 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025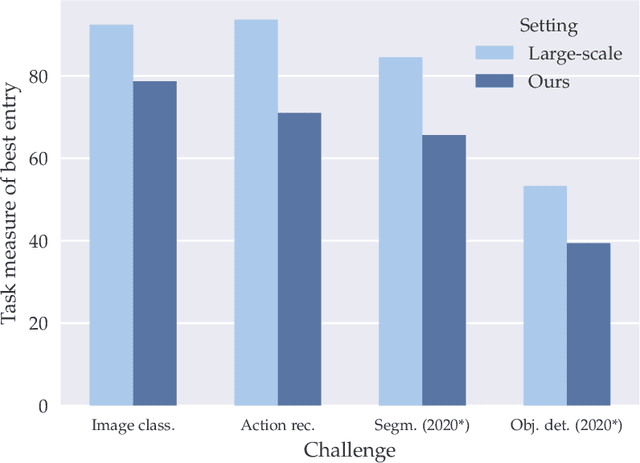

Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
VIPriors 4: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jun 26, 2024The fourth edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop features two data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate inductive biases to improve the data efficiency of deep learning models. Significant advancements are made compared to the provided baselines, where winning solutions surpass the baselines by a considerable margin in both tasks. As in previous editions, these achievements are primarily attributed to heavy use of data augmentation policies and large model ensembles, though novel prior-based methods seem to contribute more to successful solutions compared to last year. This report highlights the key aspects of the challenges and their outcomes.
VIPriors 3: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
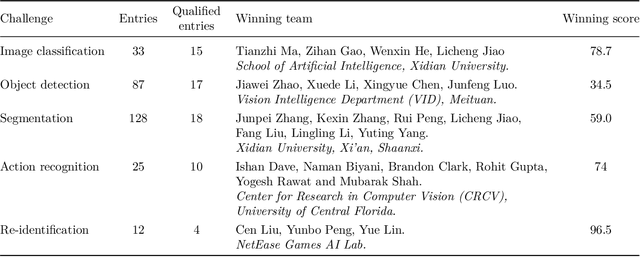
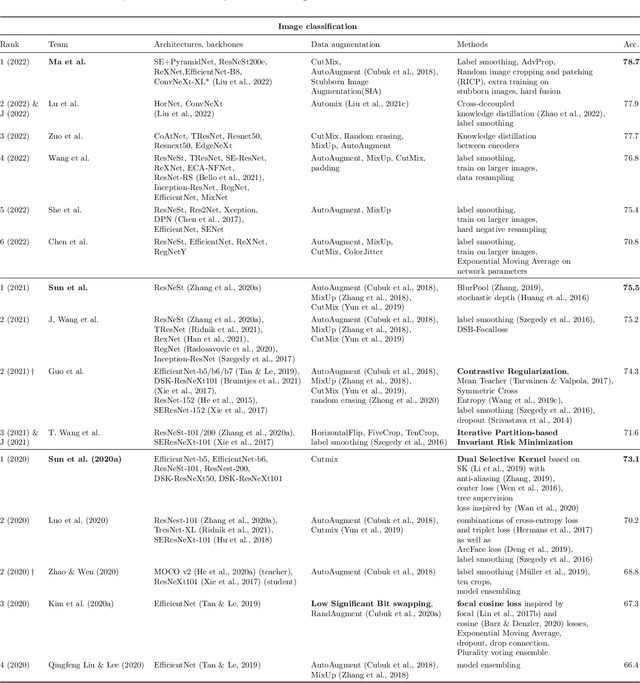
May 31, 2023The third edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop featured four data-impaired challenges, focusing on addressing the limitations of data availability in training deep learning models for computer vision tasks. The challenges comprised of four distinct data-impaired tasks, where participants were required to train models from scratch using a reduced number of training samples. The primary objective was to encourage novel approaches that incorporate relevant inductive biases to enhance the data efficiency of deep learning models. To foster creativity and exploration, participants were strictly prohibited from utilizing pre-trained checkpoints and other transfer learning techniques. Significant advancements were made compared to the provided baselines, where winning solutions surpassed the baselines by a considerable margin in all four tasks. These achievements were primarily attributed to the effective utilization of extensive data augmentation policies, model ensembling techniques, and the implementation of data-efficient training methods, including self-supervised representation learning. This report highlights the key aspects of the challenges and their outcomes.
