 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Linear Recurrent Neural Networks for the Edge with Unstructured Sparsity
Feb 03, 2025



Linear recurrent neural networks enable powerful long-range sequence modeling with constant memory usage and time-per-token during inference. These architectures hold promise for streaming applications at the edge, but deployment in resource-constrained environments requires hardware-aware optimizations to minimize latency and energy consumption. Unstructured sparsity offers a compelling solution, enabling substantial reductions in compute and memory requirements--when accelerated by compatible hardware platforms. In this paper, we conduct a scaling study to investigate the Pareto front of performance and efficiency across inference compute budgets. We find that highly sparse linear RNNs consistently achieve better efficiency-performance trade-offs than dense baselines, with 2x less compute and 36% less memory at iso-accuracy. Our models achieve state-of-the-art results on a real-time streaming task for audio denoising. By quantizing our sparse models to fixed-point arithmetic and deploying them on the Intel Loihi 2 neuromorphic chip for real-time processing, we translate model compression into tangible gains of 42x lower latency and 149x lower energy consumption compared to a dense model on an edge GPU. Our findings showcase the transformative potential of unstructured sparsity, paving the way for highly efficient recurrent neural networks in real-world, resource-constrained environments.
Solving QUBO on the Loihi 2 Neuromorphic Processor
Aug 06, 2024In this article, we describe an algorithm for solving Quadratic Unconstrained Binary Optimization problems on the Intel Loihi 2 neuromorphic processor. The solver is based on a hardware-aware fine-grained parallel simulated annealing algorithm developed for Intel's neuromorphic research chip Loihi 2. Preliminary results show that our approach can generate feasible solutions in as little as 1 ms and up to 37x more energy efficient compared to two baseline solvers running on a CPU. These advantages could be especially relevant for size-, weight-, and power-constrained edge computing applications.
Neuromorphic quadratic programming for efficient and scalable model predictive control
Jan 26, 2024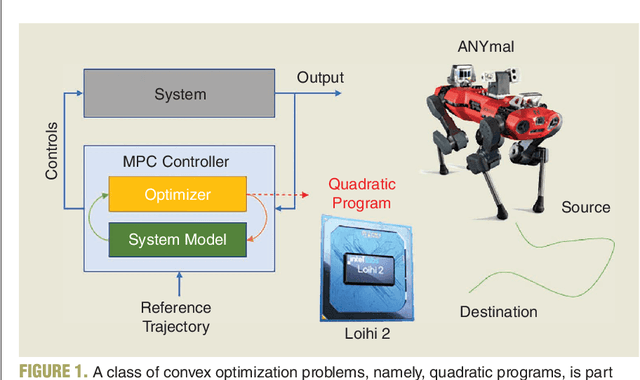
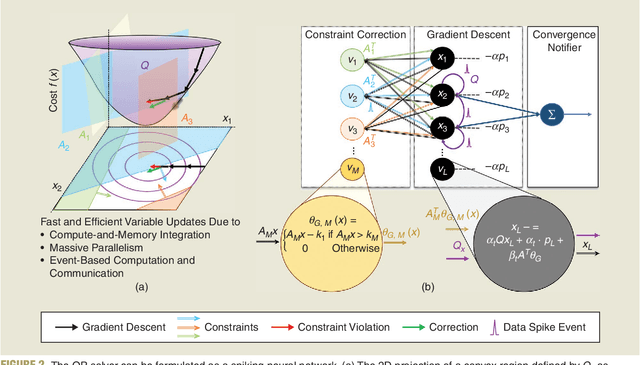
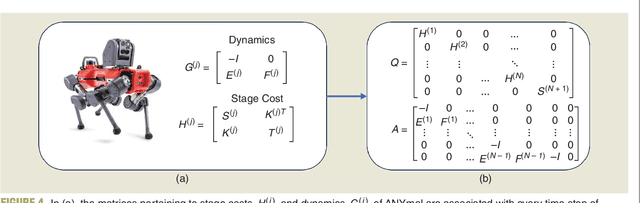
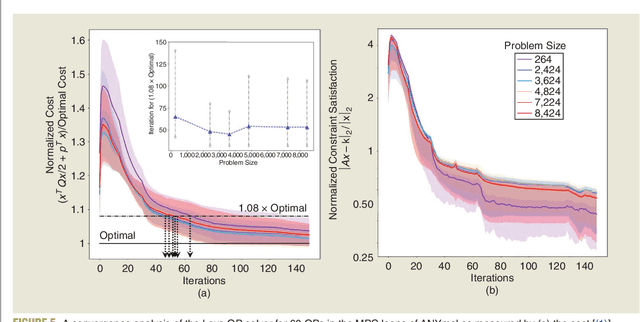
Applications in robotics or other size-, weight- and power-constrained autonomous systems at the edge often require real-time and low-energy solutions to large optimization problems. Event-based and memory-integrated neuromorphic architectures promise to solve such optimization problems with superior energy efficiency and performance compared to conventional von Neumann architectures. Here, we present a method to solve convex continuous optimization problems with quadratic cost functions and linear constraints on Intel's scalable neuromorphic research chip Loihi 2. When applied to model predictive control (MPC) problems for the quadruped robotic platform ANYmal, this method achieves over two orders of magnitude reduction in combined energy-delay product compared to the state-of-the-art solver, OSQP, on (edge) CPUs and GPUs with solution times under ten milliseconds for various problem sizes. These results demonstrate the benefit of non-von-Neumann architectures for robotic control applications.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.