 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Uncertainty Estimation in Spiking Neural Networks via MC-dropout
Apr 20, 2023Spiking neural networks (SNNs) have gained attention as models of sparse and event-driven communication of biological neurons, and as such have shown increasing promise for energy-efficient applications in neuromorphic hardware. As with classical artificial neural networks (ANNs), predictive uncertainties are important for decision making in high-stakes applications, such as autonomous vehicles, medical diagnosis, and high frequency trading. Yet, discussion of uncertainty estimation in SNNs is limited, and approaches for uncertainty estimation in artificial neural networks (ANNs) are not directly applicable to SNNs. Here, we propose an efficient Monte Carlo(MC)-dropout based approach for uncertainty estimation in SNNs. Our approach exploits the time-step mechanism of SNNs to enable MC-dropout in a computationally efficient manner, without introducing significant overheads during training and inference while demonstrating high accuracy and uncertainty quality.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Conditional Time Series Forecasting with Convolutional Neural Networks
Sep 17, 2018

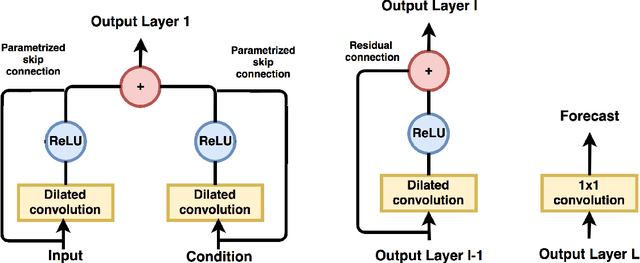
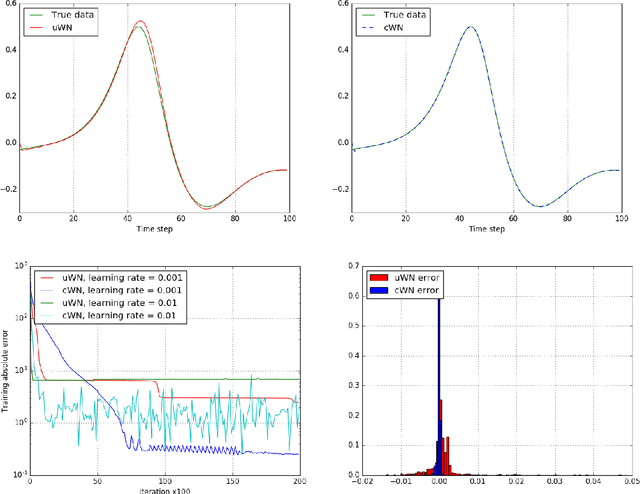
We present a method for conditional time series forecasting based on an adaptation of the recent deep convolutional WaveNet architecture. The proposed network contains stacks of dilated convolutions that allow it to access a broad range of history when forecasting, a ReLU activation function and conditioning is performed by applying multiple convolutional filters in parallel to separate time series which allows for the fast processing of data and the exploitation of the correlation structure between the multivariate time series. We test and analyze the performance of the convolutional network both unconditionally as well as conditionally for financial time series forecasting using the S&P500, the volatility index, the CBOE interest rate and several exchange rates and extensively compare it to the performance of the well-known autoregressive model and a long-short term memory network. We show that a convolutional network is well-suited for regression-type problems and is able to effectively learn dependencies in and between the series without the need for long historical time series, is a time-efficient and easy to implement alternative to recurrent-type networks and tends to outperform linear and recurrent models.
An image representation based convolutional network for DNA classification
Jun 13, 2018
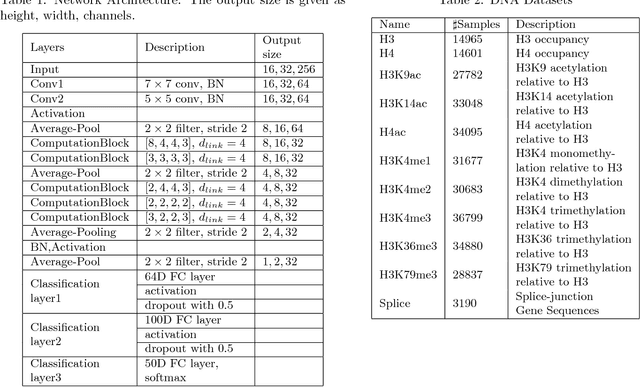
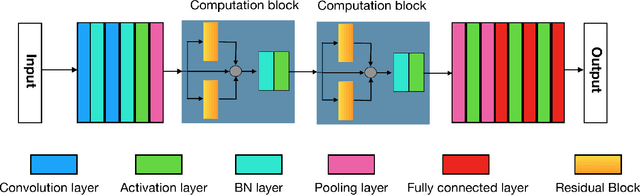
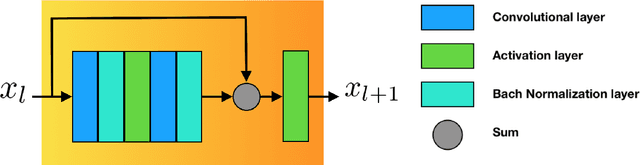
The folding structure of the DNA molecule combined with helper molecules, also referred to as the chromatin, is highly relevant for the functional properties of DNA. The chromatin structure is largely determined by the underlying primary DNA sequence, though the interaction is not yet fully understood. In this paper we develop a convolutional neural network that takes an image-representation of primary DNA sequence as its input, and predicts key determinants of chromatin structure. The method is developed such that it is capable of detecting interactions between distal elements in the DNA sequence, which are known to be highly relevant. Our experiments show that the method outperforms several existing methods both in terms of prediction accuracy and training time.
Efficient Computation in Adaptive Artificial Spiking Neural Networks
Oct 13, 2017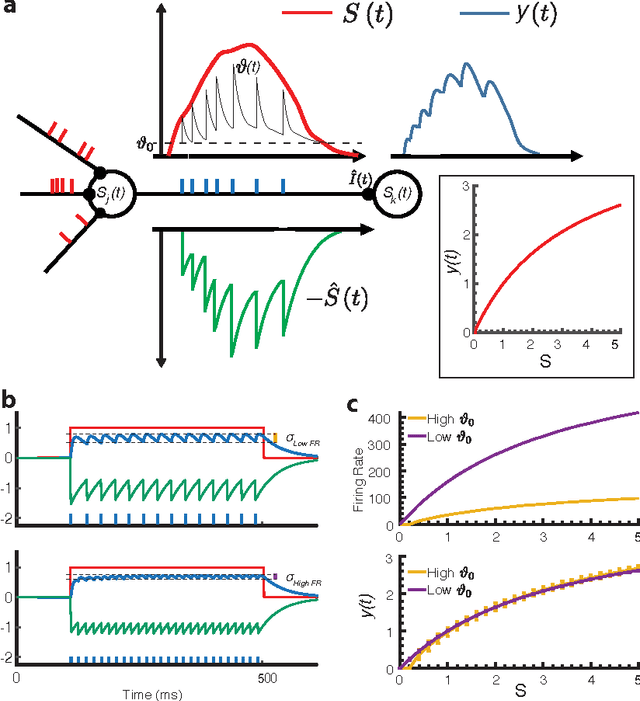
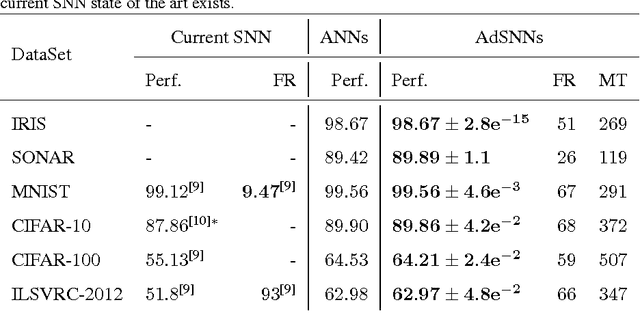


