 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfSplign: Inference-Time Spatial Alignment of Text-to-Image Diffusion Models
Dec 19, 2025
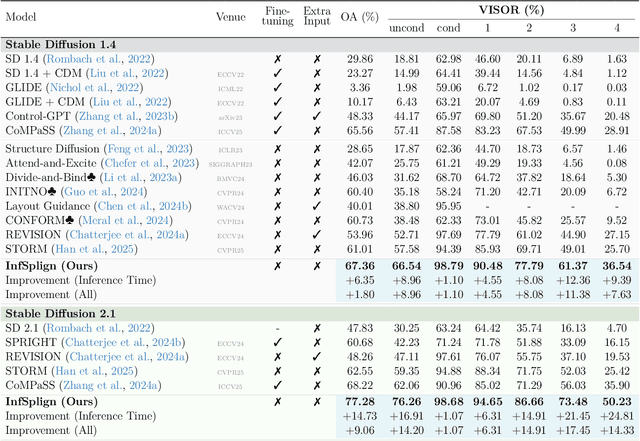
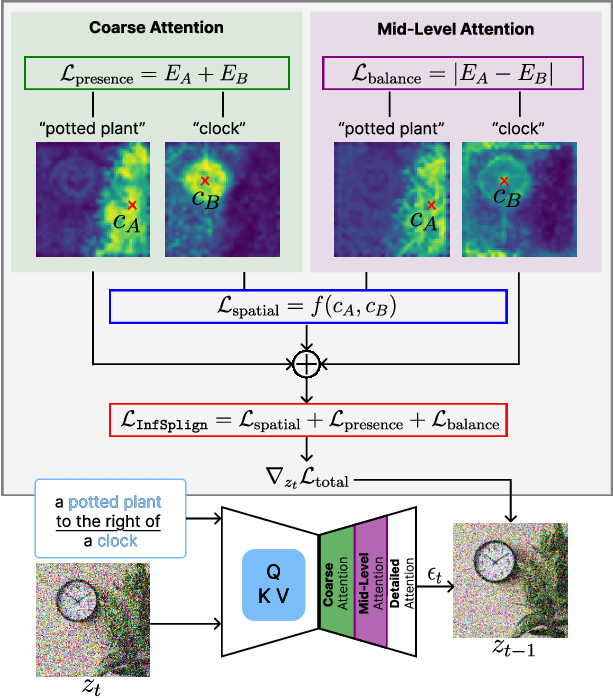
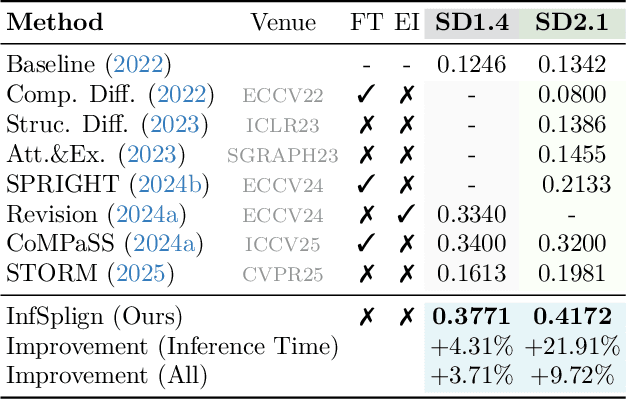
Text-to-image (T2I) diffusion models generate high-quality images but often fail to capture the spatial relations specified in text prompts. This limitation can be traced to two factors: lack of fine-grained spatial supervision in training data and inability of text embeddings to encode spatial semantics. We introduce InfSplign, a training-free inference-time method that improves spatial alignment by adjusting the noise through a compound loss in every denoising step. Proposed loss leverages different levels of cross-attention maps extracted from the backbone decoder to enforce accurate object placement and a balanced object presence during sampling. The method is lightweight, plug-and-play, and compatible with any diffusion backbone. Our comprehensive evaluations on VISOR and T2I-CompBench show that InfSplign establishes a new state-of-the-art (to the best of our knowledge), achieving substantial performance gains over the strongest existing inference-time baselines and even outperforming the fine-tuning-based methods. Codebase is available at GitHub.