DeepSportradar-v1: Computer Vision Dataset for Sports Understanding with High Quality Annotations
Aug 17, 2022
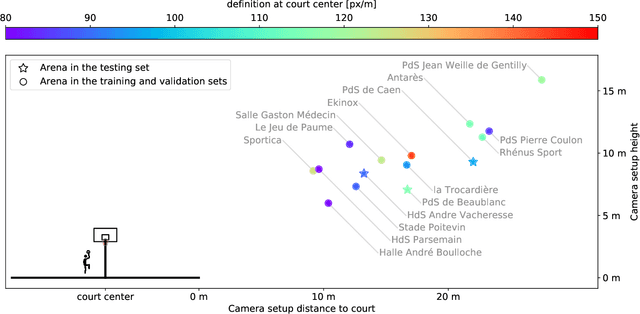


With the recent development of Deep Learning applied to Computer Vision, sport video understanding has gained a lot of attention, providing much richer information for both sport consumers and leagues. This paper introduces DeepSportradar-v1, a suite of computer vision tasks, datasets and benchmarks for automated sport understanding. The main purpose of this framework is to close the gap between academic research and real world settings. To this end, the datasets provide high-resolution raw images, camera parameters and high quality annotations. DeepSportradar currently supports four challenging tasks related to basketball: ball 3D localization, camera calibration, player instance segmentation and player re-identification. For each of the four tasks, a detailed description of the dataset, objective, performance metrics, and the proposed baseline method are provided. To encourage further research on advanced methods for sport understanding, a competition is organized as part of the MMSports workshop from the ACM Multimedia 2022 conference, where participants have to develop state-of-the-art methods to solve the above tasks. The four datasets, development kits and baselines are publicly available.
VIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jan 21, 2022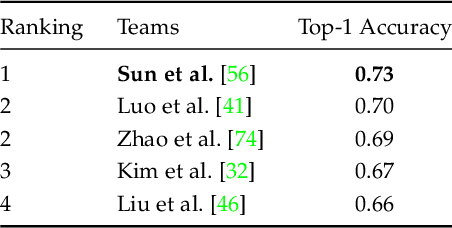

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
Seeking Quality Diversity in Evolutionary Co-design of Morphology and Control of Soft Tensegrity Modular Robots
Apr 25, 2021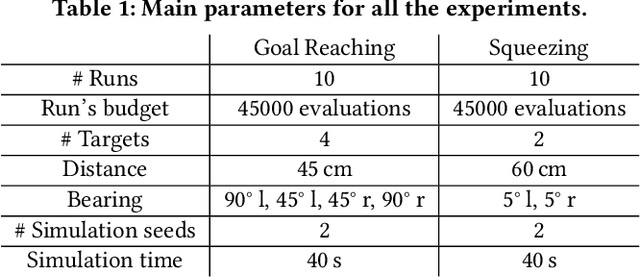
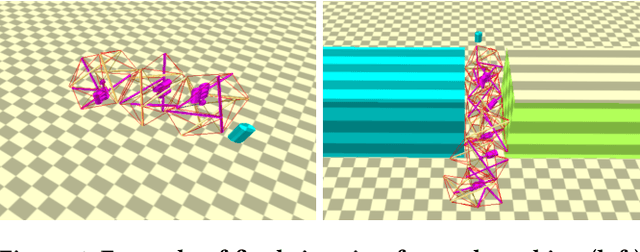
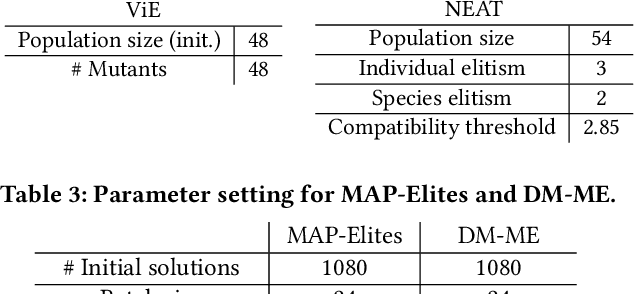
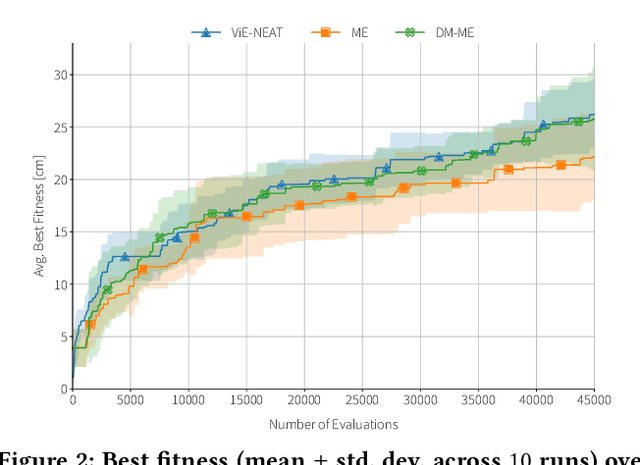
