 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfSplign: Inference-Time Spatial Alignment of Text-to-Image Diffusion Models
Dec 19, 2025
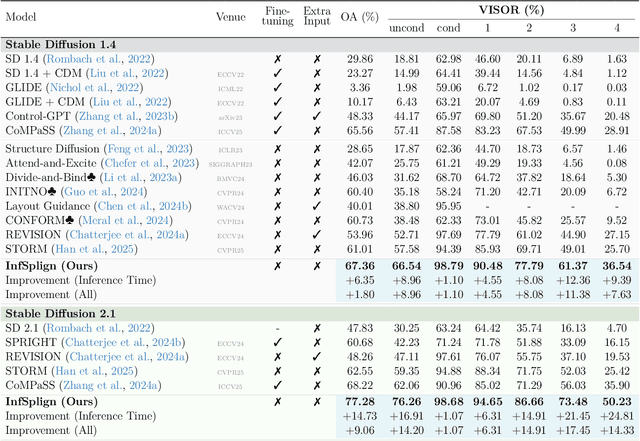
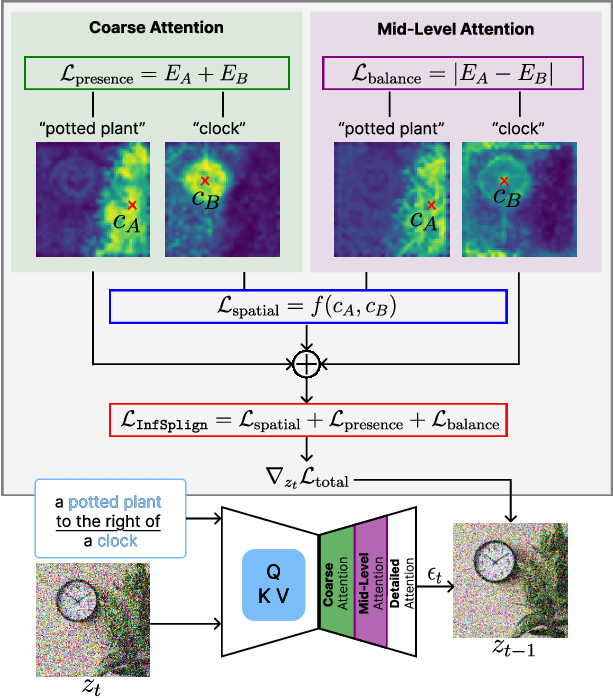
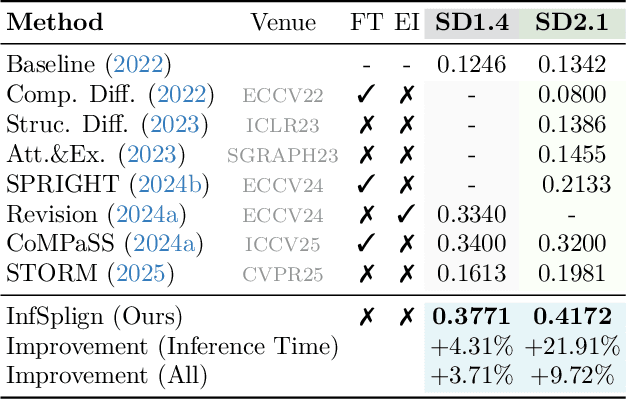
Text-to-image (T2I) diffusion models generate high-quality images but often fail to capture the spatial relations specified in text prompts. This limitation can be traced to two factors: lack of fine-grained spatial supervision in training data and inability of text embeddings to encode spatial semantics. We introduce InfSplign, a training-free inference-time method that improves spatial alignment by adjusting the noise through a compound loss in every denoising step. Proposed loss leverages different levels of cross-attention maps extracted from the backbone decoder to enforce accurate object placement and a balanced object presence during sampling. The method is lightweight, plug-and-play, and compatible with any diffusion backbone. Our comprehensive evaluations on VISOR and T2I-CompBench show that InfSplign establishes a new state-of-the-art (to the best of our knowledge), achieving substantial performance gains over the strongest existing inference-time baselines and even outperforming the fine-tuning-based methods. Codebase is available at GitHub.
SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery
Aug 26, 2024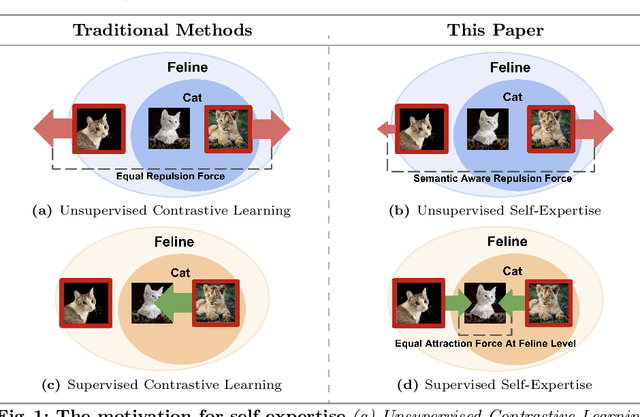
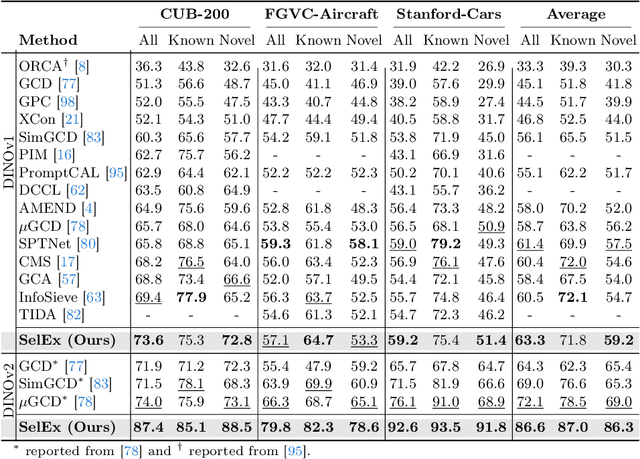

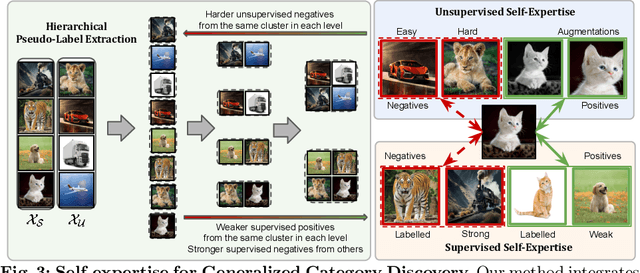
In this paper, we address Generalized Category Discovery, aiming to simultaneously uncover novel categories and accurately classify known ones. Traditional methods, which lean heavily on self-supervision and contrastive learning, often fall short when distinguishing between fine-grained categories. To address this, we introduce a novel concept called `self-expertise', which enhances the model's ability to recognize subtle differences and uncover unknown categories. Our approach combines unsupervised and supervised self-expertise strategies to refine the model's discernment and generalization. Initially, hierarchical pseudo-labeling is used to provide `soft supervision', improving the effectiveness of self-expertise. Our supervised technique differs from traditional methods by utilizing more abstract positive and negative samples, aiding in the formation of clusters that can generalize to novel categories. Meanwhile, our unsupervised strategy encourages the model to sharpen its category distinctions by considering within-category examples as `hard' negatives. Supported by theoretical insights, our empirical results showcase that our method outperforms existing state-of-the-art techniques in Generalized Category Discovery across several fine-grained datasets. Our code is available at: https://github.com/SarahRastegar/SelEx.
Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery
Nov 06, 2023In the quest for unveiling novel categories at test time, we confront the inherent limitations of traditional supervised recognition models that are restricted by a predefined category set. While strides have been made in the realms of self-supervised and open-world learning towards test-time category discovery, a crucial yet often overlooked question persists: what exactly delineates a category? In this paper, we conceptualize a category through the lens of optimization, viewing it as an optimal solution to a well-defined problem. Harnessing this unique conceptualization, we propose a novel, efficient and self-supervised method capable of discovering previously unknown categories at test time. A salient feature of our approach is the assignment of minimum length category codes to individual data instances, which encapsulates the implicit category hierarchy prevalent in real-world datasets. This mechanism affords us enhanced control over category granularity, thereby equipping our model to handle fine-grained categories adeptly. Experimental evaluations, bolstered by state-of-the-art benchmark comparisons, testify to the efficacy of our solution in managing unknown categories at test time. Furthermore, we fortify our proposition with a theoretical foundation, providing proof of its optimality. Our code is available at https://github.com/SarahRastegar/InfoSieve.