 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Bigger Models for Science? Task-Aware Retrieval with Small Language Models
Apr 02, 2026Scientific knowledge discovery increasingly relies on large language models, yet many existing scholarly assistants depend on proprietary systems with tens or hundreds of billions of parameters. Such reliance limits reproducibility and accessibility for the research community. In this work, we ask a simple question: do we need bigger models for scientific applications? Specifically, we investigate to what extent carefully designed retrieval pipelines can compensate for reduced model scale in scientific applications. We design a lightweight retrieval-augmented framework that performs task-aware routing to select specialized retrieval strategies based on the input query. The system further integrates evidence from full-text scientific papers and structured scholarly metadata, and employs compact instruction-tuned language models to generate responses with citations. We evaluate the framework across several scholarly tasks, focusing on scholarly question answering (QA), including single- and multi-document scenarios, as well as biomedical QA under domain shift and scientific text compression. Our findings demonstrate that retrieval and model scale are complementary rather than interchangeable. While retrieval design can partially compensate for smaller models, model capacity remains important for complex reasoning tasks. This work highlights retrieval and task-aware design as key factors for building practical and reproducible scholarly assistants.
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
Deploying Machine Learning Models to Ahead-of-Time Runtime on Edge Using MicroTVM
Apr 14, 2023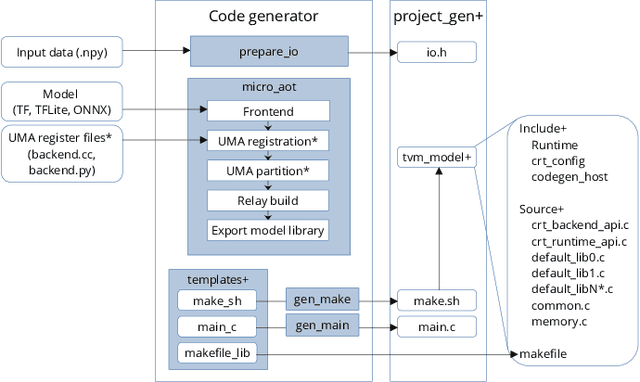

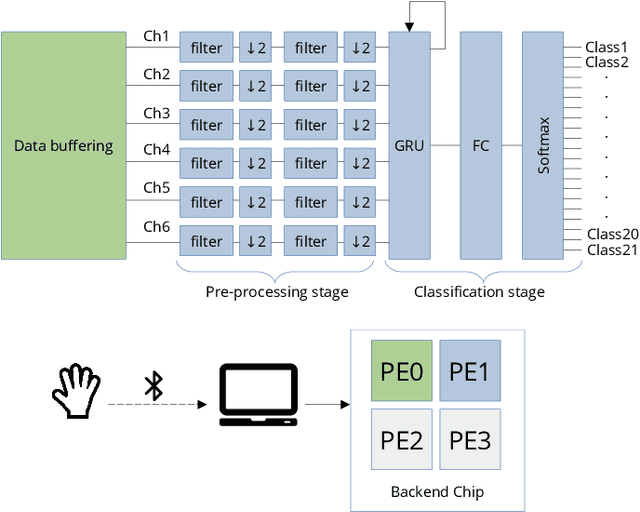
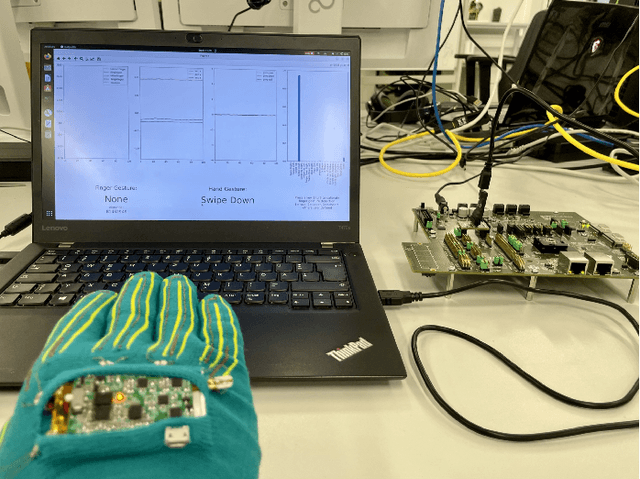
In the past few years, more and more AI applications have been applied to edge devices. However, models trained by data scientists with machine learning frameworks, such as PyTorch or TensorFlow, can not be seamlessly executed on edge. In this paper, we develop an end-to-end code generator parsing a pre-trained model to C source libraries for the backend using MicroTVM, a machine learning compiler framework extension addressing inference on bare metal devices. An analysis shows that specific compute-intensive operators can be easily offloaded to the dedicated accelerator with a Universal Modular Accelerator (UMA) interface, while others are processed in the CPU cores. By using the automatically generated ahead-of-time C runtime, we conduct a hand gesture recognition experiment on an ARM Cortex M4F core.