Designing optimal soft modular robots is difficult, due to non-trivial interactions between morphology and controller. Evolutionary algorithms (EAs), combined with physical simulators, represent a valid tool to overcome this issue. In this work, we investigate algorithmic solutions to improve the Quality Diversity of co-evolved designs of Tensegrity Soft Modular Robots (TSMRs) for two robotic tasks, namely goal reaching and squeezing trough a narrow passage. To this aim, we use three different EAs, i.e., MAP-Elites and two custom algorithms: one based on Viability Evolution (ViE) and NEAT (ViE-NEAT), the other named Double Map MAP-Elites (DM-ME) and devised to seek diversity while co-evolving robot morphologies and neural network (NN)-based controllers. In detail, DM-ME extends MAP-Elites in that it uses two distinct feature maps, referring to morphologies and controllers respectively, and integrates a mechanism to automatically define the NN-related feature descriptor. Considering the fitness, in the goal-reaching task ViE-NEAT outperforms MAP-Elites and results equivalent to DM-ME. Instead, when considering diversity in terms of "illumination" of the feature space, DM-ME outperforms the other two algorithms on both tasks, providing a richer pool of possible robotic designs, whereas ViE-NEAT shows comparable performance to MAP-Elites on goal reaching, although it does not exploit any map.
An image representation based convolutional network for DNA classification
Jun 13, 2018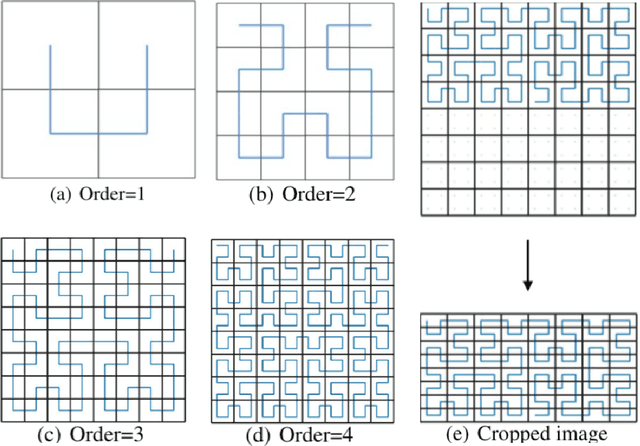
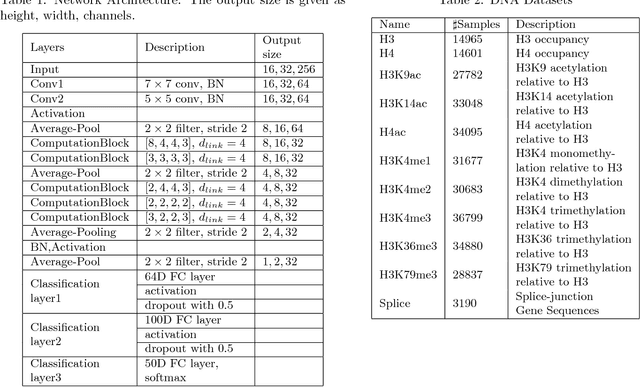
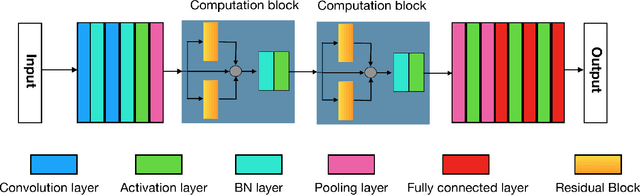
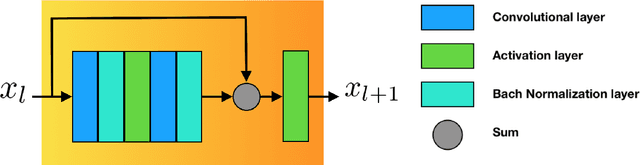
The folding structure of the DNA molecule combined with helper molecules, also referred to as the chromatin, is highly relevant for the functional properties of DNA. The chromatin structure is largely determined by the underlying primary DNA sequence, though the interaction is not yet fully understood. In this paper we develop a convolutional neural network that takes an image-representation of primary DNA sequence as its input, and predicts key determinants of chromatin structure. The method is developed such that it is capable of detecting interactions between distal elements in the DNA sequence, which are known to be highly relevant. Our experiments show that the method outperforms several existing methods both in terms of prediction accuracy and training time.
