 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Linear Recurrent Neural Networks for the Edge with Unstructured Sparsity
Feb 03, 2025



Linear recurrent neural networks enable powerful long-range sequence modeling with constant memory usage and time-per-token during inference. These architectures hold promise for streaming applications at the edge, but deployment in resource-constrained environments requires hardware-aware optimizations to minimize latency and energy consumption. Unstructured sparsity offers a compelling solution, enabling substantial reductions in compute and memory requirements--when accelerated by compatible hardware platforms. In this paper, we conduct a scaling study to investigate the Pareto front of performance and efficiency across inference compute budgets. We find that highly sparse linear RNNs consistently achieve better efficiency-performance trade-offs than dense baselines, with 2x less compute and 36% less memory at iso-accuracy. Our models achieve state-of-the-art results on a real-time streaming task for audio denoising. By quantizing our sparse models to fixed-point arithmetic and deploying them on the Intel Loihi 2 neuromorphic chip for real-time processing, we translate model compression into tangible gains of 42x lower latency and 149x lower energy consumption compared to a dense model on an edge GPU. Our findings showcase the transformative potential of unstructured sparsity, paving the way for highly efficient recurrent neural networks in real-world, resource-constrained environments.
Solving QUBO on the Loihi 2 Neuromorphic Processor
Aug 06, 2024



In this article, we describe an algorithm for solving Quadratic Unconstrained Binary Optimization problems on the Intel Loihi 2 neuromorphic processor. The solver is based on a hardware-aware fine-grained parallel simulated annealing algorithm developed for Intel's neuromorphic research chip Loihi 2. Preliminary results show that our approach can generate feasible solutions in as little as 1 ms and up to 37x more energy efficient compared to two baseline solvers running on a CPU. These advantages could be especially relevant for size-, weight-, and power-constrained edge computing applications.
Neuromorphic quadratic programming for efficient and scalable model predictive control
Jan 26, 2024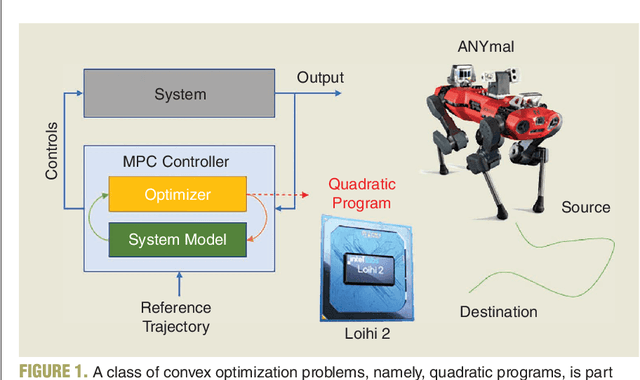
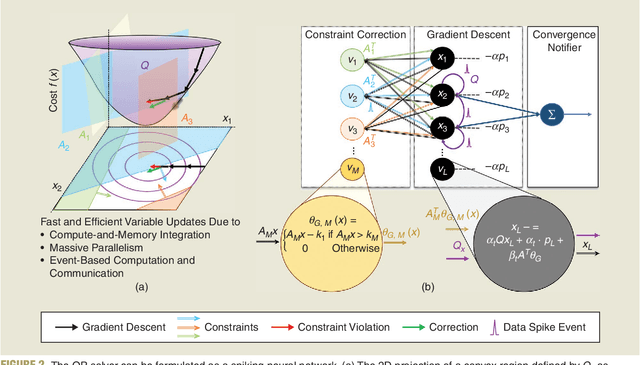
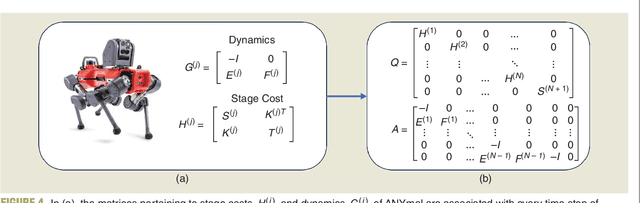
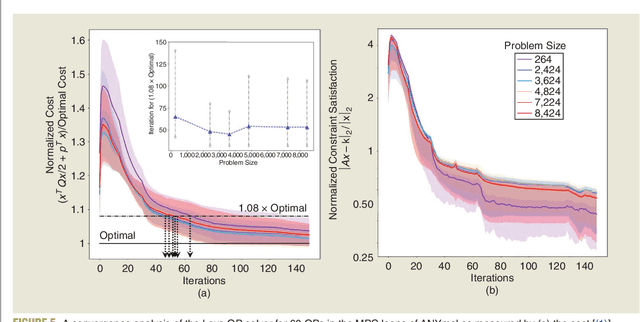
Applications in robotics or other size-, weight- and power-constrained autonomous systems at the edge often require real-time and low-energy solutions to large optimization problems. Event-based and memory-integrated neuromorphic architectures promise to solve such optimization problems with superior energy efficiency and performance compared to conventional von Neumann architectures. Here, we present a method to solve convex continuous optimization problems with quadratic cost functions and linear constraints on Intel's scalable neuromorphic research chip Loihi 2. When applied to model predictive control (MPC) problems for the quadruped robotic platform ANYmal, this method achieves over two orders of magnitude reduction in combined energy-delay product compared to the state-of-the-art solver, OSQP, on (edge) CPUs and GPUs with solution times under ten milliseconds for various problem sizes. These results demonstrate the benefit of non-von-Neumann architectures for robotic control applications.
A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware
Jul 08, 2021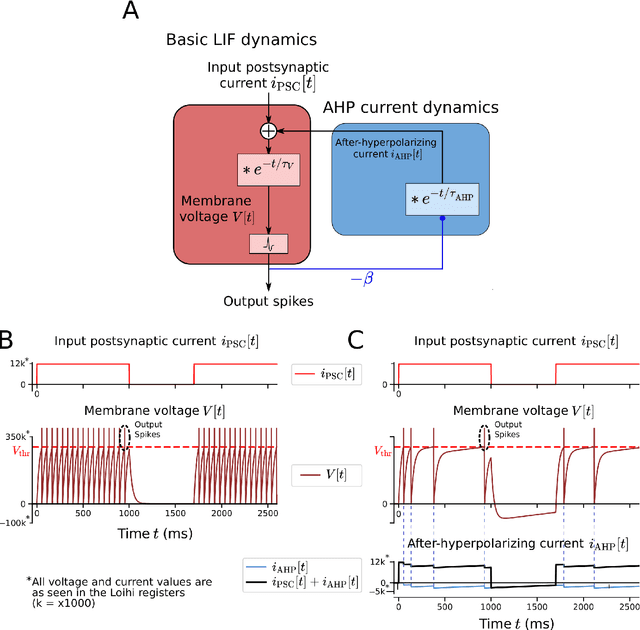
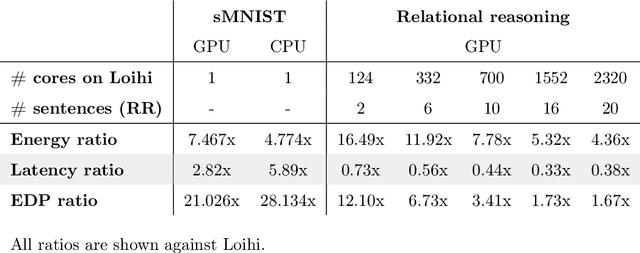
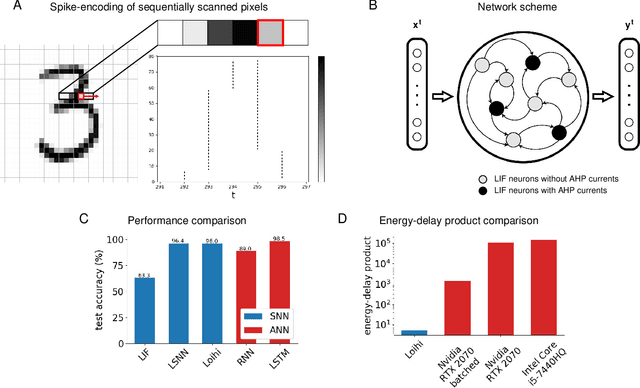
In spite of intensive efforts it has remained an open problem to what extent current Artificial Intelligence (AI) methods that employ Deep Neural Networks (DNNs) can be implemented more energy-efficiently on spike-based neuromorphic hardware. This holds in particular for AI methods that solve sequence processing tasks, a primary application target for spike-based neuromorphic hardware. One difficulty is that DNNs for such tasks typically employ Long Short-Term Memory (LSTM) units. Yet an efficient emulation of these units in spike-based hardware has been missing. We present a biologically inspired solution that solves this problem. This solution enables us to implement a major class of DNNs for sequence processing tasks such as time series classification and question answering with substantial energy savings on neuromorphic hardware. In fact, the Relational Network for reasoning about relations between objects that we use for question answering is the first example of a large DNN that carries out a sequence processing task with substantial energy-saving on neuromorphic hardware.
Neuromorphic Nearest-Neighbor Search Using Intel's Pohoiki Springs
Apr 27, 2020
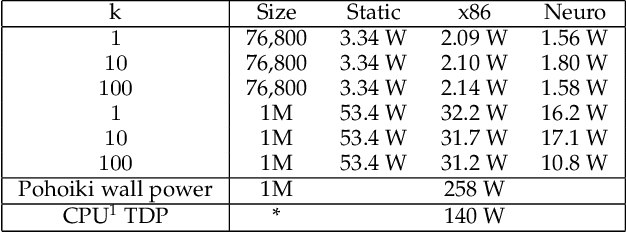

