 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUstnlp16 at SemEval-2025 Task 9: Improving Model Performance through Imbalance Handling and Focal Loss
Apr 24, 2025



Classification tasks often suffer from imbal- anced data distribution, which presents chal- lenges in food hazard detection due to severe class imbalances, short and unstructured text, and overlapping semantic categories. In this paper, we present our system for SemEval- 2025 Task 9: Food Hazard Detection, which ad- dresses these issues by applying data augmenta- tion techniques to improve classification perfor- mance. We utilize transformer-based models, BERT and RoBERTa, as backbone classifiers and explore various data balancing strategies, including random oversampling, Easy Data Augmentation (EDA), and focal loss. Our ex- periments show that EDA effectively mitigates class imbalance, leading to significant improve- ments in accuracy and F1 scores. Furthermore, combining focal loss with oversampling and EDA further enhances model robustness, par- ticularly for hard-to-classify examples. These findings contribute to the development of more effective NLP-based classification models for food hazard detection.
68-Channel Highly-Integrated Neural Signal Processing PSoC with On-Chip Feature Extraction, Compression, and Hardware Accelerators for Neuroprosthetics in 22nm FDSOI
Jul 12, 2024



Multi-channel electrophysiology systems for recording of neuronal activity face significant data throughput limitations, hampering real-time, data-informed experiments. These limitations impact both experimental neurobiology research and next-generation neuroprosthetics. We present a novel solution that leverages the high integration density of 22nm FDSOI CMOS technology to address these challenges. The proposed highly integrated programmable System-on-Chip comprises 68-channel 0.41 \textmu W/Ch recording frontends, spike detectors, 16-channel 0.87-4.39 \textmu W/Ch action potential and 8-channel 0.32 \textmu W/Ch local field potential codecs, as well as a MAC-assisted power-efficient processor operating at 25 MHz (5.19 \textmu W/MHz). The system supports on-chip training processes for compression, training and inference for neural spike sorting. The spike sorting achieves an average accuracy of 91.48% or 94.12% depending on the utilized features. The proposed PSoC is optimized for reduced area (9 mm2) and power. On-chip processing and compression capabilities free up the data bottlenecks in data transmission (up to 91% space saving ratio), and moreover enable a fully autonomous yet flexible processor-driven operation. Combined, these design considerations overcome data-bottlenecks by allowing on-chip feature extraction and subsequent compression.
Deploying Machine Learning Models to Ahead-of-Time Runtime on Edge Using MicroTVM
Apr 14, 2023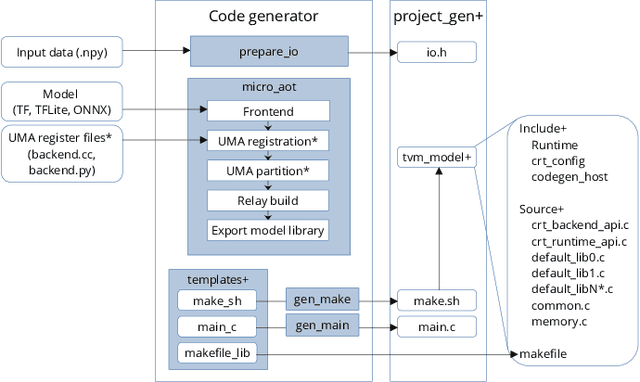

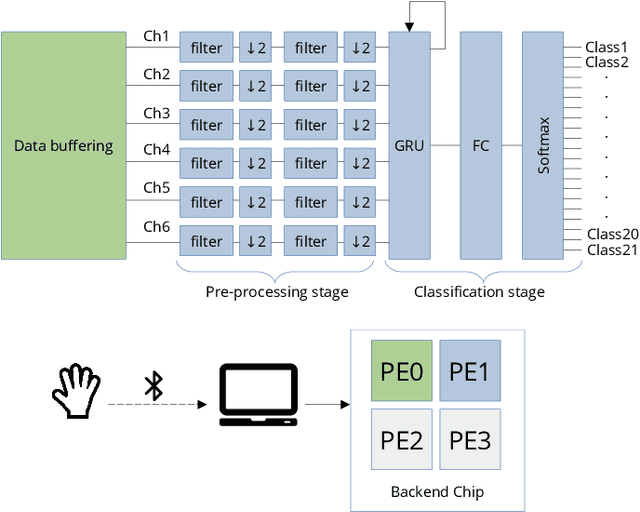
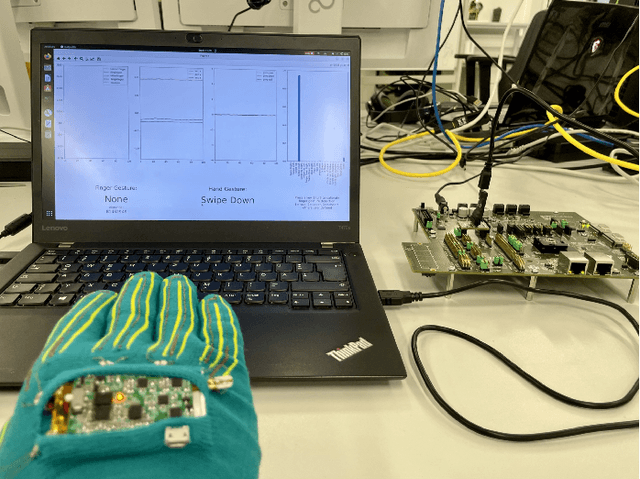
In the past few years, more and more AI applications have been applied to edge devices. However, models trained by data scientists with machine learning frameworks, such as PyTorch or TensorFlow, can not be seamlessly executed on edge. In this paper, we develop an end-to-end code generator parsing a pre-trained model to C source libraries for the backend using MicroTVM, a machine learning compiler framework extension addressing inference on bare metal devices. An analysis shows that specific compute-intensive operators can be easily offloaded to the dedicated accelerator with a Universal Modular Accelerator (UMA) interface, while others are processed in the CPU cores. By using the automatically generated ahead-of-time C runtime, we conduct a hand gesture recognition experiment on an ARM Cortex M4F core.
Quaternion Orthogonal Transformer for Facial Expression Recognition in the Wild
Mar 14, 2023Facial expression recognition (FER) is a challenging topic in artificial intelligence. Recently, many researchers have attempted to introduce Vision Transformer (ViT) to the FER task. However, ViT cannot fully utilize emotional features extracted from raw images and requires a lot of computing resources. To overcome these problems, we propose a quaternion orthogonal transformer (QOT) for FER. Firstly, to reduce redundancy among features extracted from pre-trained ResNet-50, we use the orthogonal loss to decompose and compact these features into three sets of orthogonal sub-features. Secondly, three orthogonal sub-features are integrated into a quaternion matrix, which maintains the correlations between different orthogonal components. Finally, we develop a quaternion vision transformer (Q-ViT) for feature classification. The Q-ViT adopts quaternion operations instead of the original operations in ViT, which improves the final accuracies with fewer parameters. Experimental results on three in-the-wild FER datasets show that the proposed QOT outperforms several state-of-the-art models and reduces the computations.