 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPriors 4: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jun 26, 2024The fourth edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop features two data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate inductive biases to improve the data efficiency of deep learning models. Significant advancements are made compared to the provided baselines, where winning solutions surpass the baselines by a considerable margin in both tasks. As in previous editions, these achievements are primarily attributed to heavy use of data augmentation policies and large model ensembles, though novel prior-based methods seem to contribute more to successful solutions compared to last year. This report highlights the key aspects of the challenges and their outcomes.
VIPriors 3: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
May 31, 2023The third edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop featured four data-impaired challenges, focusing on addressing the limitations of data availability in training deep learning models for computer vision tasks. The challenges comprised of four distinct data-impaired tasks, where participants were required to train models from scratch using a reduced number of training samples. The primary objective was to encourage novel approaches that incorporate relevant inductive biases to enhance the data efficiency of deep learning models. To foster creativity and exploration, participants were strictly prohibited from utilizing pre-trained checkpoints and other transfer learning techniques. Significant advancements were made compared to the provided baselines, where winning solutions surpassed the baselines by a considerable margin in all four tasks. These achievements were primarily attributed to the effective utilization of extensive data augmentation policies, model ensembling techniques, and the implementation of data-efficient training methods, including self-supervised representation learning. This report highlights the key aspects of the challenges and their outcomes.
VIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jan 21, 2022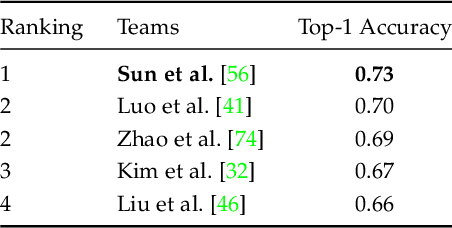
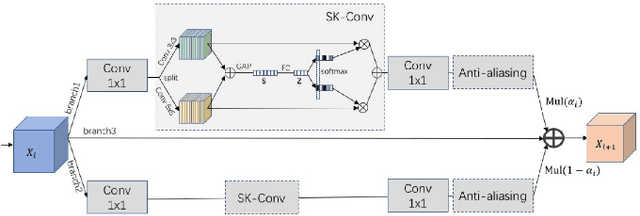
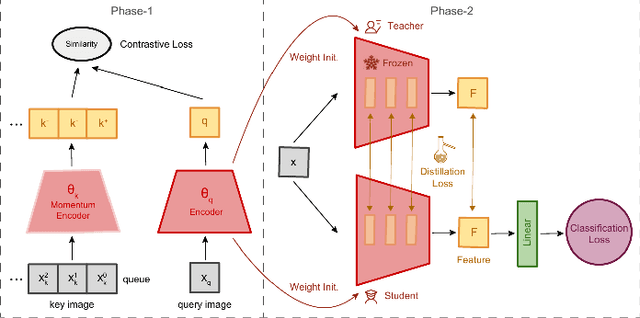

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
VIPriors 1: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Mar 05, 2021We present the first edition of "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges. We offer four data-impaired challenges, where models are trained from scratch, and we reduce the number of training samples to a fraction of the full set. Furthermore, to encourage data efficient solutions, we prohibited the use of pre-trained models and other transfer learning techniques. The majority of top ranking solutions make heavy use of data augmentation, model ensembling, and novel and efficient network architectures to achieve significant performance increases compared to the provided baselines.
