 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Analysis of Hybrid Linear Attention
Jul 08, 2025Transformers face quadratic complexity and memory issues with long sequences, prompting the adoption of linear attention mechanisms using fixed-size hidden states. However, linear models often suffer from limited recall performance, leading to hybrid architectures that combine linear and full attention layers. Despite extensive hybrid architecture research, the choice of linear attention component has not been deeply explored. We systematically evaluate various linear attention models across generations - vector recurrences to advanced gating mechanisms - both standalone and hybridized. To enable this comprehensive analysis, we trained and open-sourced 72 models: 36 at 340M parameters (20B tokens) and 36 at 1.3B parameters (100B tokens), covering six linear attention variants across five hybridization ratios. Benchmarking on standard language modeling and recall tasks reveals that superior standalone linear models do not necessarily excel in hybrids. While language modeling remains stable across linear-to-full attention ratios, recall significantly improves with increased full attention layers, particularly below a 3:1 ratio. Our study highlights selective gating, hierarchical recurrence, and controlled forgetting as critical for effective hybrid models. We recommend architectures such as HGRN-2 or GatedDeltaNet with a linear-to-full ratio between 3:1 and 6:1 to achieve Transformer-level recall efficiently. Our models are open-sourced at https://huggingface.co/collections/m-a-p/hybrid-linear-attention-research-686c488a63d609d2f20e2b1e.
Accelerating Linear Recurrent Neural Networks for the Edge with Unstructured Sparsity
Feb 03, 2025



Linear recurrent neural networks enable powerful long-range sequence modeling with constant memory usage and time-per-token during inference. These architectures hold promise for streaming applications at the edge, but deployment in resource-constrained environments requires hardware-aware optimizations to minimize latency and energy consumption. Unstructured sparsity offers a compelling solution, enabling substantial reductions in compute and memory requirements--when accelerated by compatible hardware platforms. In this paper, we conduct a scaling study to investigate the Pareto front of performance and efficiency across inference compute budgets. We find that highly sparse linear RNNs consistently achieve better efficiency-performance trade-offs than dense baselines, with 2x less compute and 36% less memory at iso-accuracy. Our models achieve state-of-the-art results on a real-time streaming task for audio denoising. By quantizing our sparse models to fixed-point arithmetic and deploying them on the Intel Loihi 2 neuromorphic chip for real-time processing, we translate model compression into tangible gains of 42x lower latency and 149x lower energy consumption compared to a dense model on an edge GPU. Our findings showcase the transformative potential of unstructured sparsity, paving the way for highly efficient recurrent neural networks in real-world, resource-constrained environments.
Mamba-PTQ: Outlier Channels in Recurrent Large Language Models
Jul 17, 2024Modern recurrent layers are emerging as a promising path toward edge deployment of foundation models, especially in the context of large language models (LLMs). Compressing the whole input sequence in a finite-dimensional representation enables recurrent layers to model long-range dependencies while maintaining a constant inference cost for each token and a fixed memory requirement. However, the practical deployment of LLMs in resource-limited environments often requires further model compression, such as quantization and pruning. While these techniques are well-established for attention-based models, their effects on recurrent layers remain underexplored. In this preliminary work, we focus on post-training quantization for recurrent LLMs and show that Mamba models exhibit the same pattern of outlier channels observed in attention-based LLMs. We show that the reason for the difficulty of quantizing SSMs is caused by activation outliers, similar to those observed in transformer-based LLMs. We report baseline results for post-training quantization of Mamba that do not take into account the activation outliers and suggest first steps for outlier-aware quantization.
Q-S5: Towards Quantized State Space Models
Jun 13, 2024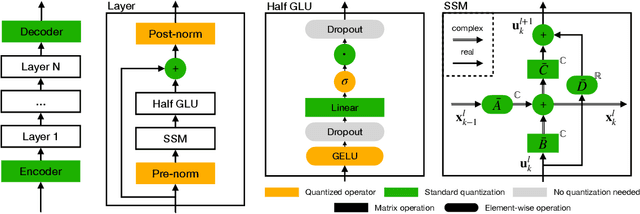
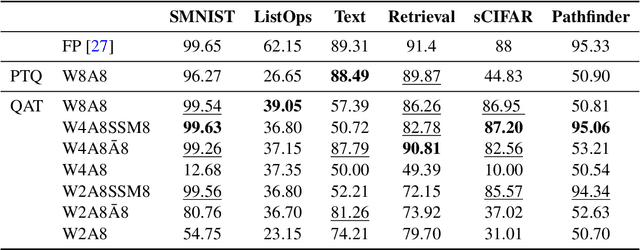
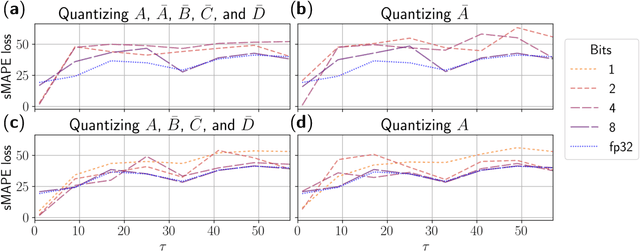
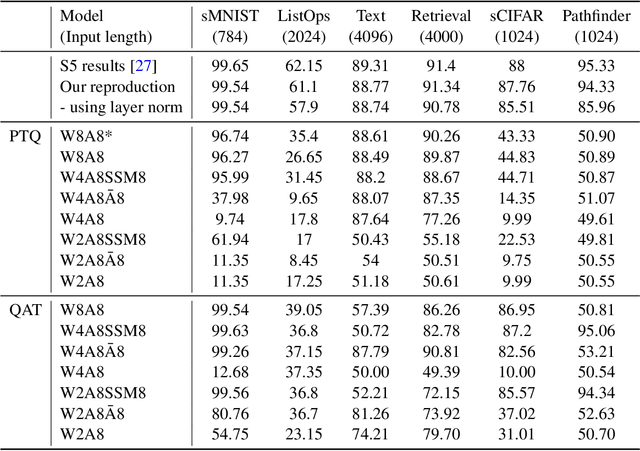
In the quest for next-generation sequence modeling architectures, State Space Models (SSMs) have emerged as a potent alternative to transformers, particularly for their computational efficiency and suitability for dynamical systems. This paper investigates the effect of quantization on the S5 model to understand its impact on model performance and to facilitate its deployment to edge and resource-constrained platforms. Using quantization-aware training (QAT) and post-training quantization (PTQ), we systematically evaluate the quantization sensitivity of SSMs across different tasks like dynamical systems modeling, Sequential MNIST (sMNIST) and most of the Long Range Arena (LRA). We present fully quantized S5 models whose test accuracy drops less than 1% on sMNIST and most of the LRA. We find that performance on most tasks degrades significantly for recurrent weights below 8-bit precision, but that other components can be compressed further without significant loss of performance. Our results further show that PTQ only performs well on language-based LRA tasks whereas all others require QAT. Our investigation provides necessary insights for the continued development of efficient and hardware-optimized SSMs.
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
Concepts and Paradigms for Neuromorphic Programming
Oct 27, 2023The value of neuromorphic computers depends crucially on our ability to program them for relevant tasks. Currently, neuromorphic computers are mostly limited to machine learning methods adapted from deep learning. However, neuromorphic computers have potential far beyond deep learning if we can only make use of their computational properties to harness their full power. Neuromorphic programming will necessarily be different from conventional programming, requiring a paradigm shift in how we think about programming in general. The contributions of this paper are 1) a conceptual analysis of what "programming" means in the context of neuromorphic computers and 2) an exploration of existing programming paradigms that are promising yet overlooked in neuromorphic computing. The goal is to expand the horizon of neuromorphic programming methods, thereby allowing researchers to move beyond the shackles of current methods and explore novel directions.
Training a spiking neural network on an event-based label-free flow cytometry dataset
Mar 19, 2023