Efficient Computation in Adaptive Artificial Spiking Neural Networks
Oct 13, 2017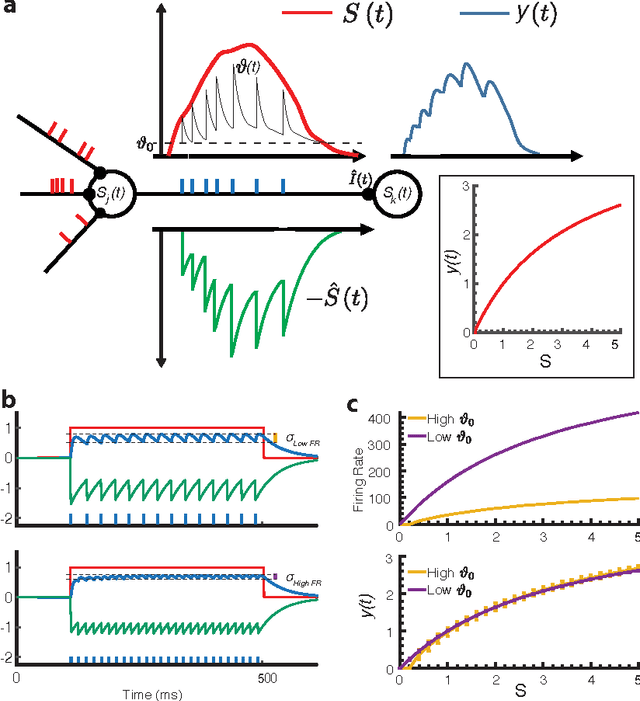
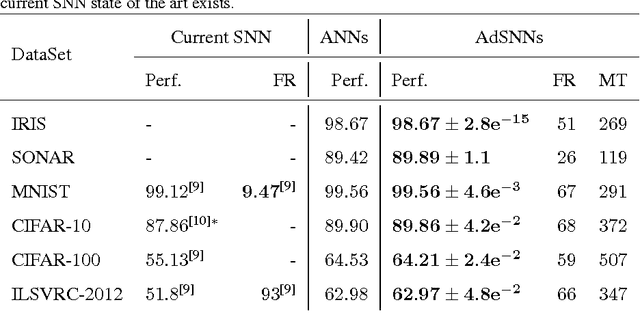


Artificial Neural Networks (ANNs) are bio-inspired models of neural computation that have proven highly effective. Still, ANNs lack a natural notion of time, and neural units in ANNs exchange analog values in a frame-based manner, a computationally and energetically inefficient form of communication. This contrasts sharply with biological neurons that communicate sparingly and efficiently using binary spikes. While artificial Spiking Neural Networks (SNNs) can be constructed by replacing the units of an ANN with spiking neurons, the current performance is far from that of deep ANNs on hard benchmarks and these SNNs use much higher firing rates compared to their biological counterparts, limiting their efficiency. Here we show how spiking neurons that employ an efficient form of neural coding can be used to construct SNNs that match high-performance ANNs and exceed state-of-the-art in SNNs on important benchmarks, while requiring much lower average firing rates. For this, we use spike-time coding based on the firing rate limiting adaptation phenomenon observed in biological spiking neurons. This phenomenon can be captured in adapting spiking neuron models, for which we derive the effective transfer function. Neural units in ANNs trained with this transfer function can be substituted directly with adaptive spiking neurons, and the resulting Adaptive SNNs (AdSNNs) can carry out inference in deep neural networks using up to an order of magnitude fewer spikes compared to previous SNNs. Adaptive spike-time coding additionally allows for the dynamic control of neural coding precision: we show how a simple model of arousal in AdSNNs further halves the average required firing rate and this notion naturally extends to other forms of attention. AdSNNs thus hold promise as a novel and efficient model for neural computation that naturally fits to temporally continuous and asynchronous applications.
