 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025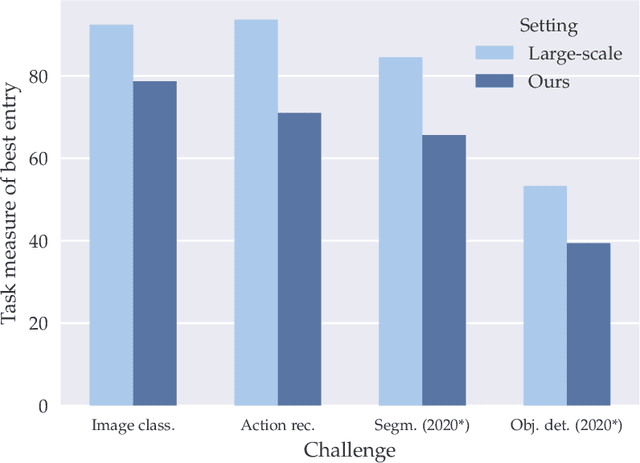
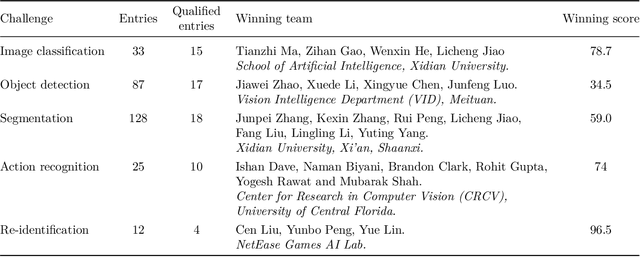

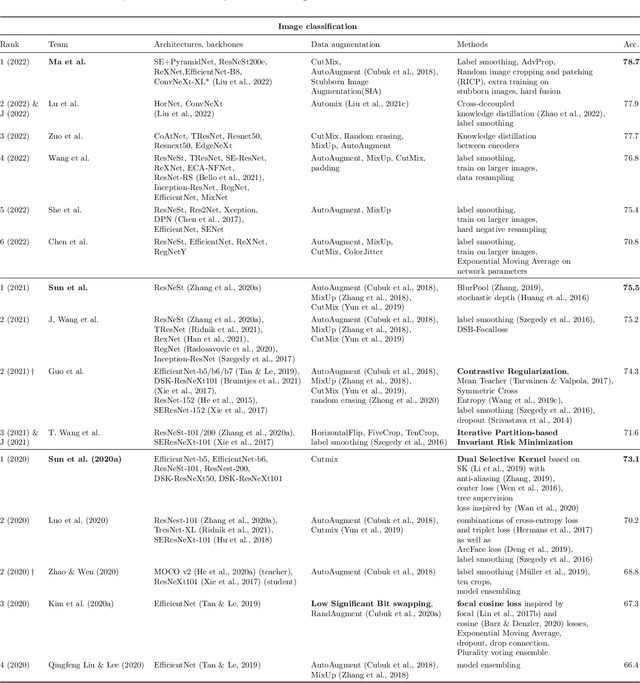
Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
VIPriors 4: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jun 26, 2024The fourth edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop features two data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate inductive biases to improve the data efficiency of deep learning models. Significant advancements are made compared to the provided baselines, where winning solutions surpass the baselines by a considerable margin in both tasks. As in previous editions, these achievements are primarily attributed to heavy use of data augmentation policies and large model ensembles, though novel prior-based methods seem to contribute more to successful solutions compared to last year. This report highlights the key aspects of the challenges and their outcomes.
VIPriors 3: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
May 31, 2023The third edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop featured four data-impaired challenges, focusing on addressing the limitations of data availability in training deep learning models for computer vision tasks. The challenges comprised of four distinct data-impaired tasks, where participants were required to train models from scratch using a reduced number of training samples. The primary objective was to encourage novel approaches that incorporate relevant inductive biases to enhance the data efficiency of deep learning models. To foster creativity and exploration, participants were strictly prohibited from utilizing pre-trained checkpoints and other transfer learning techniques. Significant advancements were made compared to the provided baselines, where winning solutions surpassed the baselines by a considerable margin in all four tasks. These achievements were primarily attributed to the effective utilization of extensive data augmentation policies, model ensembling techniques, and the implementation of data-efficient training methods, including self-supervised representation learning. This report highlights the key aspects of the challenges and their outcomes.
Evaluating Context for Deep Object Detectors
May 05, 2022



