 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Every Event Count: Balancing Data Efficiency and Accuracy in Event Camera Subsampling
May 27, 2025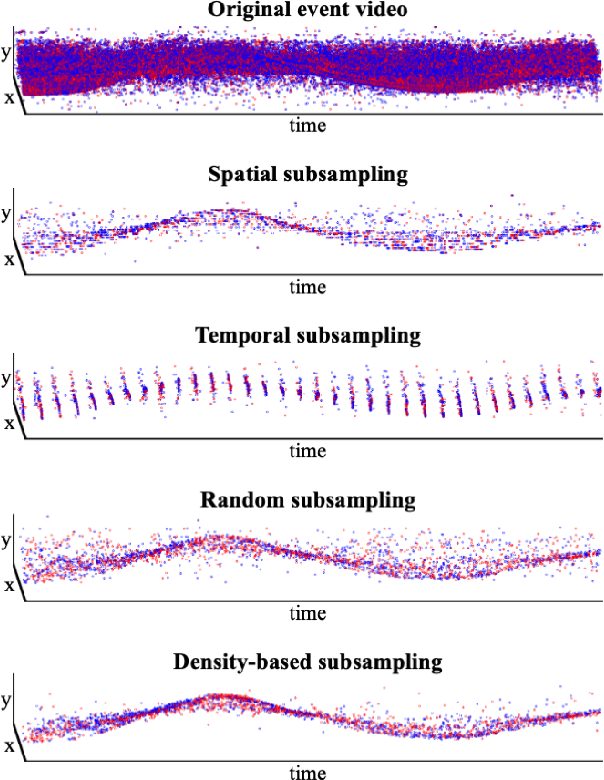
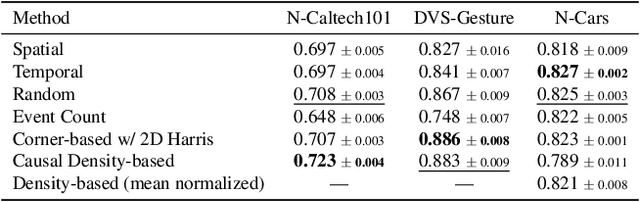
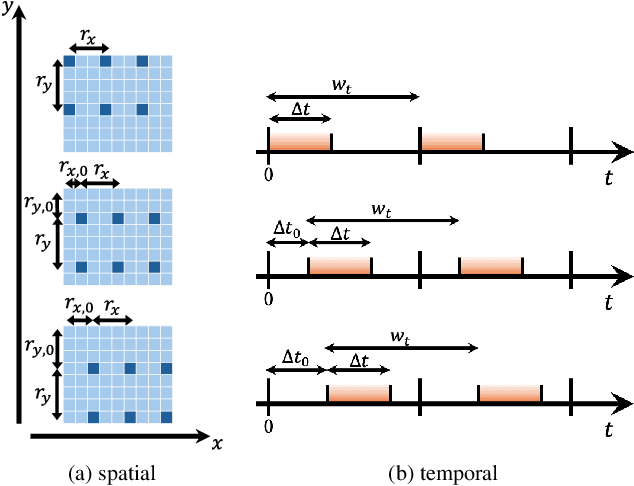
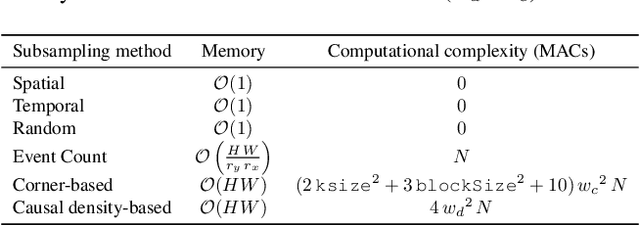
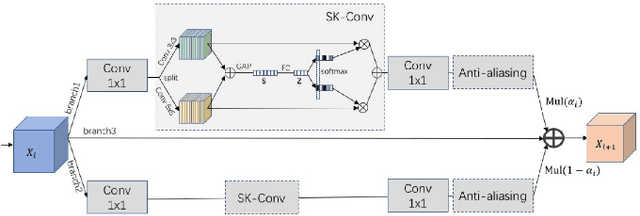
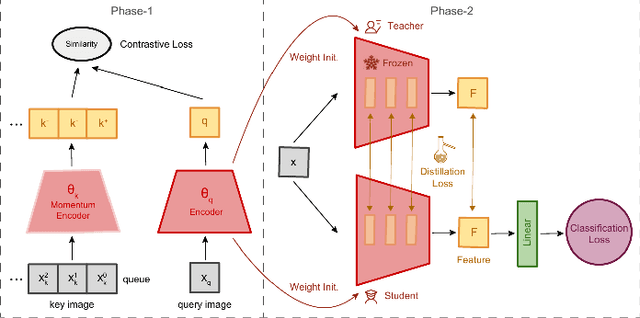
Event cameras offer high temporal resolution and power efficiency, making them well-suited for edge AI applications. However, their high event rates present challenges for data transmission and processing. Subsampling methods provide a practical solution, but their effect on downstream visual tasks remains underexplored. In this work, we systematically evaluate six hardware-friendly subsampling methods using convolutional neural networks for event video classification on various benchmark datasets. We hypothesize that events from high-density regions carry more task-relevant information and are therefore better suited for subsampling. To test this, we introduce a simple causal density-based subsampling method, demonstrating improved classification accuracy in sparse regimes. Our analysis further highlights key factors affecting subsampling performance, including sensitivity to hyperparameters and failure cases in scenarios with large event count variance. These findings provide insights for utilization of hardware-efficient subsampling strategies that balance data efficiency and task accuracy. The code for this paper will be released at: https://github.com/hesamaraghi/event-camera-subsampling-methods.
Pushing the boundaries of event subsampling in event-based video classification using CNNs
Sep 13, 2024



Event cameras offer low-power visual sensing capabilities ideal for edge-device applications. However, their high event rate, driven by high temporal details, can be restrictive in terms of bandwidth and computational resources. In edge AI applications, determining the minimum amount of events for specific tasks can allow reducing the event rate to improve bandwidth, memory, and processing efficiency. In this paper, we study the effect of event subsampling on the accuracy of event data classification using convolutional neural network (CNN) models. Surprisingly, across various datasets, the number of events per video can be reduced by an order of magnitude with little drop in accuracy, revealing the extent to which we can push the boundaries in accuracy vs. event rate trade-off. Additionally, we also find that lower classification