Fast and Efficient Asynchronous Neural Computation with Adapting Spiking Neural Networks
Sep 07, 2016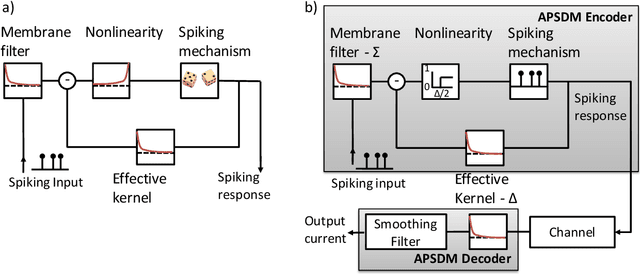
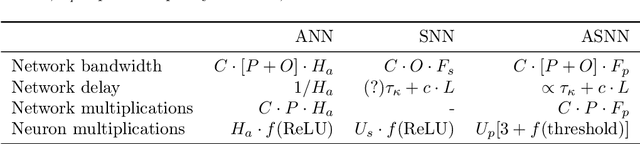
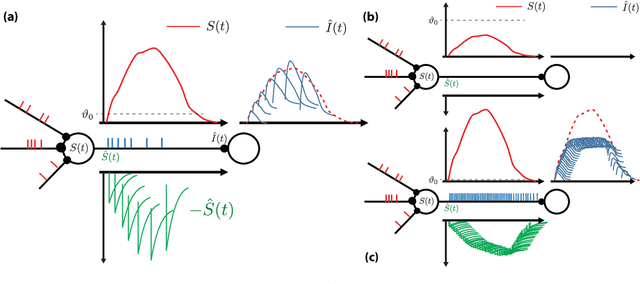
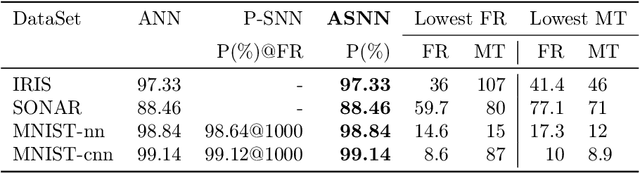
Biological neurons communicate with a sparing exchange of pulses - spikes. It is an open question how real spiking neurons produce the kind of powerful neural computation that is possible with deep artificial neural networks, using only so very few spikes to communicate. Building on recent insights in neuroscience, we present an Adapting Spiking Neural Network (ASNN) based on adaptive spiking neurons. These spiking neurons efficiently encode information in spike-trains using a form of Asynchronous Pulsed Sigma-Delta coding while homeostatically optimizing their firing rate. In the proposed paradigm of spiking neuron computation, neural adaptation is tightly coupled to synaptic plasticity, to ensure that downstream neurons can correctly decode upstream spiking neurons. We show that this type of network is inherently able to carry out asynchronous and event-driven neural computation, while performing identical to corresponding artificial neural networks (ANNs). In particular, we show that these adaptive spiking neurons can be drop in replacements for ReLU neurons in standard feedforward ANNs comprised of such units. We demonstrate that this can also be successfully applied to a ReLU based deep convolutional neural network for classifying the MNIST dataset. The ASNN thus outperforms current Spiking Neural Networks (SNNs) implementations, while responding (up to) an order of magnitude faster and using an order of magnitude fewer spikes. Additionally, in a streaming setting where frames are continuously classified, we show that the ASNN requires substantially fewer network updates as compared to the corresponding ANN.