Which object detector is suitable for your context sensitive task? Deep object detectors exploit scene context for recognition differently. In this paper, we group object detectors into 3 categories in terms of context use: no context by cropping the input (RCNN), partial context by cropping the featuremap (two-stage methods) and full context without any cropping (single-stage methods). We systematically evaluate the effect of context for each deep detector category. We create a fully controlled dataset for varying context and investigate the context for deep detectors. We also evaluate gradually removing the background context and the foreground object on MS COCO. We demonstrate that single-stage and two-stage object detectors can and will use the context by virtue of their large receptive field. Thus, choosing the best object detector may depend on the application context.
VIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jan 21, 2022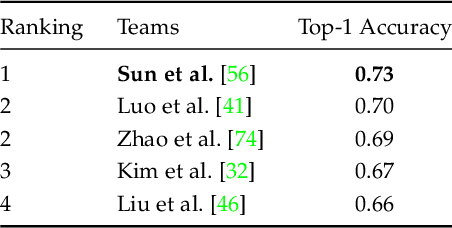
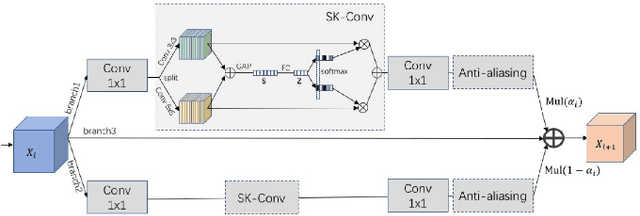
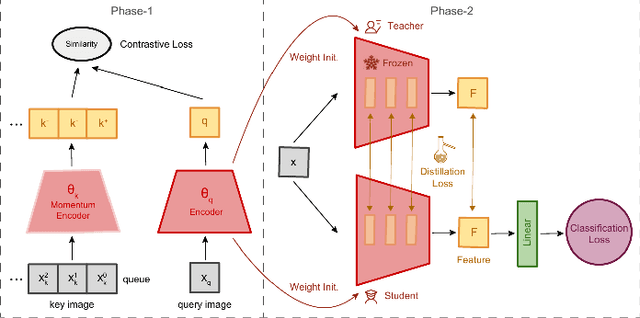

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
Hallucination In Object Detection -- A Study In Visual Part Verification
Jun 04, 2021



We show that object detectors can hallucinate and detect missing objects; potentially even accurately localized at their expected, but non-existing, position. This is particularly problematic for applications that rely on visual part verification: detecting if an object part is present or absent. We show how popular object detectors hallucinate objects in a visual part verification task and introduce the first visual part verification dataset: DelftBikes, which has 10,000 bike photographs, with 22 densely annotated parts per image, where some parts may be missing. We explicitly annotated an extra object state label for each part to reflect if a part is missing or intact. We propose to evaluate visual part verification by relying on recall and compare popular object detectors on DelftBikes.
VIPriors 1: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Mar 05, 2021We present the first edition of "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges. We offer four data-impaired challenges, where models are trained from scratch, and we reduce the number of training samples to a fraction of the full set. Furthermore, to encourage data efficient solutions, we prohibited the use of pre-trained models and other transfer learning techniques. The majority of top ranking solutions make heavy use of data augmentation, model ensembling, and novel and efficient network architectures to achieve significant performance increases compared to the provided baselines.
t-EVA: Time-Efficient t-SNE Video Annotation
Nov 26, 2020