accuracy in high subsampling rates is not solely attributable to information loss due to the subsampling of the events, but that the training of CNNs can be challenging in highly subsampled scenarios, where the sensitivity to hyperparameters increases. We quantify training instability across multiple event-based classification datasets using a novel metric for evaluating the hyperparameter sensitivity of CNNs in different subsampling settings. Finally, we analyze the weight gradients of the network to gain insight into this instability.
VIPriors 4: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jun 26, 2024The fourth edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop features two data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate inductive biases to improve the data efficiency of deep learning models. Significant advancements are made compared to the provided baselines, where winning solutions surpass the baselines by a considerable margin in both tasks. As in previous editions, these achievements are primarily attributed to heavy use of data augmentation policies and large model ensembles, though novel prior-based methods seem to contribute more to successful solutions compared to last year. This report highlights the key aspects of the challenges and their outcomes.
Deep Continuous Networks
Feb 02, 2024CNNs and computational models of biological vision share some fundamental principles, which opened new avenues of research. However, fruitful cross-field research is hampered by conventional CNN architectures being based on spatially and depthwise discrete representations, which cannot accommodate certain aspects of biological complexity such as continuously varying receptive field sizes and dynamics of neuronal responses. Here we propose deep continuous networks (DCNs), which combine spatially continuous filters, with the continuous depth framework of neural ODEs. This allows us to learn the spatial support of the filters during training, as well as model the continuous evolution of feature maps, linking DCNs closely to biological models. We show that DCNs are versatile and highly applicable to standard image classification and reconstruction problems, where they improve parameter and data efficiency, and allow for meta-parametrization. We illustrate the biological plausibility of the scale distributions learned by DCNs and explore their performance in a neuroscientifically inspired pattern completion task. Finally, we investigate an efficient implementation of DCNs by changing input contrast.
