 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025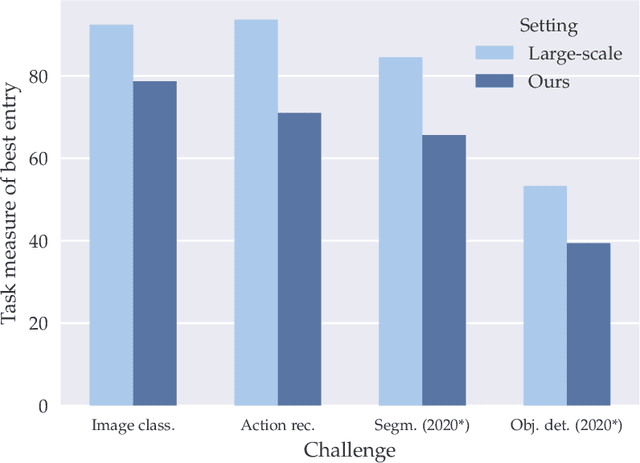
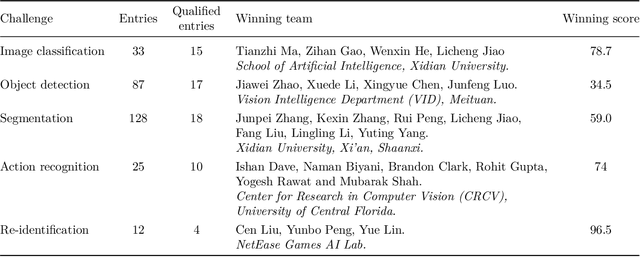

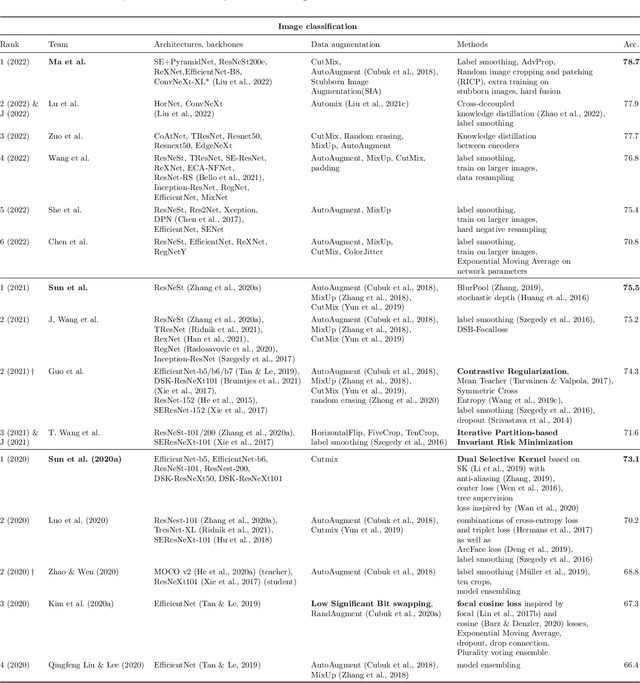
Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
Advanced Clustering Framework for Semiconductor Image Analytics Integrating Deep TDA with Self-Supervised and Transfer Learning Techniques
May 05, 2025



Semiconductor manufacturing generates vast amounts of image data, crucial for defect identification and yield optimization, yet often exceeds manual inspection capabilities. Traditional clustering techniques struggle with high-dimensional, unlabeled data, limiting their effectiveness in capturing nuanced patterns. This paper introduces an advanced clustering framework that integrates deep Topological Data Analysis (TDA) with self-supervised and transfer learning techniques, offering a novel approach to unsupervised image clustering. TDA captures intrinsic topological features, while self-supervised learning extracts meaningful representations from unlabeled data, reducing reliance on labeled datasets. Transfer learning enhances the framework's adaptability and scalability, allowing fine-tuning to new datasets without retraining from scratch. Validated on synthetic and open-source semiconductor image datasets, the framework successfully identifies clusters aligned with defect patterns and process variations. This study highlights the transformative potential of combining TDA, self-supervised learning, and transfer learning, providing a scalable solution for proactive process monitoring and quality control in semiconductor manufacturing and other domains with large-scale image datasets.
VIPriors 4: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jun 26, 2024The fourth edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop features two data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate inductive biases to improve the data efficiency of deep learning models. Significant advancements are made compared to the provided baselines, where winning solutions surpass the baselines by a considerable margin in both tasks. As in previous editions, these achievements are primarily attributed to heavy use of data augmentation policies and large model ensembles, though novel prior-based methods seem to contribute more to successful solutions compared to last year. This report highlights the key aspects of the challenges and their outcomes.
Color Equivariant Convolutional Networks
Oct 30, 2023Color is a crucial visual cue readily exploited by Convolutional Neural Networks (CNNs) for object recognition. However, CNNs struggle if there is data imbalance between color variations introduced by accidental recording conditions. Color invariance addresses this issue but does so at the cost of removing all color information, which sacrifices discriminative power. In this paper, we propose Color Equivariant Convolutions (CEConvs), a novel deep learning building block that enables shape feature sharing across the color spectrum while retaining important color information. We extend the notion of equivariance from geometric to photometric transformations by incorporating parameter sharing over hue-shifts in a neural network. We demonstrate the benefits of CEConvs in terms of downstream performance to various tasks and improved robustness to color changes, including train-test distribution shifts. Our approach can be seamlessly integrated into existing architectures, such as ResNets, and offers a promising solution for addressing color-based domain shifts in CNNs.
Benchmarking Data Efficiency and Computational Efficiency of Temporal Action Localization Models
Aug 24, 2023