Unified Control for Inference-Time Guidance of Denoising Diffusion Models
Dec 13, 2025Aligning diffusion model outputs with downstream objectives is essential for improving task-specific performance. Broadly, inference-time training-free approaches for aligning diffusion models can be categorized into two main strategies: sampling-based methods, which explore multiple candidate outputs and select those with higher reward signals, and gradient-guided methods, which use differentiable reward approximations to directly steer the generation process. In this work, we propose a universal algorithm, UniCoDe, which brings together the strengths of sampling and gradient-based guidance into a unified framework. UniCoDe integrates local gradient signals during sampling, thereby addressing the sampling inefficiency inherent in complex reward-based sampling approaches. By cohesively combining these two paradigms, UniCoDe enables more efficient sampling while offering better trade-offs between reward alignment and divergence from the diffusion unconditional prior. Empirical results demonstrate that UniCoDe remains competitive with state-of-the-art baselines across a range of tasks. The code is available at https://github.com/maurya-goyal10/UniCoDe
Graph-Aware Diffusion for Signal Generation
Oct 06, 2025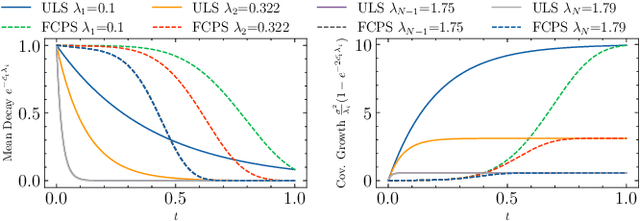
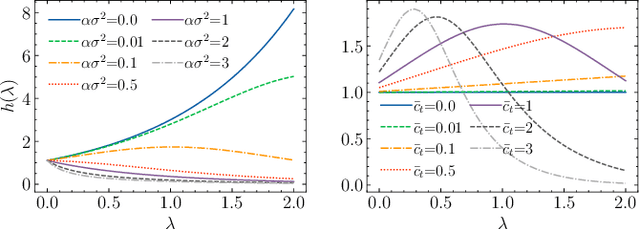
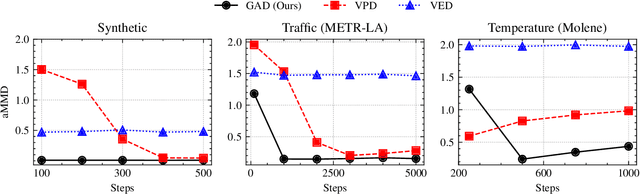
We study the problem of generating graph signals from unknown distributions defined over given graphs, relevant to domains such as recommender systems or sensor networks. Our approach builds on generative diffusion models, which are well established in vision and graph generation but remain underexplored for graph signals. Existing methods lack generality, either ignoring the graph structure in the forward process or designing graph-aware mechanisms tailored to specific domains. We adopt a forward process that incorporates the graph through the heat equation. Rather than relying on the standard formulation, we consider a time-warped coefficient to mitigate the exponential decay of the drift term, yielding a graph-aware generative diffusion model (GAD). We analyze its forward dynamics, proving convergence to a Gaussian Markov random field with covariance parametrized by the graph Laplacian, and interpret the backward dynamics as a sequence of graph-signal denoising problems. Finally, we demonstrate the advantages of GAD on synthetic data, real traffic speed measurements, and a temperature sensor network.