* Presented at ICML 2021
VIPriors 3: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
May 31, 2023The third edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop featured four data-impaired challenges, focusing on addressing the limitations of data availability in training deep learning models for computer vision tasks. The challenges comprised of four distinct data-impaired tasks, where participants were required to train models from scratch using a reduced number of training samples. The primary objective was to encourage novel approaches that incorporate relevant inductive biases to enhance the data efficiency of deep learning models. To foster creativity and exploration, participants were strictly prohibited from utilizing pre-trained checkpoints and other transfer learning techniques. Significant advancements were made compared to the provided baselines, where winning solutions surpassed the baselines by a considerable margin in all four tasks. These achievements were primarily attributed to the effective utilization of extensive data augmentation policies, model ensembling techniques, and the implementation of data-efficient training methods, including self-supervised representation learning. This report highlights the key aspects of the challenges and their outcomes.
Heart rate estimation in intense exercise videos
Aug 04, 2022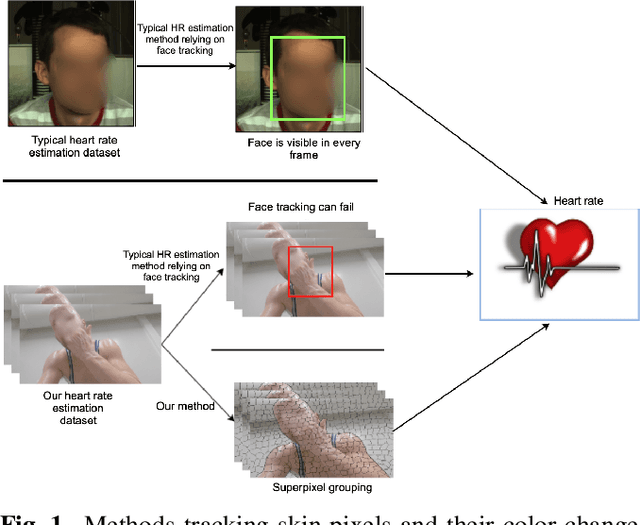

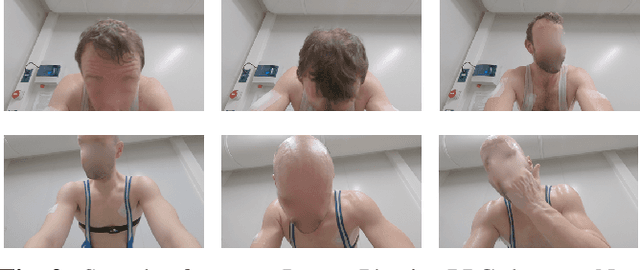
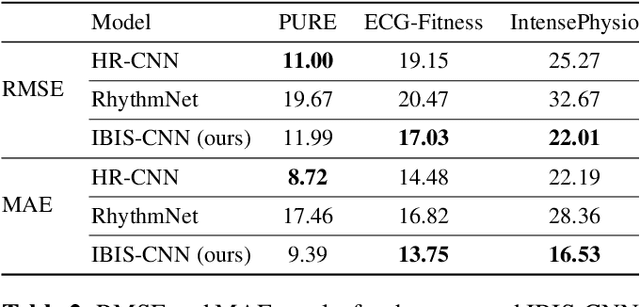
Estimating heart rate from video allows non-contact health monitoring with applications in patient care, human interaction, and sports. Existing work can robustly measure heart rate under some degree of motion by face tracking. However, this is not always possible in unconstrained settings, as the face might be occluded or even outside the camera. Here, we present IntensePhysio: a challenging video heart rate estimation dataset with realistic face occlusions, severe subject motion, and ample heart rate variation. To ensure heart rate variation in a realistic setting we record each subject for around 1-2 hours. The subject is exercising (at a moderate to high intensity) on a cycling ergometer with an attached video camera and is given no instructions regarding positioning or movement. We have 11 subjects, and approximately 20 total hours of video. We show that the existing remote photo-plethysmography methods have difficulty in estimating heart rate in this setting. In addition, we present IBIS-CNN, a new baseline using spatio-temporal superpixels, which improves on existing models by eliminating the need for a visible face/face tracking. We will make the code and data publically available soon.
VIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jan 21, 2022

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
Frequency learning for structured CNN filters with Gaussian fractional derivatives
Nov 12, 2021

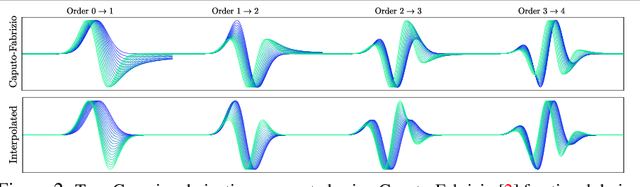

Frequency information lies at the base of discriminating between textures, and therefore between different objects. Classical CNN architectures limit the frequency learning through fixed filter sizes, and lack a way of explicitly controlling it. Here, we build on the structured receptive field filters with Gaussian derivative basis. Yet, rather than using predetermined derivative orders, which typically result in fixed frequency responses for the basis functions, we learn these. We show that by learning the order of the basis we can accurately learn the frequency of the filters, and hence adapt to the optimal frequencies for the underlying learning task. We investigate the well-founded mathematical formulation of fractional derivatives to adapt the filter frequencies during training. Our formulation leads to parameter savings and data efficiency when compared to the standard CNNs and the Gaussian derivative CNN filter networks that we build upon.
Resolution learning in deep convolutional networks using scale-space theory
Jun 30, 2021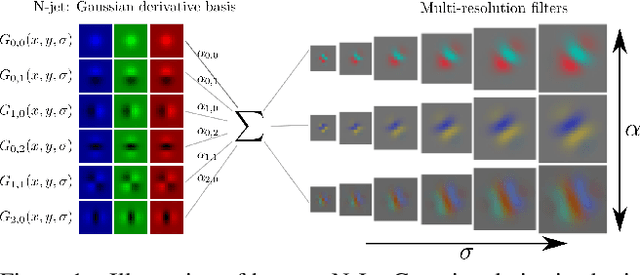


Resolution in deep convolutional neural networks (CNNs) is typically bounded by the receptive field size through filter sizes, and subsampling layers or strided convolutions on feature maps. The optimal resolution may vary significantly depending on the dataset. Modern CNNs hard-code their resolution hyper-parameters in the network architecture which makes tuning such hyper-parameters cumbersome. We propose to do away with hard-coded resolution hyper-parameters and aim to learn the appropriate resolution from data. We use scale-space theory to obtain a self-similar parametrization of filters and make use of the N-Jet: a truncated Taylor series to approximate a filter by a learned combination of Gaussian derivative filters. The parameter sigma of the Gaussian basis controls both the amount of detail the filter encodes and the spatial extent of the filter. Since sigma is a continuous parameter, we can optimize it with respect to the loss. The proposed N-Jet layer achieves comparable performance when used in state-of-the art architectures, while learning the correct resolution in each layer automatically. We evaluate our N-Jet layer on both classification and segmentation, and we show that learning sigma is especially beneficial for inputs at multiple sizes.