Rethinking Online Action Detection in Untrimmed Videos: A Novel Online Evaluation Protocol
Mar 26, 2020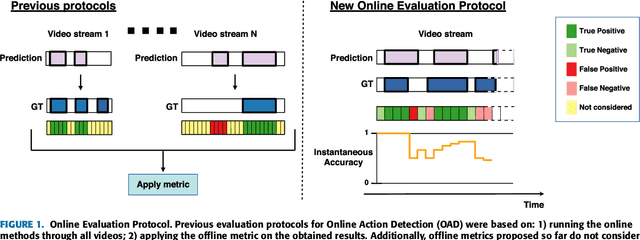
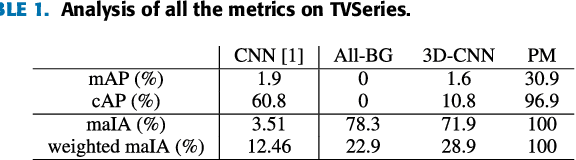
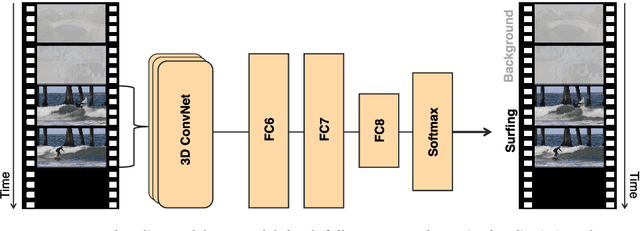
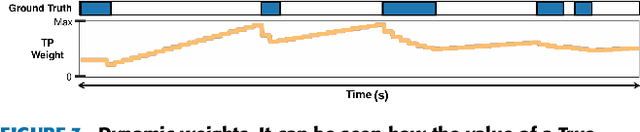
The Online Action Detection (OAD) problem needs to be revisited. Unlike traditional offline action detection approaches, where the evaluation metrics are clear and well established, in the OAD setting we find very few works and no consensus on the evaluation protocols to be used. In this work we propose to rethink the OAD scenario, clearly defining the problem itself and the main characteristics that the models which are considered online must comply with. We also introduce a novel metric: the Instantaneous Accuracy ($IA$). This new metric exhibits an \emph{online} nature and solves most of the limitations of the previous metrics. We conduct a thorough experimental evaluation on 3 challenging datasets, where the performance of various baseline methods is compared to that of the state-of-the-art. Our results confirm the problems of the previous evaluation protocols, and suggest that an IA-based protocol is more adequate to the online scenario. The baselines models and a development kit with the novel evaluation protocol are publicly available: https://github.com/gramuah/ia.
The Instantaneous Accuracy: a Novel Metric for the Problem of Online Human Behaviour Recognition in Untrimmed Videos
Mar 25, 2020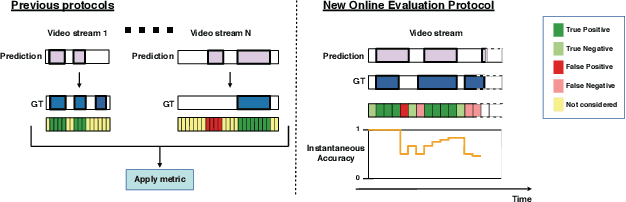
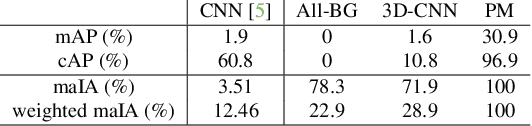
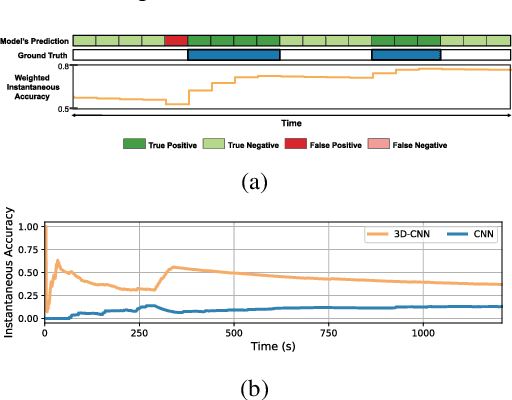
The problem of Online Human Behaviour Recognition in untrimmed videos, aka Online Action Detection (OAD), needs to be revisited. Unlike traditional offline action detection approaches, where the evaluation metrics are clear and well established, in the OAD setting we find few works and no consensus on the evaluation protocols to be used. In this paper we introduce a novel online metric, the Instantaneous Accuracy ($IA$), that exhibits an \emph{online} nature, solving most of the limitations of the previous (offline) metrics. We conduct a thorough experimental evaluation on TVSeries dataset, comparing the performance of various baseline methods to the state of the art. Our results confirm the problems of previous evaluation protocols, and suggest that an IA-based protocol is more adequate to the online scenario for human behaviour understanding. Code of the metric available https://github.com/gramuah/ia