Data-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025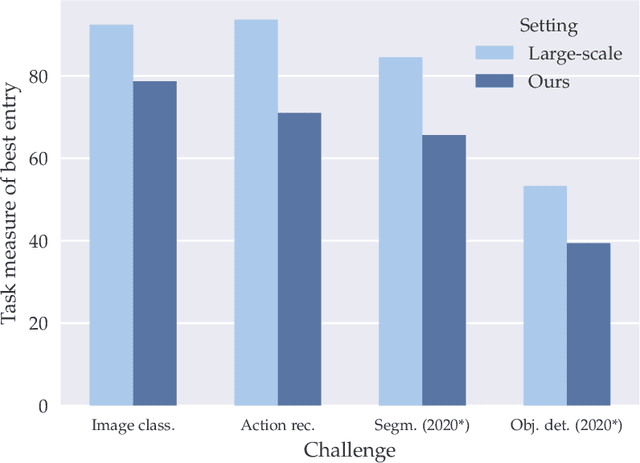
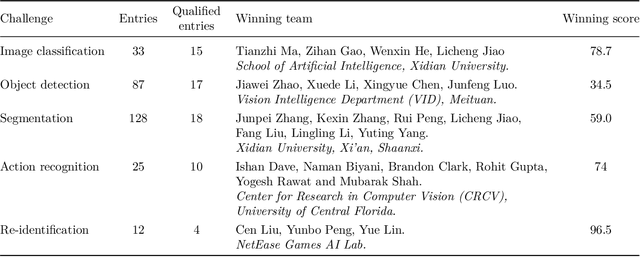

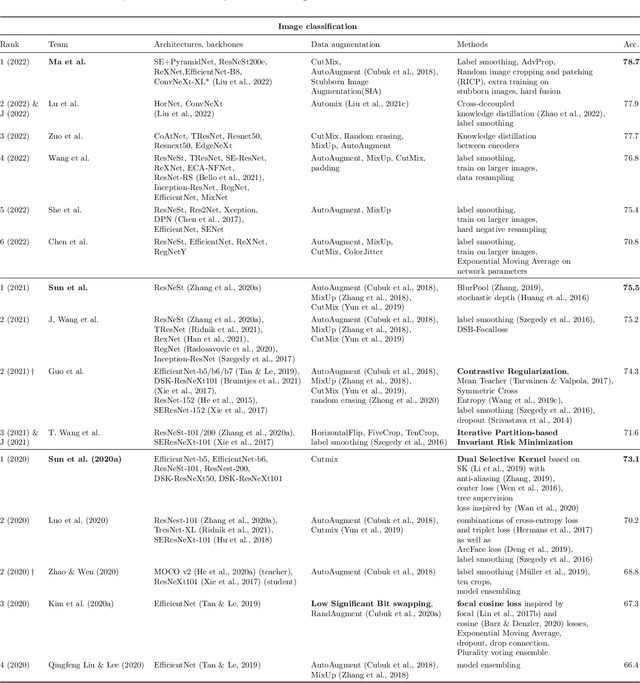
Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
CoDe: Blockwise Control for Denoising Diffusion Models
Feb 03, 2025Aligning diffusion models to downstream tasks often requires finetuning new models or gradient-based guidance at inference time to enable sampling from the reward-tilted posterior. In this work, we explore a simple inference-time gradient-free guidance approach, called controlled denoising (CoDe), that circumvents the need for differentiable guidance functions and model finetuning. CoDe is a blockwise sampling method applied during intermediate denoising steps, allowing for alignment with downstream rewards. Our experiments demonstrate that, despite its simplicity, CoDe offers a favorable trade-off between reward alignment, prompt instruction following, and inference cost, achieving a competitive performance against the state-of-the-art baselines. Our code is available at: https://github.com/anujinho/code.
MAGMA: Manifold Regularization for MAEs
Dec 03, 2024Masked Autoencoders (MAEs) are an important divide in self-supervised learning (SSL) due to their independence from augmentation techniques for generating positive (and/or negative) pairs as in contrastive frameworks. Their masking and reconstruction strategy also nicely aligns with SSL approaches in natural language processing. Most MAEs are built upon Transformer-based architectures where visual features are not regularized as opposed to their convolutional neural network (CNN) based counterparts, which can potentially hinder their performance. To address this, we introduce MAGMA, a novel batch-wide layer-wise regularization loss applied to representations of different Transformer layers. We demonstrate that by plugging in the proposed regularization loss, one can significantly improve the performance of MAE-based models. We further demonstrate the impact of the proposed loss on optimizing other generic SSL approaches (such as VICReg and SimCLR), broadening the impact of the proposed approach. Our code base can be found at https://github.com/adondera/magma.