Imaging flow cytometry systems aim to analyze a huge number of cells or micro-particles based on their physical characteristics. The vast majority of current systems acquire a large amount of images which are used to train deep artificial neural networks. However, this approach increases both the latency and power consumption of the final apparatus. In this work-in-progress, we combine an event-based camera with a free-space optical setup to obtain spikes for each particle passing in a microfluidic channel. A spiking neural network is trained on the collected dataset, resulting in 97.7% mean training accuracy and 93.5% mean testing accuracy for the fully event-based classification pipeline.
Automated Architecture Design for Deep Neural Networks
Aug 22, 2019
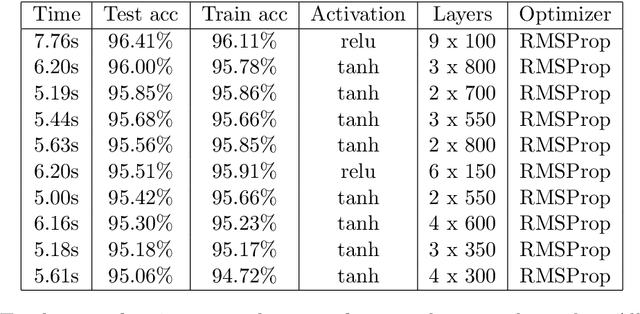

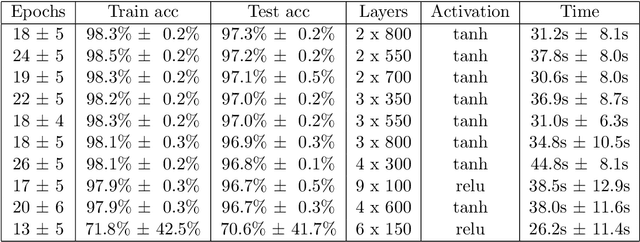
Machine learning has made tremendous progress in recent years and received large amounts of public attention. Though we are still far from designing a full artificially intelligent agent, machine learning has brought us many applications in which computers solve human learning tasks remarkably well. Much of this progress comes from a recent trend within machine learning, called deep learning. Deep learning models are responsible for many state-of-the-art applications of machine learning. Despite their success, deep learning models are hard to train, very difficult to understand, and often times so complex that training is only possible on very large GPU clusters. Lots of work has been done on enabling neural networks to learn efficiently. However, the design and architecture of such neural networks is often done manually through trial and error and expert knowledge. This thesis inspects different approaches, existing and novel, to automate the design of deep feedforward neural networks in an attempt to create less complex models with good performance that take away the burden of deciding on an architecture and make it more efficient to design and train such deep networks.