Spectral Leakage and Rethinking the Kernel Size in CNNs
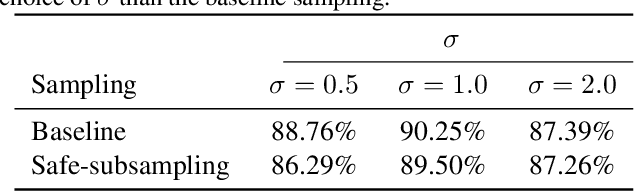
Jan 25, 2021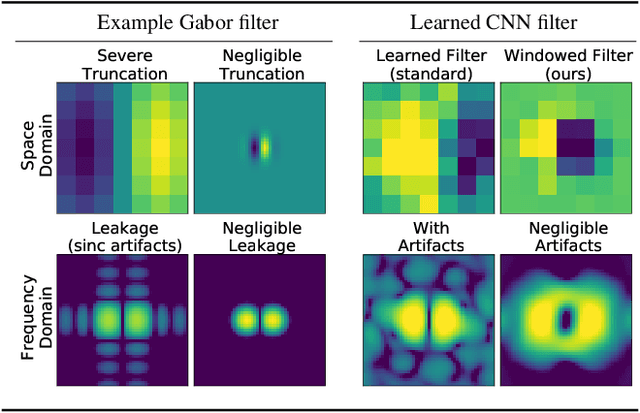
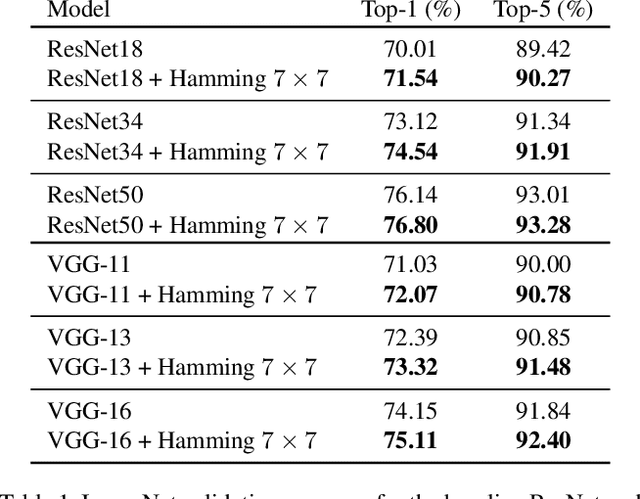
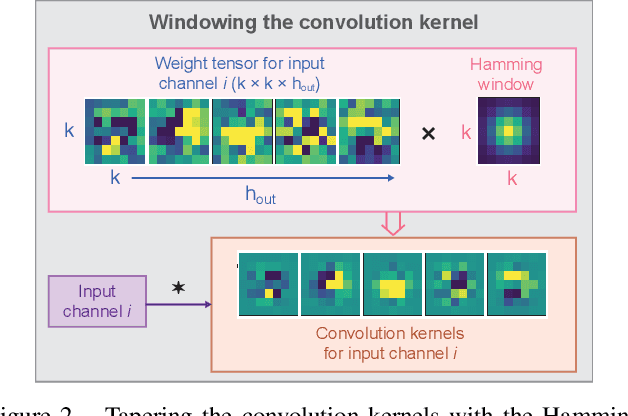
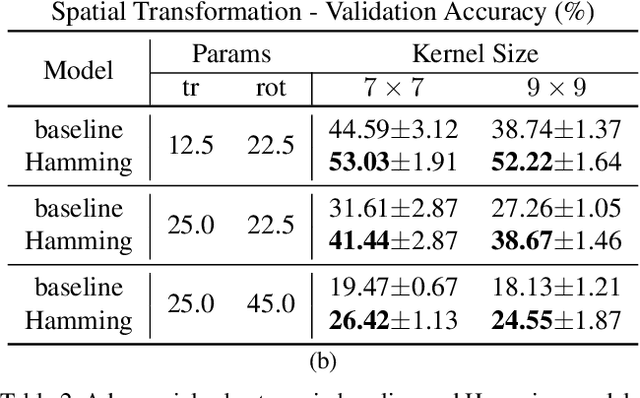
Convolutional layers in CNNs implement linear filters which decompose the input into different frequency bands. However, most modern architectures neglect standard principles of filter design when optimizing their model choices regarding the size and shape of the convolutional kernel. In this work, we consider the well-known problem of spectral leakage caused by windowing artifacts in filtering operations in the context of CNNs. We show that the small size of CNN kernels make them susceptible to spectral leakage, which may induce performance-degrading artifacts. To address this issue, we propose the use of larger kernel sizes along with the Hamming window function to alleviate leakage in CNN architectures. We demonstrate improved classification accuracy over baselines with conventional $3\times 3$ kernels, on multiple benchmark datasets including Fashion-MNIST, CIFAR-10, CIFAR-100 and ImageNet, via the simple use of a standard window function in convolutional layers. Finally, we show that CNNs employing the Hamming window display increased robustness against certain types of adversarial attacks.