MAPL: Model Agnostic Peer-to-peer Learning
Mar 28, 2024



Effective collaboration among heterogeneous clients in a decentralized setting is a rather unexplored avenue in the literature. To structurally address this, we introduce Model Agnostic Peer-to-peer Learning (coined as MAPL) a novel approach to simultaneously learn heterogeneous personalized models as well as a collaboration graph through peer-to-peer communication among neighboring clients. MAPL is comprised of two main modules: (i) local-level Personalized Model Learning (PML), leveraging a combination of intra- and inter-client contrastive losses; (ii) network-wide decentralized Collaborative Graph Learning (CGL) dynamically refining collaboration weights in a privacy-preserving manner based on local task similarities. Our extensive experimentation demonstrates the efficacy of MAPL and its competitive (or, in most cases, superior) performance compared to its centralized model-agnostic counterparts, without relying on any central server. Our code is available and can be accessed here: https://github.com/SayakMukherjee/MAPL
BECLR: Batch Enhanced Contrastive Few-Shot Learning
Feb 04, 2024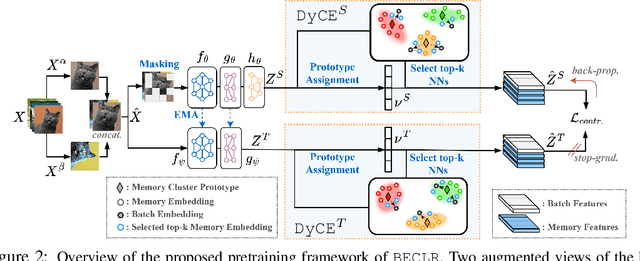
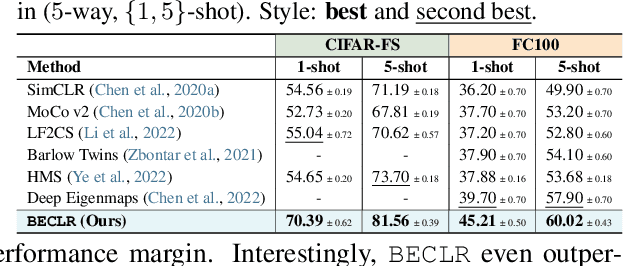
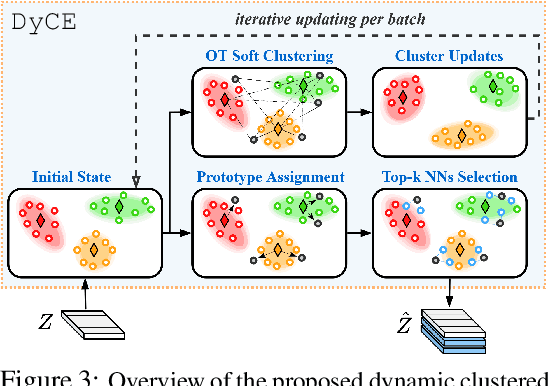
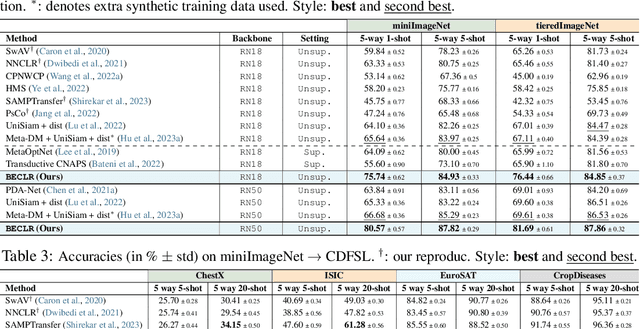
Learning quickly from very few labeled samples is a fundamental attribute that separates machines and humans in the era of deep representation learning. Unsupervised few-shot learning (U-FSL) aspires to bridge this gap by discarding the reliance on annotations at training time. Intrigued by the success of contrastive learning approaches in the realm of U-FSL, we structurally approach their shortcomings in both pretraining and downstream inference stages. We propose a novel Dynamic Clustered mEmory (DyCE) module to promote a highly separable latent representation space for enhancing positive sampling at the pretraining phase and infusing implicit class-level insights into unsupervised contrastive learning. We then tackle the, somehow overlooked yet critical, issue of sample bias at the few-shot inference stage. We propose an iterative Optimal Transport-based distribution Alignment (OpTA) strategy and demonstrate that it efficiently addresses the problem, especially in low-shot scenarios where FSL approaches suffer the most from sample bias. We later on discuss that DyCE and OpTA are two intertwined pieces of a novel end-to-end approach (we coin as BECLR), constructively magnifying each other's impact. We then present a suite of extensive quantitative and qualitative experimentation to corroborate that BECLR sets a new state-of-the-art across ALL existing U-FSL benchmarks (to the best of our knowledge), and significantly outperforms the best of the current baselines (codebase available at: https://github.com/stypoumic/BECLR).
