 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfSplign: Inference-Time Spatial Alignment of Text-to-Image Diffusion Models
Dec 19, 2025
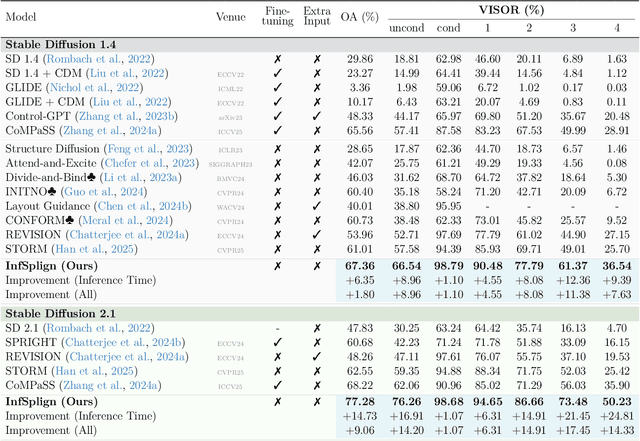
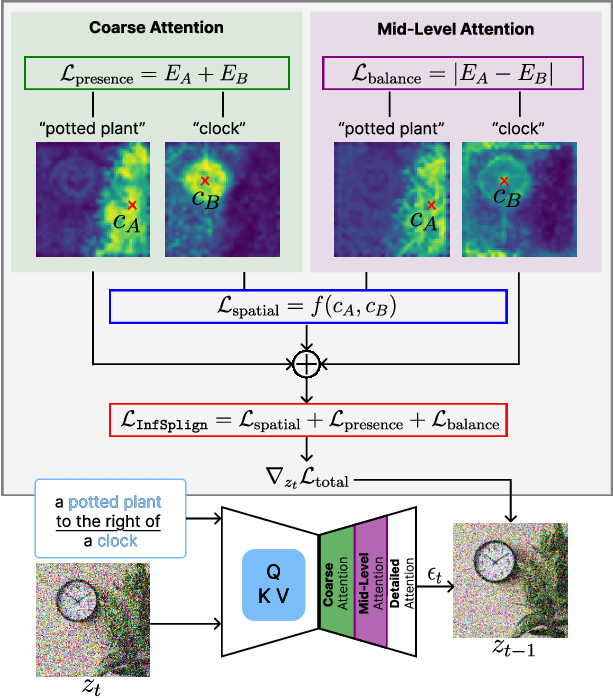
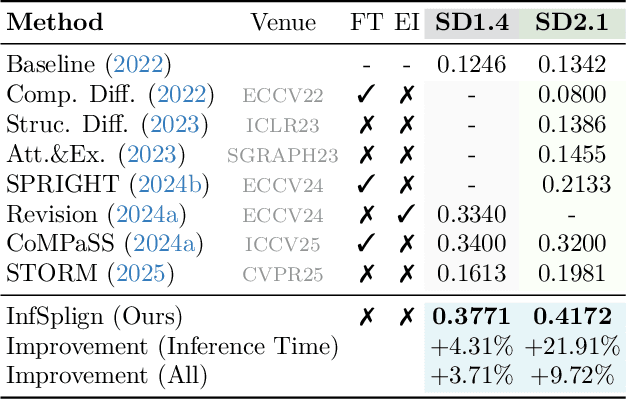
Text-to-image (T2I) diffusion models generate high-quality images but often fail to capture the spatial relations specified in text prompts. This limitation can be traced to two factors: lack of fine-grained spatial supervision in training data and inability of text embeddings to encode spatial semantics. We introduce InfSplign, a training-free inference-time method that improves spatial alignment by adjusting the noise through a compound loss in every denoising step. Proposed loss leverages different levels of cross-attention maps extracted from the backbone decoder to enforce accurate object placement and a balanced object presence during sampling. The method is lightweight, plug-and-play, and compatible with any diffusion backbone. Our comprehensive evaluations on VISOR and T2I-CompBench show that InfSplign establishes a new state-of-the-art (to the best of our knowledge), achieving substantial performance gains over the strongest existing inference-time baselines and even outperforming the fine-tuning-based methods. Codebase is available at GitHub.
LAB: Learnable Activation Binarizer for Binary Neural Networks
Oct 25, 2022Binary Neural Networks (BNNs) are receiving an upsurge of attention for bringing power-hungry deep learning towards edge devices. The traditional wisdom in this space is to employ sign() for binarizing featuremaps. We argue and illustrate that sign() is a uniqueness bottleneck, limiting information propagation throughout the network. To alleviate this, we propose to dispense sign(), replacing it with a learnable activation binarizer (LAB), allowing the network to learn a fine-grained binarization kernel per layer - as opposed to global thresholding. LAB is a novel universal module that can seamlessly be integrated into existing architectures. To confirm this, we plug it into four seminal BNNs and show a considerable performance boost at the cost of tolerable increase in delay and complexity. Finally, we build an end-to-end BNN (coined as LAB-BNN) around LAB, and demonstrate that it achieves competitive performance on par with the state-of-the-art on ImageNet.