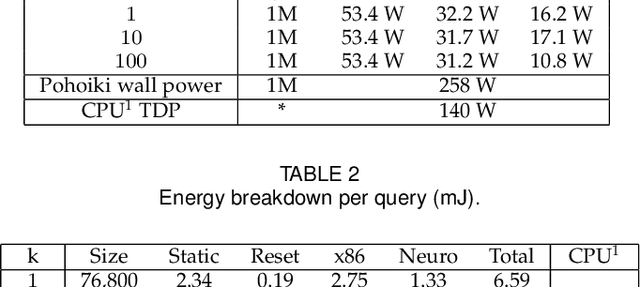
Neuromorphic computing applies insights from neuroscience to uncover innovations in computing technology. In the brain, billions of interconnected neurons perform rapid computations at extremely low energy levels by leveraging properties that are foreign to conventional computing systems, such as temporal spiking codes and finely parallelized processing units integrating both memory and computation. Here, we showcase the Pohoiki Springs neuromorphic system, a mesh of 768 interconnected Loihi chips that collectively implement 100 million spiking neurons in silicon. We demonstrate a scalable approximate k-nearest neighbor (k-NN) algorithm for searching large databases that exploits neuromorphic principles. Compared to state-of-the-art conventional CPU-based implementations, we achieve superior latency, index build time, and energy efficiency when evaluated on several standard datasets containing over 1 million high-dimensional patterns. Further, the system supports adding new data points to the indexed database online in O(1) time unlike all but brute force conventional k-NN implementations.