GeNIe: Generative Hard Negative Images Through Diffusion
Dec 05, 2023



Data augmentation is crucial in training deep models, preventing them from overfitting to limited data. Common data augmentation methods are effective, but recent advancements in generative AI, such as diffusion models for image generation, enable more sophisticated augmentation techniques that produce data resembling natural images. We recognize that augmented samples closer to the ideal decision boundary of a classifier are particularly effective and efficient in guiding the learning process. We introduce GeNIe which leverages a diffusion model conditioned on a text prompt to merge contrasting data points (an image from the source category and a text prompt from the target category) to generate challenging samples for the target category. Inspired by recent image editing methods, we limit the number of diffusion iterations and the amount of noise. This ensures that the generated image retains low-level and contextual features from the source image, potentially conflicting with the target category. Our extensive experiments, in few-shot and also long-tail distribution settings, demonstrate the effectiveness of our novel augmentation method, especially benefiting categories with a limited number of examples.
LAB: Learnable Activation Binarizer for Binary Neural Networks
Oct 25, 2022

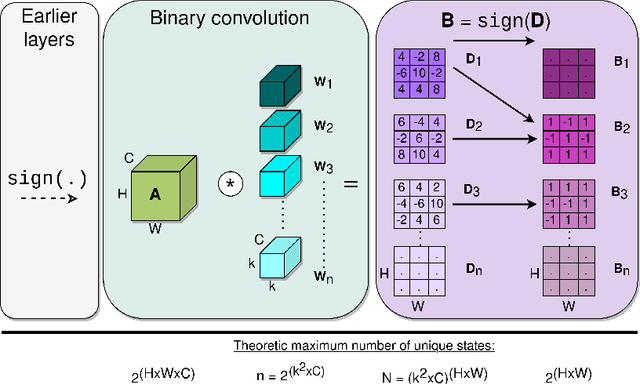
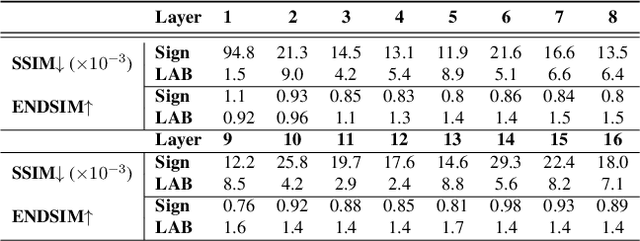
Binary Neural Networks (BNNs) are receiving an upsurge of attention for bringing power-hungry deep learning towards edge devices. The traditional wisdom in this space is to employ sign() for binarizing featuremaps. We argue and illustrate that sign() is a uniqueness bottleneck, limiting information propagation throughout the network. To alleviate this, we propose to dispense sign(), replacing it with a learnable activation binarizer (LAB), allowing the network to learn a fine-grained binarization kernel per layer - as opposed to global thresholding. LAB is a novel universal module that can seamlessly be integrated into existing architectures. To confirm this, we plug it into four seminal BNNs and show a considerable performance boost at the cost of tolerable increase in delay and complexity. Finally, we build an end-to-end BNN (coined as LAB-BNN) around LAB, and demonstrate that it achieves competitive performance on par with the state-of-the-art on ImageNet.