Video understanding has received more attention in the past few years due to the availability of several large-scale video datasets. However, annotating large-scale video datasets are cost-intensive. In this work, we propose a time-efficient video annotation method using spatio-temporal feature similarity and t-SNE dimensionality reduction to speed up the annotation process massively. Placing the same actions from different videos near each other in the two-dimensional space based on feature similarity helps the annotator to group-label video clips. We evaluate our method on two subsets of the ActivityNet (v1.3) and a subset of the Sports-1M dataset. We show that t-EVA can outperform other video annotation tools while maintaining test accuracy on video classification.
Tilting at windmills: Data augmentation for deep pose estimation does not help with occlusions
Oct 20, 2020
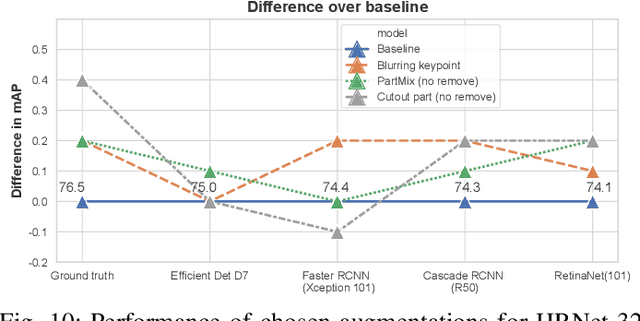
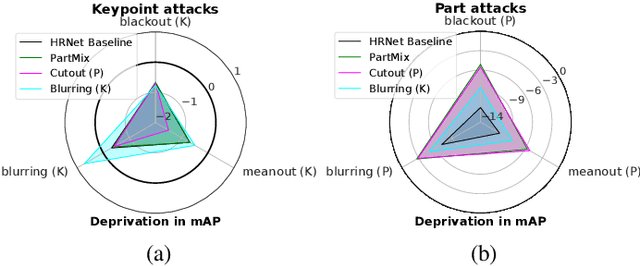
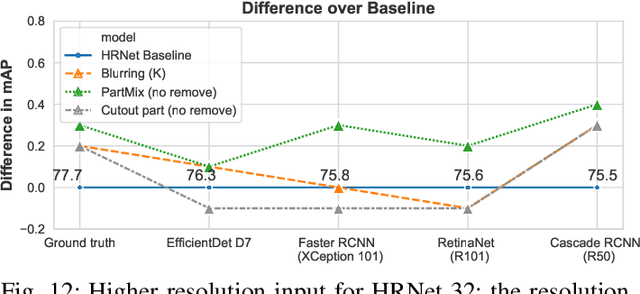
Occlusion degrades the performance of human pose estimation. In this paper, we introduce targeted keypoint and body part occlusion attacks. The effects of the attacks are systematically analyzed on the best performing methods. In addition, we propose occlusion specific data augmentation techniques against keypoint and part attacks. Our extensive experiments show that human pose estimation methods are not robust to occlusion and data augmentation does not solve the occlusion problems.
On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location
Mar 16, 2020

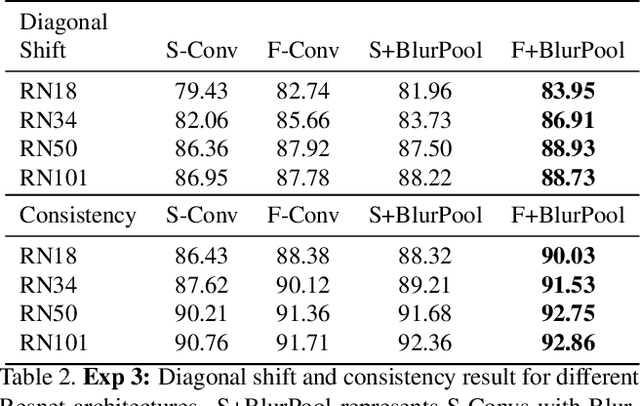
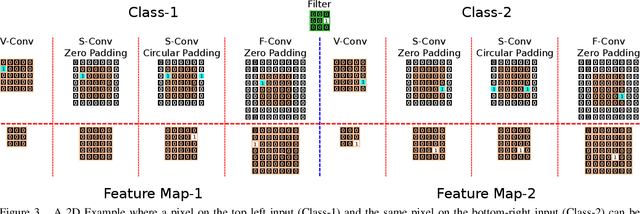
In this paper we challenge the common assumption that convolutional layers in modern CNNs are translation invariant. We show that CNNs can and will exploit the absolute spatial location by learning filters that respond exclusively to particular absolute locations by exploiting image boundary effects. Because modern CNNs filters have a huge receptive field, these boundary effects operate even far from the image boundary, allowing the network to exploit absolute spatial location all over the image. We give a simple solution to remove spatial location encoding which improves translation invariance and thus gives a stronger visual inductive bias which particularly benefits small data sets. We broadly demonstrate these benefits on several architectures and various applications such as image classification, patch matching, and two video classification datasets.