Artificial Neural Networks (ANNs) are bio-inspired models of neural computation that have proven highly effective. Still, ANNs lack a natural notion of time, and neural units in ANNs exchange analog values in a frame-based manner, a computationally and energetically inefficient form of communication. This contrasts sharply with biological neurons that communicate sparingly and efficiently using binary spikes. While artificial Spiking Neural Networks (SNNs) can be constructed by replacing the units of an ANN with spiking neurons, the current performance is far from that of deep ANNs on hard benchmarks and these SNNs use much higher firing rates compared to their biological counterparts, limiting their efficiency. Here we show how spiking neurons that employ an efficient form of neural coding can be used to construct SNNs that match high-performance ANNs and exceed state-of-the-art in SNNs on important benchmarks, while requiring much lower average firing rates. For this, we use spike-time coding based on the firing rate limiting adaptation phenomenon observed in biological spiking neurons. This phenomenon can be captured in adapting spiking neuron models, for which we derive the effective transfer function. Neural units in ANNs trained with this transfer function can be substituted directly with adaptive spiking neurons, and the resulting Adaptive SNNs (AdSNNs) can carry out inference in deep neural networks using up to an order of magnitude fewer spikes compared to previous SNNs. Adaptive spike-time coding additionally allows for the dynamic control of neural coding precision: we show how a simple model of arousal in AdSNNs further halves the average required firing rate and this notion naturally extends to other forms of attention. AdSNNs thus hold promise as a novel and efficient model for neural computation that naturally fits to temporally continuous and asynchronous applications.
Efficient forward propagation of time-sequences in convolutional neural networks using Deep Shifting
Mar 11, 2016


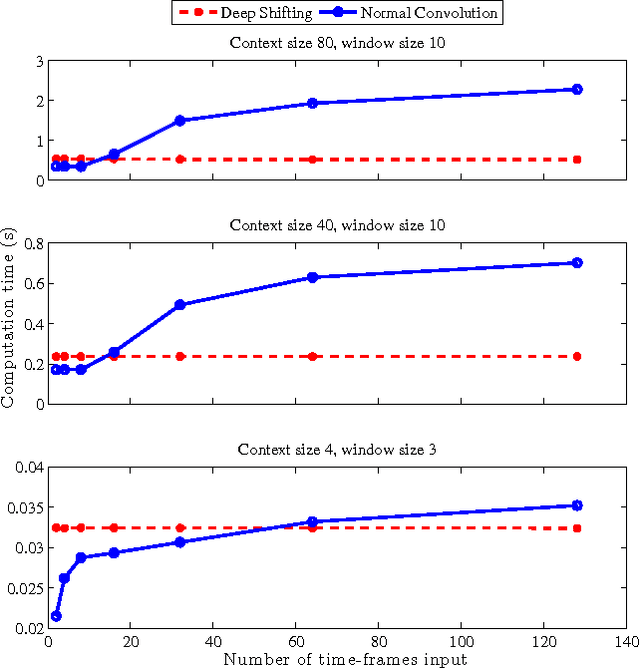
When a Convolutional Neural Network is used for on-the-fly evaluation of continuously updating time-sequences, many redundant convolution operations are performed. We propose the method of Deep Shifting, which remembers previously calculated results of convolution operations in order to minimize the number of calculations. The reduction in complexity is at least a constant and in the best case quadratic. We demonstrate that this method does indeed save significant computation time in a practical implementation, especially when the networks receives a large number of time-frames.