our results showcase the feasibility of this neuro-inspired neural network in hardware, highlighting significant gains versus conventional hardware in energy efficiency for the common use case of single batch inference.
Activity Sparsity Complements Weight Sparsity for Efficient RNN Inference
Nov 13, 2023Artificial neural networks open up unprecedented machine learning capabilities at the cost of ever growing computational requirements. Sparsifying the parameters, often achieved through weight pruning, has been identified as a powerful technique to compress the number of model parameters and reduce the computational operations of neural networks. Yet, sparse activations, while omnipresent in both biological neural networks and deep learning systems, have not been fully utilized as a compression technique in deep learning. Moreover, the interaction between sparse activations and weight pruning is not fully understood. In this work, we demonstrate that activity sparsity can compose multiplicatively with parameter sparsity in a recurrent neural network model based on the GRU that is designed to be activity sparse. We achieve up to $20\times$ reduction of computation while maintaining perplexities below $60$ on the Penn Treebank language modeling task. This magnitude of reduction has not been achieved previously with solely sparsely connected LSTMs, and the language modeling performance of our model has not been achieved previously with any sparsely activated recurrent neural networks or spiking neural networks. Neuromorphic computing devices are especially good at taking advantage of the dynamic activity sparsity, and our results provide strong evidence that making deep learning models activity sparse and porting them to neuromorphic devices can be a viable strategy that does not compromise on task performance. Our results also drive further convergence of methods from deep learning and neuromorphic computing for efficient machine learning.