In temporal action localization, given an input video, the goal is to predict which actions it contains, where they begin, and where they end. Training and testing current state-of-the-art deep learning models requires access to large amounts of data and computational power. However, gathering such data is challenging and computational resources might be limited. This work explores and measures how current deep temporal action localization models perform in settings constrained by the amount of data or computational power. We measure data efficiency by training each model on a subset of the training set. We find that TemporalMaxer outperforms other models in data-limited settings. Furthermore, we recommend TriDet when training time is limited. To test the efficiency of the models during inference, we pass videos of different lengths through each model. We find that TemporalMaxer requires the least computational resources, likely due to its simple architecture.
Using and Abusing Equivariance
Aug 22, 2023In this paper we show how Group Equivariant Convolutional Neural Networks use subsampling to learn to break equivariance to their symmetries. We focus on 2D rotations and reflections and investigate the impact of broken equivariance on network performance. We show that a change in the input dimension of a network as small as a single pixel can be enough for commonly used architectures to become approximately equivariant, rather than exactly. We investigate the impact of networks not being exactly equivariant and find that approximately equivariant networks generalise significantly worse to unseen symmetries compared to their exactly equivariant counterparts. However, when the symmetries in the training data are not identical to the symmetries of the network, we find that approximately equivariant networks are able to relax their own equivariant constraints, causing them to match or outperform exactly equivariant networks on common benchmark datasets.
VIPriors 3: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
May 31, 2023The third edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop featured four data-impaired challenges, focusing on addressing the limitations of data availability in training deep learning models for computer vision tasks. The challenges comprised of four distinct data-impaired tasks, where participants were required to train models from scratch using a reduced number of training samples. The primary objective was to encourage novel approaches that incorporate relevant inductive biases to enhance the data efficiency of deep learning models. To foster creativity and exploration, participants were strictly prohibited from utilizing pre-trained checkpoints and other transfer learning techniques. Significant advancements were made compared to the provided baselines, where winning solutions surpassed the baselines by a considerable margin in all four tasks. These achievements were primarily attributed to the effective utilization of extensive data augmentation policies, model ensembling techniques, and the implementation of data-efficient training methods, including self-supervised representation learning. This report highlights the key aspects of the challenges and their outcomes.
Copy-Pasting Coherent Depth Regions Improves Contrastive Learning for Urban-Scene Segmentation
Nov 25, 2022
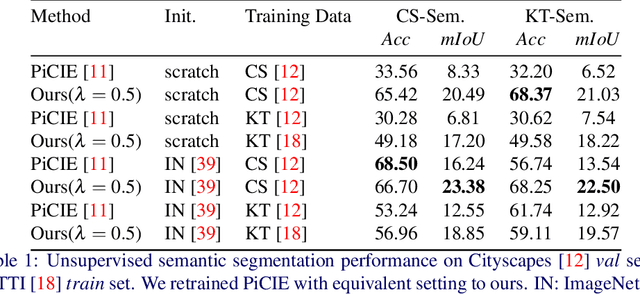
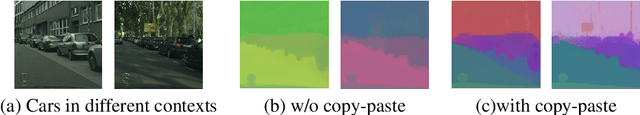
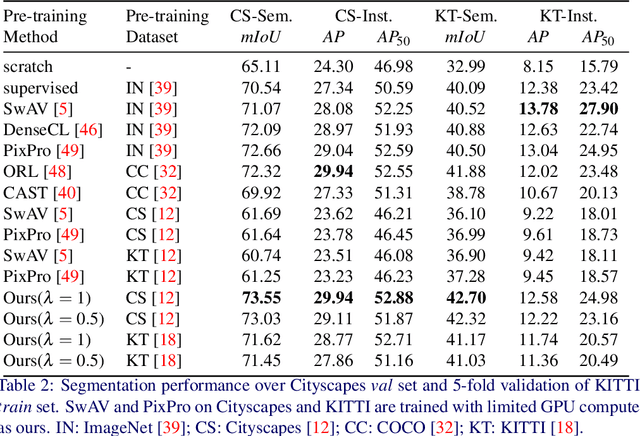
In this work, we leverage estimated depth to boost self-supervised contrastive learning for segmentation of urban scenes, where unlabeled videos are readily available for training self-supervised depth estimation. We argue that the semantics of a coherent group of pixels in 3D space is self-contained and invariant to the contexts in which they appear. We group coherent, semantically related pixels into coherent depth regions given their estimated depth and use copy-paste to synthetically vary their contexts. In this way, cross-context correspondences are built in contrastive learning and a context-invariant representation is learned. For unsupervised semantic segmentation of urban scenes, our method surpasses the previous state-of-the-art baseline by +7.14% in mIoU on Cityscapes and +6.65% on KITTI. For fine-tuning on Cityscapes and KITTI segmentation, our method is competitive with existing models, yet, we do not need to pre-train on ImageNet or COCO, and we are also more computationally efficient. Our code is available on https://github.com/LeungTsang/CPCDR
VIPriors 2: Visual Inductive Priors for Data-Efficient Deep Learning Challenges
Jan 21, 2022
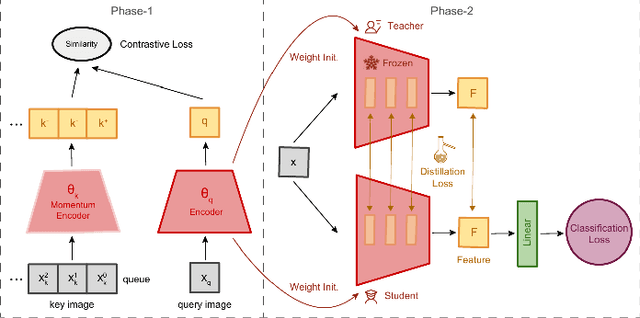

The second edition of the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" challenges featured five data-impaired challenges, where models are trained from scratch on a reduced number of training samples for various key computer vision tasks. To encourage new and creative ideas on incorporating relevant inductive biases to improve the data efficiency of deep learning models, we prohibited the use of pre-trained checkpoints and other transfer learning techniques. The provided baselines are outperformed by a large margin in all five challenges, mainly thanks to extensive data augmentation policies, model ensembling, and data efficient network architectures.
Domain Adaptation for Rare Classes Augmented with Synthetic Samples
Oct 23, 2021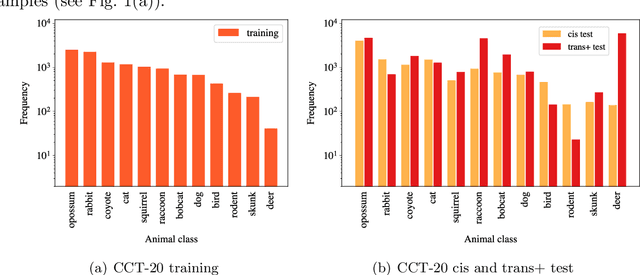

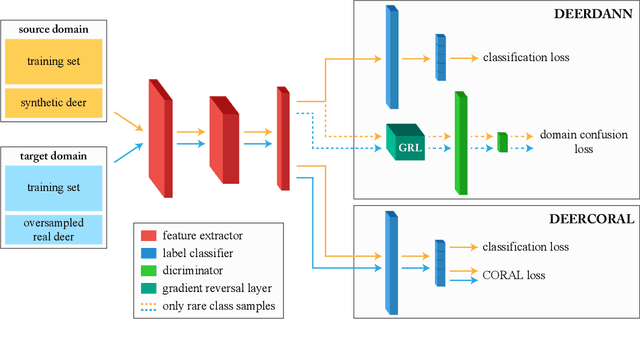
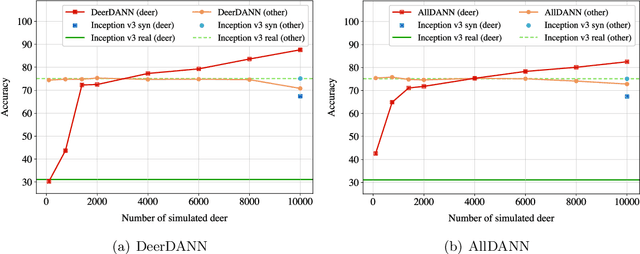
To alleviate lower classification performance on rare classes in imbalanced datasets, a possible solution is to augment the underrepresented classes with synthetic samples. Domain adaptation can be incorporated in a classifier to decrease the domain discrepancy between real and synthetic samples. While domain adaptation is generally applied on completely synthetic source domains and real target domains, we explore how domain adaptation can be applied when only a single rare class is augmented with simulated samples. As a testbed, we use a camera trap animal dataset with a rare deer class, which is augmented with synthetic deer samples. We adapt existing domain adaptation methods to two new methods for the single rare class setting: DeerDANN, based on the Domain-Adversarial Neural Network (DANN), and DeerCORAL, based on deep correlation alignment (Deep CORAL) architectures. Experiments show that DeerDANN has the highest improvement in deer classification accuracy of 24.0% versus 22.4% improvement of DeerCORAL when compared to the baseline. Further, both methods require fewer than 10k synthetic samples, as used by the baseline, to achieve these higher accuracies. DeerCORAL requires the least number of synthetic samples (2k deer), followed by DeerDANN (8k deer).